一种基于知识图谱的工程教育持续改进模型
作者: 常言说 李翠 陆伟 郭晔 马春燕
关键词:工程教育;持续改进;知识图谱;决策支持
0 引言
工程教育认证具有推进工程教育改革、促进专业教育与行业企业的联系、促进国际互认等作用[1],可以提高教育质量的同时提高工程人才对产业发展的适应性,同时能提升我国工程教育的国际竞争力。2016 年我国加入《华盛顿协议》,实现了工程教育专业认证在国际上的实质等效,这也是我国进一步深化工程教育改革的契机,经过多年的实践,已有多所高校的相关专业通过了工程教育的专业认证,但无论当前是否通过认证,“持续改进”作为工程教育认证的三大基本理念之一[2–4],在提高人才培养质量方面都得到各高校的充分认可。持续改进机制的研究也很多,从改进模式到评价方法,从校内外的宏观循环到课程内外的微观循环,但当前研究需要教师或者学校的管理者根据评估结果主动进行改进,调整教学内容和教学过程,改进中的主观性成分较多,对教师和管理人员的经验及主观能动性依赖较多。本文提出一种基于知识图谱的工程教育持续改进模型,希望减少用户在持续改进过程中的主观性、减少用户在非关键事务上的精力消耗,通过让模型有一定的自我进化功能,复用在每次改进过程中的本体规则上的成果。
1 相关研究
李志义认为针对每一个循环都要应用OBE思想,确定做什么、谁来做、何时做、怎么做[5],当前提出的持续改进模式在具体改进循环和具体改进循环中各步骤上有细节的区别,但其核心思想是通过评价和反馈来发现教学中存在的问题,并针对问题进行改进,改进循环的主体多基于“评价-反馈-改进”[6],这里把决策环节隐含到改进环节了,由具体的改进的执行者去分析评价结果不够好应该改进哪些地方,这并不利于决策的科学性,也即只有找准病因才能标本兼治,判断需要改进的地方是决策的核心,也是应该给予足够重视的地方。
在当前的持续改进的循环中,评价是推动改进的基础,它又包括多种具体评价,如培养目标的合理性评价、毕业要求的达成度评价、课程体系的合理性评价、面向产出的课程教学结果评价、督导专家进行的教学过程评价等,持续改进的模式和具体评价方法需要建立在培养目标、毕业要求和课程体系一致性的基础上。但在培养体系中,培养目标、毕业要求、课程体系、课程等多个部分都需要评价和持续改进,改进过程相互交叉,实体间关系复杂交错(培养目标与毕业要求的关系,课程体系与毕业要求的关系,课程目标和毕业要求的关系),手动保证这些实体间关系的完全合理性非常困难,王永泉指出“毕业要求指标点达成度是建立在课程目标达成度的基础上的,因此,这种映射关系若过于复杂,将会给毕业要求达成度的计算带来不利影响”[7],胡立坤等人在研究中认为当前还缺少必要的工具支持帮助老师进行相关数据可分析[8],然而,不能为了易于计算而随意简化,因此需要新的模型来解决这些矛盾。知识图可以用自上而下的关系连接方式显式捕获知识,通过关系节点联系不同层次实体,基于知识图谱梳理清楚各实体间的网状关系,可以支持更好的持续改进。
2 基于知识图谱的持续改进模型
2.1 知识图谱的实体及联系
知识图谱是本文提出持续改进模型的核心,知识图谱数据库是对知识图谱的实现,以毕业要求达成度为核心的各种评价结果、教学过程数据等通过数据库来实现对高效持续改进的支撑,它既是数据的汇聚点,也是决策支持的出发点。《华盛顿协议》成员组织在通用标准体系设计中差异较小,基本遵循了协议的核心要素,但也根据国情和需要进行了一定的本土化[3],即使只按照我国工程教育认证的最新标准[1],不同专业的要求也不同,因此针对具体专业需要具体实现自己的个性化改进路径,但其核心相同,涉及的主要实体包括:培养目标、毕业要求、毕业要求指标点、课程体系、课程、课程目标等。其中,课程目标对毕业要求指标点有支撑关系,这种支撑体现为一个课程目标可以支撑一个或多个指标点,一个指标点也可以被多个课程目标支撑,也即课程目标和毕业要求指标点之间是多对多的关系,同时存在两个限制,即:所有课程目标对各指标点的总支撑权重之和为1,某指标点的支撑总权重等于所有课程目标对其支撑权重之和。
在通用标准毕业要求下,需要防范专业毕业要求与培养目标定位和特色的关系不明确,甚至完全游离。当前主流的培养目标合理性评价,主要采取问卷调查、访谈、座谈会等形式,针对行业企业、行业专家、毕业生、在校师生等多元主体进行,这些评价结果要输入数据库,数据库会以主动、被动两种形式和持续改进的主体进行交互,其中主动的方式是一种通知触发机制,需要谁处理的信息主动通知对方,被动的方式是由用户主动查看视图,这里的视图是知识图谱数据库中的可视化知识图,根据不同用户的权限创建不同的视图,可以实现精细的权限控制且各用户可以随时看到和自己相关的最新数据。
培养目标决定毕业要求,课程的目标又支撑着毕业要求指标点的达成,因此毕业要求达成度既要关注培养目标、毕业要求和课程体系的合理性,又要关注具体课程目标的实现情况,事实上牵扯到多种具体评价(培养目标合理性评价、毕业要求达成度评价、课程体系设置和课程质量评价、面向产出的课程教学结果评价、督导专家进行的教学过程评价等)和持续改进,整个流程涉及诸多实体和关系,又有很强的时效性要求,传统基于表格模板的评价和持续改进模型在实践中缺乏数据处理和数据分享效率,容易在持续改进过程中引入培养环节之间的不一致性问题,后文引入知识图谱数据库的目的之一便是解决此问题。
2.2 基于知识图谱的持续改进模型结构
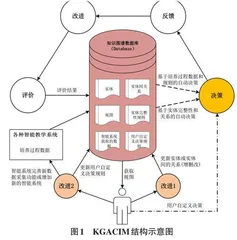
KGACIM强调数据库辅助的作用,具体模型的结构如图1所示,其中圆柱体表示数据库;圆形表示活动;矩形表示各种智能教学系统或数据采集系统;人形表示各种用户(如课程教师、教学督导、专业带头人、教务处管理人员等);带箭头的线条表示数据流,其中两条指向决策的虚线表示自动产生的数据流,指向决策的点画线表示可能产生(某次改进过程中也可能不产生)的数据流。知识图谱数据库辅助体现在两个方面:一是对传统培养过程数据、评价数据等的高效共享和一致性管理,另一方面是对培养过程数据的引入,通过对现有多源数据的处理,为决策提供支持。
当前各高校或多或少都采用了一些智能教学系统,使用的过程中自动采集了各种培养过程数据,这些数据对教学过程的持续改进有着很好的作用,主要体现在如下三方面:1) 进行智能化评估,通过分析学生的作业、考试和表现等数据,自动化地评估学生的学习水平和能力,并提供针对性的反馈和建议,这种方法不仅可以减轻老师的工作压力,也可以提高评估的准确性和客观性;2) 促进个性化学习,根据学生的学习历史和兴趣爱好,来推荐适合他们的学习内容,还可以利用这些数据来预估学生的学习表现,从而及时调整教学策略;3) 预测学生表现,利用机器学习算法和数据挖掘技术来预测学生的学习表现和成绩,把握学生未来的学习趋势,从而及早采取相应的纠正措施。这些过程数据对持续改进的作用也得到了多个实例研究的验证,如宋丹等人通过以操作系统课程为例,基于多源数据进行课程预测和预警[9],相关研究正在不断深入和发展,虽然基于教育大数据的全智能化时代还为时尚早,但已获取的培养过程数据在增多,针对这些数据进行教学过程改进的应用场景也在不断增多和完善,KGACIM将智能教学系统中采集的培养过程数据引入数据库,进而通过这些数据和现有的方法实现对教学过程的评价前改进。此处KGACIM 具有开放性,数据可以逐步增多完善,使用数据的持续改进过程也可以逐步完善。李志义教授认为学校应采取有效方式对影响教学质量的关键因素和关键环节始终处于受控状态,并让广大教师、学生和管理人员一起积极参与[10],但在现实情况下监控都需要代价,教师、学生参与监控、评价环节越多,参与的程度越深入,所需要的精力就越多,能投入其他教学环节中的时间就会被压缩,因此教师和学生最好只在必要的环节参与,不能过多,学校应采取人工智能、大数据等信息手段对影响教学质量关键因素和环节进行数据采集,这是一个渐进的过程,例如自动点名系统、课堂活跃度监控系统等。
以数据为中心,形成闭合的培养过程改进循环和模型自身的改进循环,各种评价结果和智能教学系统获取的培养过程数据进入数据库,然后从数据库出发,一方面系统可以由用户定义好的实体和实体间联系自动推导做出改进决策;另一方面系统可以通过智能获取的(或用户手工输入的)培养过程数据和规则推导给出;最后,针对自动获得的改进决策建议,用户通过人工分析进行补充,针对多路径决策结果对培养过程进行持续改进,同时通过三个自改进循环返回数据库,实现模型本身的持续改进。
2.3 模型的特点
KGACIM拥有三个自改进循环以持续改进模型本身:在模型中用户从数据库获取了自己权限对应的视图,而后如果进行了自定义决策,就说明两条自动决策(图中两条指向决策环节的虚线)的结果不完善,也即当前系统定义的实体、关系、规则,或者采集的数据有某些不完善的地方,此时用户需要分析此决策所关联的系统实体或实体间关系,进而考虑是否需要修改知识图谱数据库的概念模型(增加、修改现有实体或实体间关系),如果需要则进入“改进1”的处理环节,对数据库对应的地方进行修改完善,这就形成了“数据库”—“用户”之间对模型持续改进的循环;另一方面,如果用户需要自定义决策是由于培养过程数据缺乏所造成的,则需要反馈到学校管理部门,完善智能系统相关的数据采集功能或增加新的智能系统,而后将获取的相关数据和数据库进行连接,从而形成“数据库”—“用户”—“智能系统”之间对模型持续改进的循环;还有一种情况是因为用户定义的数据到决策的规则不正确或不完善导致需要用户自定义决策,则需要进入“改进2”的处理环节,而后对数据库中的相关规则进行更新,这就构成了“数据库”—“用户”之间对模型在用户定义决策规则方面的循环。
KGACIM具有多途径决策环节:培养体系中相关的实体较多,实体间联系存在一对一、一对多、多对多的复杂关系,传统的以表格模板为基础的评价溯源过程比较烦琐,具体执行过程容易因人而异,具有较大的主观性,效果较难保证,KGACIM对此使用多途径决策来应对,图1中指向决策环节的三根带箭头的线表示了多途径分析得到决策的过程,其中由数据库发出的两条虚线表示由数据库辅助自动产生决策的过程,一条表示根据培养过程中涉及的相关实体和实体之间的联系产生决策,另一条表示根据培养过程数据和推导规则产生决策,由用户发出的点划线表示了用户自定义决策,这种决策的做出则是基于用户从数据库获得的视图,这样就形成了以数据库为中心的多途径决策系统,从决策环节后就和现有的持续改进模式相同,进入“反馈”环节。用户从数据库查看视图后,是多途径决策的作出者之一,但主要是在两条自动决策路径得出的决策不够完善时,提供补充或者对某些错误决策提供修正,用户的主要精力可以从现有模型的“作决策”,转移到KGACIM的“分析决策”和“补充修正决策”,不用每次重复根据毕业要求评价去根据各种已经确定的关系去执果索因,可以把更多精力放在如何执行决策改进教学过程、对模型本身进行改进等事务上,也即通过数据库辅助的两条自动决策路径减小了用户的工作量,使得用户可以把更多精力放在教学或与教学强联系的“关键事务”,从而更好地改进培养过程。
KGACIM的核心是一个关系数据库系统辅助,通过中心化数据实现数据共享,针对不同的用户角色,设定不同的权限以实现最小化访问原则(受保护的敏感信息只能在一定范围内被共享,即仅向履行工作职责和职能的安全主体授予访问满足其工作需要的信息相匹配的权限,以满足相关安全策略),进而保证信息安全。由于业务范围相同,数据库中实体和实体关系定义、用户自定义决策规则等内容中的主要部分可以在相同的专业内、课程内复用。
2.4 KGACIM 与培养体系之间的关系
KGACIM的主要作用是对培养体系进行持续改进,培养体系作为教学评价的对象和智能教学系统应用的对象,为KGACIM 提供了培养过程的数据,KGACIM则通过多途径决策提供持续改进意见,支持了培养体系的持续改进,这种改进既包括由评价引起的改进循环,也包括由培养数据引起的评价前改进。持续改进的对象包括培养体系中的培养目标、毕业要求、课程体系、课程目标、课程培养过程等。
3 KGACIM 在西安财经大学的实践
西安财经大学在建立第2节基于培养过程知识图谱的基础上,实现了一个KGACIM结构的持续改进原型系统,图1中的“改进2”就包括对智能系统的完善,模型通过连接现有智能教学平台,如i西财大、智慧学习系统等,还不定期收集教师和相关用户对智能教学系统的新需求,并进行及时处理。在原型系统中,也定义了许多基于知识图谱数据库中实体间关系的自动决策规则,当然这前提是西安财经大学对所有工科课程实行了OBE的教学改革,当前可以将具体的毕业要求、考核内容自动对应到具体的知识点,每次考试结束后,系统自动给出初步的试卷分析,在此基础上教师进行修改。相关规则也在进一步完善。这大幅提高了教师的效率。
4 结束语
基于知识图谱的工程教育持续改进模型旨在实现以数据为驱动,以多途径的决策支持为抓手,让模型自身也持续改进,减小用户人工分析的工作量和不确定性,进而让用户集中精力于规则的完善和教学过程的具体改进上。为了实现评价的溯源分析,需要运用人工智能、大数据等技术来从培养途中采集过程数据,然而不同学校当前拥有的智能化系统的功能和程度并不相同,甚至使用相同系统的学校也可能存在差异。因此,在实施KGACIM整体运行的过程中,可以循序渐进,逐步完善,以确保整个评价系统的高效运作。KGACIM克服了传统表格方式的低效率、低效果等缺点,并通过信息化技术实现了高效的数据采集。同时,其结合了知识图谱技术实现了半自动化数据分析,最终实现了高效持续改进,能够有效支撑新工科建设。KGACIM具有很好的复用性,但其推广应用需要构建知识图谱以及与现有信息系统进行对接,因此需要由学校的教务管理部门自上而下进行推动和应用。