基于深度Q网络的近距空战智能机动决策研究
作者: 张婷玉 孙明玮 王永帅 陈增强
摘 要:针对近距空战对抗中无人机机动决策问题, 本文基于深度Q网络(DQN)算法的框架, 对强化学习奖励函数设计以及超参数的选择问题进行了研究。 对于强化学习中的稀疏奖励问题, 采用综合角度、 距离、 高度和速度等空战因素的辅助奖励, 能够精确描述空战任务, 正确引导智能体的学习方向。 同时, 针对应用强化学习超参数选择问题, 探究了学习率、 网络节点数和网络层数对决策系统的影响, 并给出较好的参数选择范围, 为后续研究参数选择提供参考。 空战场景的仿真结果表明, 通过训练智能体能够在不同空战态势下学习到较优的机动策略, 但对强化学习超参数较敏感。
关键词:空战; 自主机动决策; 深度强化学习; DQN; 奖励函数; 智能机动; 参数选择
中图分类号: TJ76; V212.13文献标识码:A文章编号: 1673-5048(2023)03-0041-08
DOI: 10.12132/ISSN.1673-5048.2022.0251
0 引言
伴随着现代战争的信息化和智能化, 空战战场上使用无人机的趋势日益明显, 无人作战飞机(Unmanned Combat Aerial Vehicle, UCAV)逐渐成为未来空战的主力武器[1-2]。 目前UCAV大多采用地面人员遥控的作战模式, 很难适用于复杂多变的空战环境。 因此, 提升UCAV的智能化水平是打赢未来空战的军事需求[3]。 飞行器自主机动决策技术是提高空战自主能力与智能化水平的关键技术, 能够准确感知空战环境并生成合理机动决策的自主机动决策方法是各国军事技术的研究重点[4]。
现有的空战决策方法分为两类: 一类是非学习策略, 另外一类是自学习策略。 非学习策略的求解过程主要采用优化理论, 包括专家系统[5-6]、 微分对策[7-8]、 矩阵博弈[9-10]等方法。 而自学习空战决策方法的核心是用智能算法对空战决策过程建模, 并根据训练产生的经验对决策模型参数进行优化。 典型的自学习策略算法包括遗传算法[11]、 动态规划算法[12]和强化学习算法等。 丁林静等人采用动态模糊Q学习模型, 提出了基于强化学习的无人机空战机动决策方法[13], 但由于空战问题的复杂性, 使传统强化学习算法无法解决连续状态空间问题, 会存在维度限制问题。
近年来, 深度强化学习在多种决策问题中均有一定突破, 为解决空战对抗中飞行器机动决策问题提供了新思路。 目前, 深度强化学习在空战对抗中的运用主要有基于值函数的Q学习方法和基于策略搜索的Actor-Critic方法。 张强等人提出一种基于Q-network强化学习的超视距空战机动决策方法[14]。 Zhang等应用DQN(Deep Q-Network)算法研究了二维平面的空战机动决策问题, 针对DQN算法初始随机探索效率低的缺点, 提出利用专家知识提高探索效率, 加快训练时间[15]。 Yang等基于DDPG(Deep Deterministic Policy Gradient)算法构建空战决策系统, 针对DDPG算法缺少空战先验知识、 导致数据利用率低的问题, 提出向经验池加入已有机动决策系统的样本数据, 加快算法收敛速度[16]。 吴宜珈等通过改进PPO(Proximal Policy Optimization)算法, 优化策略选择过程, 提高决策效率[17]。 上述文献主要关注对深度强化学习算法的改进, 对于适用于一对一空战的奖励函数以及强化学习超参数选择问题没有过多研究。 在深度强化学习方法应用过程中, 超参数的整定以及超参数的调整是否会带来性能的影响, 是一个值得研究的问题。
本文针对三维空间中无人机一对一近距对抗问题开展研究, 采用强化学习框架对空战问题进行建模; 针对强化学习的稀疏奖励问题, 考虑加入能够准确描述空战任务的辅助奖励, 设计一对一空战的机动决策奖励, 提出了基于DQN算法的自主机动决策方法; 针对深度强化学习超参数选取问题, 探究超参数对决策系统的影响, 并设置空战场景进行仿真, 验证机动决策方法的有效性。
1 空战机动决策问题描述及建模
1.1 近距空战问题描述
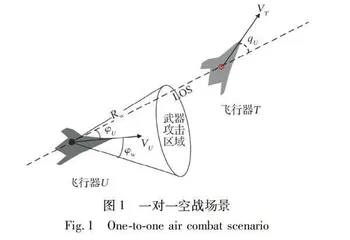
空战问题可用OODA环描述, 即完成空战的观察(Observe)、 判断(Orient)、 决策(Decide)和执行(Action)回路(简称OODA回路)。 结合OODA回路描述, 自主空战被定义为在瞬息万变的复杂战场环境中感知并认知战场态势和目标意图, 对武器和机动动作快速做出最优的决策策略, 并控制飞机精确执行机动指令。 空战决策是自主空战的核心。 本文所研究的空战场景为近距一对一空战, 如图1所示。
一对一空战机动决策的目的是在双方交战过程中, 使我方尽量处于空战态势的优势地位, 即尽可能让敌方进入我方的武器攻击区域, 同时避免自身落入敌方的武器攻击区域。 典型的武器攻击区域是攻击机的前方一定距离和角度的锥形范围。
1.2 UCAV运动学模型
飞行器的运动学模型是空战机动决策模型的基础, 本文研究的重点是机动策略, 不考虑姿态等, 故将飞行器看作三维空间中的一个质点, 采用三自由度质点模型。
基于动力学基本定理, 飞行器在惯性坐标系下的三自由度质点运动模型为[18]
式中: v为飞行器的速度; x, y, z为飞行器质心在惯性坐标系中的坐标值; γ, ψ, μ为飞行器的俯仰角、 航向角和滚转角; nx为切向过载, 表示飞行器在速度方向上受到的推力与自身重力的比值; nz为法向过载, 提供飞行器所需的升力[18]。 本文所选取飞行器机动模型的控制量为nx, nz, μ。
2 基于DQN的机动决策方法
2.1 系统框架
深度Q网络(Deep Q-Network, DQN)是将传统强化学习方法Q-learning与深度神经网络相结合的一种算法。 DQN用深度神经网络代替Q表, 解决了Q表存储限制问题; 引入目标网络来计算目标Q值, 采用暂时参数冻结的方法切断Q网络更新时的相关性, 有效避免了Q估计值不收敛的问题。 DQN算法的框架如图2所示。
空战格斗的机动决策是一个序贯决策过程, 强化学习正是一种求解序贯决策问题的优化方法,故将机动决策问题建模为连续状态空间和离散动作空间的强化学习问题。 强化学习算法为无人机进行动作选择, 我机与目标机的状态形成空战环境的描述, 当前空战态势的评估结果返回强化学习算法中。 决策系统的框架如图3所示。
2.2 UCAV的强化学习环境构建
2.2.1 状态空间
本文选择空战态势信息作为状态变量, 它将为无人作战飞机机动决策提供必要的信息支撑。 空战态势信息的几何关系如图4所示。
状态变量包括我机与目标机距离R、 我机与目标机的距离变化率R·、 我机方位角φU、 我机进入角qU、 两机的速度方向的夹角χ、 两机的飞行高度差Δh以及两机的飞行速度差Δv。 除态势信息外, 还引入我机的当前飞行高度zU和飞行速度vU作为状态变量。 因此, 本文设计的系统状态空间向量为
2.2.2 动作空间
飞行器的机动过程可视作一些基本机动动作的组合[19], 因此本文选择由美国NASA提出的“基本机动动作库”作为动作空间[20], 其包括7个基本操纵方式: 定常飞行、 加速、 减速、 左转、 右转、 向上拉起和向下俯冲。 飞行器可通过连续多步的基本动作选择,从而组合出不同战术动作。
飞行器机动动作的控制量为切向过载nx、 法向过载nz和滚转角μ, 考虑飞行器结构特性对过载的限制, 本文切向过载的取值范围为nx∈[-2,2], 法向过载的取值范围为nz∈[-4,4], 滚转角的取值范围为μ∈[-π/3, π/3][21]。 实际每次执行机动动作过程中均采用最大过载, 机动动作所对应的控制指令如表1所示[21]。
2.2.3 奖励函数
忽略武器攻击误差等因素, 设定当两机距离R小于武器攻击范围Rw, 方位角小于武器最大攻击角度φw且进入角小于qw时达到目标状态, 可获得最终奖励rfinal:
为了避免飞行器在飞行过程中失速、 飞行过低或过高、 远离目标或与目标发生碰撞, 本文设置来自于环境的惩罚函数re:
综合建立的强化学习环境、 神经网络结构及探索策略, 本文提出基于深度Q学习的机动决策算法, 算法1描述了基于深度Q学习的机动决策算法过程。
算法1: 基于深度Q学习的飞行器机动决策过程。
输入: 状态空间S, 动作空间A, 初始神经网络, 训练参数。
输出: Q网络参数。
1: 初始化经验回放缓冲区D, 容量为N。
2: 初始化在线Q网络及随机权重θ。
3: 初始化目标Q网络, θ-=θ。
4: 初始化ε=1。
5: for episode = 1, 2, do:
6: 初始化状态双方飞行器的状态, 获取当前态势。
7: if episode为N的倍数then。
8: 进行评估, 评估时ε=0。
9: end if
10: for step = 1, 2, …, T do。
11: 以ε的概率从7个基本动作中随机选择一个动作, 否则, 选
择动作at=argmaxaQ(st, a, θ)。
12: 执行动作at, 得到奖励rt, 进入下一状态st+1。
13: 将[st, at, rt, st+1]存储到D中; 判断该空战回合是否结
束。
14: end for
15: 从D中随机抽取一批样本[sj, aj, rj, sj+1]。
16: 定义amax=argmaxa′Q(sj+1, a′, θ)。
17: 令yj=rj, 达到目标状态rj+γQ(sj+1, aj, θ-), 未达目标状态
18: 根据目标函数(yj-Q(sj, aj, θ-))2, 使用梯度下降法更新
权重θ。
19: 每隔C轮, 更新目标Q网络, θ-←θ。
20: 逐步减小ε的值, 直至εmin。
21: end for
3 仿真与分析
3.1 强化学习超参数探究
在目标飞行器进行匀速直线运动且双方初始相向飞行的场景下, 探究强化学习超参数对机动决策的影响。
3.1.1 学习率
学习率决定目标函数能否收敛以及何时收敛。 本文在网络结构不变且三个隐藏层均为64个节点的情况下, 探究学习率对机动决策系统的影响。 由于计算机性能限制, 训练耗费时间较长, 仅选择三组对照, 所设置的三个实验组的学习率分别是0.01、 0.001以及0.000 1。
各学习率学习曲线如图7所示, 横坐标为训练次数, 纵坐标为用30回合计算平均值进行平滑后的累计奖励值。 结果表明, 学习曲线整体均呈上升趋势, 学习率影响收敛速度。 当α=0.01时, 在训练次数大于700次后奖励值下降成为负值; 当α=0.000 1时, 未出现收敛趋势, 且奖
励值为负值, 说明智能体尚未探索出较好的机动策略; 当α=0.001时, 奖励值随训练次数增加逐步提高, 且有收敛趋势。 可见, 学习率过低会延长训练时间, 学习率过高可能会达到局部最优结果或发散。 因此, 针对飞行器机动决策问题, 学习率设置为0.001较为合理。