时敏目标的类型与瞄准点识别算法
作者: 吴晗 张志龙 李楚为 李航宇
摘 要: 深度卷积神经网络模型在很多计算机视觉应用中取得了非常出色的结果,如何利用深度学习技术完成复杂战场环境下的辅助制导和瞄准点定位,是我军赢得现代信息化战争的关键。针对该问题,本文提出了一种时敏目标的类型与瞄准点识别算法,用于改善对时敏目标检测的质量,并为后续模块提供作战军事资源各个部件的打击价值。该算法对YOLOv3主干网络进行重新设计,使用深度可分离卷积神经网络的残差块对输入图像进行特征提取,然后将得到的特征图送入注意力模型,为含有目标部件等重要语义信息的特征图赋予相应的权值,最后将经注意力机制模型处理后的特征图送入回归网络进行时敏目标的类型与瞄准点识别。在COCO与VOC数据集上的实验结果表明,本文算法使用的特征提取网络与注意力模型有效提升了深度卷积神经网络对常见目标的检测精度(mAP); 在所建立的战场军事资源模型数据集上的实验结果表明,本文算法可实现对非合作时敏目标的瞄准点精准识别。
关键词: 时敏目标; 目标检测; 瞄准点识别; 深度学习; 注意力模型; YOLOv3; 神经网络
中图分类号: TJ760; TN957.51
文献标识码: A
文章编号: 1673-5048(2022)02-0024-06
DOI: 10.12132/ISSN.1673-5048.2020.0260
0 引 言
战场目标是指复杂战场环境下需要打击的作战对象,特指在一定的时间与空间范围内存在,具有重要战略、战役或战术价值的实体目标。时敏目标是指必须在有限的攻击窗口内发现、定位、识别和瞄准的目标。时敏目标瞄准点选择是指依据我方作战目的、武器装备性能及所获取的战场情报资料,在战时国际法的框架约束内,对战场时敏目标进行检测、分析、评估、排序后,从中选出重点打击目标的过程。
随着人工智能技术的兴起,大量具有一定自主意识的人工智能载体被投入到复杂战场环境中辅助作战,人们希望研究智能化程度较高的目标检测识别算法,准确智能地从人工智能侦察设备摄取的序列图像中发现各类移动目标,并输出提示或告警信息,以缓解操作员的心理负担。
时敏目标的瞄准点识别过程实质为目标检测任务中的部件识别过程。在现代信息化战争中,战场局势瞬息万变,不同的战术作战军事资源的各个部件具有不同的打击价值,如何有效地进行时敏目标的瞄准点识别是锁定并制导摧毁目标的关键步骤。
目标检测是计算机视觉领域中一个重要的研究方向,不同于图像分类与语义分割任务,目标检测任务既需要识别复杂背景下的目标类别,也需要回归目标边界框位置信息。传统意义上的目标检测算法主要分为两类: 基于目标结构知识的启发式方法与基于特征的方法。
启发式方法是根据目标的结构知识提出的,往往针对目标的一些特殊结构,采取滤波的方法,进行相应的特征提取。提取的特征包括直线特征、点特征和特殊结构特征等。例如,在飞机检测方面,利用飞机结构知识建立的圆周频率滤波算法[1]和数学形态学滤波算法来进行飞机检测; 在舰船检测方面,通过分析线段的空间关系检测港内舰船[2], 通过尾迹检测舰船,基于形状上下文检测舰船[3]; 在车辆检测方面,利用运动信息检测图像中的运动目标[4]等。
基于特征的目标检测算法是通过在空域或变换域中提取特征来描述图像,以达到对目标检测识别的目的。常见的空域特征应用包括: HOG特征用于行人检测[5]; Haar-like特征用于物体检测和实时的人脸检测[6]; SIFT特征用于描述机场,并用一种特征点匹配的方法进行目标检测[7]等。常见的变换域方法包括: Ridgelet变换、小波变换、Gabor变换等,Ridgelet变换检测道路边缘,离散小波变换在SAR图像中检测舰船等。虽然传统意义上的目标检测算法可在计算资源占用较小的情况下实现检测识别,但在复杂背景条件下,其整体识别率不高、泛化能力不强且鲁棒性较弱[8]。
在2012年的ImageNet竞赛中,AlexNet[9]算法在图像分类领域取得了质的飞跃,其将一千类图像的分类正确率提升至84.7%。自此,深度学习(Deep Learning)就开始被广泛地应用于目标检测识别任务。无论是以Faster R-CNN[10]和Mask R-CNN[11]为代表的双阶段目标检测算法,还是以SSD[12]和YOLO[13]为代表的单阶段目标检测算法,都在大规模目标检测数据集上取得了优秀的识别性能。针对单/双阶段目标检测算法的检测速率与精度平衡问题,Tian等提出的FCOS算法[14]采用语义分割的思想来实现目标检测任务,其基于Anchor-free的策略能在节省大量计算资源的情况下获得较高的目标检测识别率。
深度学习中的注意力机制借鉴了人脑系统处理大量冗余信息的视觉注意力思维方式[15],即视觉信息处理过程中着重关注包含信息量最为丰富的区域,抑制次要区域信息对整体的影响。Hu等的SE模型[16]通过对深度网络提取的特征图进行压缩与释放操作,使得深度模型给予高响应通道特征更大权值。Woo等的CBAM模型[17]通过对深度网络提取的特征图进行池化与并行编码,使得特征图中对应语义信息丰富的区域得到更高程度的响应,这种策略让网络模型可在额外占用一定计算资源的情况下,提高目标检测的识别精度。
本文提出了一种时敏目标的类型与瞄准点识别算法。该算法对YOLOv3主干网络进行重新设计,使用深度可分离卷积神经网络的残差块对输入图像进行特征提取,然后将得到的特征图送入注意力模型,其对含有目标部件等重要语义信息的特征图赋予相应的权值,最后将经注意力模型处理后的特征图送入回归网络进行时敏目标的类型与瞄准点识别。经注意力机制处理后的深度模型可更加关注输入图像中包含目标部件等重要语义信息的区域,从而可实现高精度、鲁棒性强的时敏目标瞄准点识别。
1 相关工作
瞄准点识别的过程实质是目标的部件识别过程。目前主流的部件识别算法仍是将目标部件作为一种目标类型,经过标注、训练等强监督学习步骤后,分类与回归出目标的类型与边界框信息。虽然这类方法可在一定程度上取得较好的部件检测性能,但仍陷入了单/双阶段目标检测算法的检测速率与精度平衡问题,且由于没有利用特征图中目标各个部件的上下文信息,其检测精度有待进一步提升。
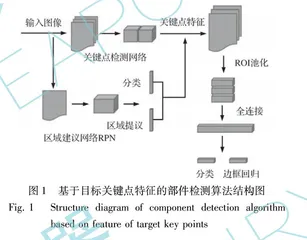
针对上述算法的问题,有学者提出了基于目标关键点特征的部件检测算法[18-19],其利用目标部件之间的相互位置关系来提升目标部件的识别性能。如图1所示,这类算法首先将目标部件视为关键点特征,并且利用级联深度卷积神经网络,实现包含丰富语义信息的目标关键位置检测,然后利用这些关键位置定位结果来优化Faster R-CNN候选框筛选机制和输出策略,从而降低了目标检测模型的网络复杂度,实现较高精度的部件检测性能。这类算法虽然可以实现较高鲁棒性的目标检测,但是,其并未有效降低算法所需的计算资源,而由于Faster R-CNN算法检测速度过于缓慢,更难以满足复杂战场环境下嵌入式设备部署所需求的高效性与实时性。
在保证目标检测精度的基础上,尽可能地提升时敏目标瞄准点检测识别的速率,本文提出了一种基于注意力机制的部件识别算法,通过对含有目标部件等重要语义信息的特征图赋予相应的权值,网络最终的输出会更多地受到输入图像中目标部件的影响。由于特征提取网络与回归网络处于一个端到端的模型之中,并且所使用的通道注意力机制可在不占用额外计算资源的情况下自学习特征响应,因此,本文算法可以在高算力设备支持下实现实时目标检测。
2 网络结构的设计
本文算法采用瓶颈结构(Bottleneck)所构成的残差块,对输入图像进行特征提取; 然后将得到的特征图送入注意力模型,其对含有目标部件等重要语义信息区域的特征图呈现高响应回归; 最后将注意力模型处理后的特征图送入常用分类回归网络,进行时敏目标的类型与瞄准点识别。其整体流程图如图2所示。
2.1 特征提取
本文算法所设计的特征提取网络包含多个残差块,其将可见光域的图像集合中的某图像fkc(i, j)进行多层次
特征提取得到特征图Fkz(i, j)。如图3所示,每个残差块由1*1的深度可分离卷积核(卷积步长stride为1)和3*3的深度可分离卷积核(卷积步长stride为2)加上残差结构组成,Filter(过滤器)数目先减半后恢复,以便于更好地提取特征。
经典特征提取网络一般通过增加卷积网络的层数来增强模型的泛化能力,从而增强算法的识别性能,但是这种方法会使模型参数计算量增大,检测速率也随之降低,而一般的嵌入式AI设备根本无法满足此类大型网络对于存储和计算资源的需求。深度可分离卷积核采用深度可分离卷积代替传统卷积,在保持通道分离的前提下实现空间卷积,从而能有效利用参数来降低网络模型的空间复杂度。深度可分离卷积将传统的卷积分解为一个深度卷积与逐点卷积,其结构如图4所示。
2.2 注意力机制
本文的注意力模型整体结构如图5所示。首先,将特征提取网络提取的特征图Fkz(i, j)输入至空间注意力模型,得到空间赋权特征图F^kz(i, j); 然后,将提取的低层特征图Fkz(i, j)与包含目标部件丰富语义信息的空间赋权特征图F^kz(i, j),并行输入至通道注意力模型中进行通道赋权。通道注意力模型可在不占用额外计算资源的情况下通过式(1)自学习高响应通道特征对应权值wz:
wz=eMzi, j∑z^ eMi, jz^, Mzi, j=F^kz(i, j)(1)
在空间赋权特征图F^kz(i, j)中,某通道所包含的信息量越多,其对应的特征响应越大。注意力网络最终的输出为
F^^kz(i, j)=F^kz(i, j)+Fkz(i, j)*wz (2)
空间注意力模型结构如图6所示,首先,将特征图Fkz(i, j)送入并行的全局平均池化层与全局最大池化层进行池化处理后,全局平均池化与全局最大池化可在不增加额外参数量的情况下, 提取特征图的全局信息,随后拼接得到对应的特征向量。其次,将拼接后的特征向量经过多个1*1的卷积核(卷积步长为1且进行填充)进行卷积,通过使用1*1的卷积核压缩输入特征向量的通道数,对特征向量所对应的空间区域进行区域响应激活,然后进行归一化处理:
w(i, j)=sigmoid(w)=11+e-w(3)
学习到空间注意力权值w(i, j),最后将空间注意力权值与原始低层特征图进行赋权得到空间赋权特征图F^kz(i, j):
F^kzi, j=Fkz(i, j)*w(i, j)(4)
2.3 网络输出
本文算法并行输出时敏目标的类型检测框与瞄准点
识别框,且两路输出在网络设计上有着相互促进的作用,即网络的输出项上存在激励关系,在非极大值抑制(NMS)模块中,时敏目标的瞄准点识别框将用于修正时敏目标的类型检测框,从而使目标领域内的置信度更高。反之亦然,其结构如图7所示。
3 实验结果分析
本文实验采用的硬件平台为: Intel i5-9400 CPU@ 2.90 GHz; 两块NVIDIA 2080TI显卡(11 G)、 16 GB内存; 操作系统为Ubuntu 16.04; 深度学习框架为Pytorch与Tensorflow; 配置环境为CUDA 10.0, CUDNN 7.4。
3.1 目标检测实验结果分析
为了验证本文算法对时敏目标类型检测的适用性与性能,关闭网络的瞄准点识别框输出通道,并且在公开的Microsoft Common Objects in Context (COCO)数据集[20]与PASCAL-VOC2012数据集[21]上开展目标检测精度评估实验。其中所使用的COCO数据集包含80个目标类别,81 769张图像作为训练集, 10 126张图像作为验证集, 11 348张图像作为测试集,平均每幅图像有5个标签信息。所使用的VOC数据集包含20个目标类别,总共包含5 515张图像,平均每幅图像有2个标签信息。目标检测精度评估实验过程中的VOC数据集划分为: 4 000张图像作为训练集,415张图像作为验证集,1 100张图像作为测试集。