基于Python爬虫技术的招聘信息数据可视化分析
作者: 付腾达 李卫勇 王士信 许佳 鲁春燕
摘要:基于Python爬虫技术,实现了从BOSS直聘网爬取南昌市与IT行业相关招聘信息的过程。爬虫程序对BOSS直聘网爬取所需信息,并对爬取的数据进行清洗、整理、分析等操作,确保数据的准确性和一致性,随后将数据存储至MySQL数据库中,供后续分析与使用。该系统后端采用基于Python的轻量级Flask框架,前端使用HTML5、CSS3、JQuery、Bootstrap5等技术,此外,还结合了基于JavaScript的Echarts数据可视化图表库,以实现数据到可视化效果的转换。系统可以为广大应聘人员提供有利的决策支持,以帮助他们更轻松地找到合适的岗位信息。
关键词:BOSS直聘;网络爬虫;Flask;数据可视化;Echarts
中图分类号:TP393.09 文献标识码:A
文章编号:1009-3044(2024)07-0077-06
开放科学(资源服务)标识码(OSID)
0 引言
随着互联网进入大数据时代,数据呈指数级增长,由于数据量庞大使查找信息时间周期长、精准度差、效率低,以致想通过网络快速找到符合自己的岗位信息尤为困难。为此,很多研究者开始对招聘数据进行了相关研究,其中毛遂[1]以51job网为例对岗位占比和企业类型、薪资同学历与地区之间的关系进行了分析。丁文浩[2]以前程无忧网为例对城市和岗位平均薪资水平、工作经验、学历情况等进行了分析。王福成[3]以拉勾网为例对高校程序设计语言类的招聘职位地域分布、职位与薪资、学历与技能要求等进行了分析;罗燕[4]对人工智能类的招聘岗位、招聘行业、招聘城市等进行了分析。
本文基于Python爬虫技术,从BOSS直聘网采集南昌市IT行业相关的招聘信息,通过分析与数据可视化图表的展示,为南昌本地应聘者提供决策支持。
1 相关技术
1.1 网络爬虫
网络爬虫是一种自动化程序或者脚本,用于在互联网上自动采集数据。原理是通过HTTP协议向目标服务器发送URL请求,然后根据服务器响应提取所需数据,通常以HTML或JSON等格式呈现。然后使用Python语言结合Pycharm集成开发环境以及一系列库,包括BeautifulSoup库、正则表达式re库、Jieba分词库、WordCloud 模块、JSON模块、lxml解析器及xlwt库,来处理和存储这些数据,以便后续分析。
1.2 Flask框架
Flask是一款轻量级而强大的Python Web框架,专门用于构建Web应用程序和RESTful API。尽管被视为是轻量级Web框架,但它却提供了出色的灵活性和简洁性。Flask还允许开发者自定义URL路由,将URL映射到不同的视图函数,以便处理各种请求。此外,Flask还内置了Jinja2模板引擎,使得HTML模板的渲染变得非常容易,因此备受开发者青睐。
1.3 ECharts可视化库
ECharts是一款开源JavaScript库,专注于创建高级数据图表。它建立在轻量级的Canvas库ZRender之上,提供了丰富多彩的图表类型,主要有折线图、柱状图、散点图、饼图等多种可视化图表。ECharts的架构分ZRender层和ECharts层,这为开发者与数据分析人员提供了强大的可视化功能,使他们能够轻松地在Web页面中创造引人注目的数据可视化效果。因其强大的功能和易实用性,目前已被众多知名公司广泛采用。
1.4 Jieba分词库
Jieba分词库是一款流行的Python库,专用于中文文本分词。它因高效准确的分词性能而著名,支持多种分词模式,包括精确模式、全模式和搜索引擎模式。此外,Jieba分词库还允许用户自定义词典,以适应不同领域的文本分析需求。因此,它常被广泛应用于中文自然语言处理和文本挖掘任务中。
2 招聘数据爬取与预处理
2.1 招聘数据爬取
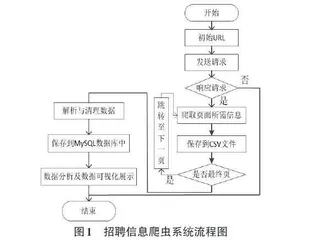
设计招聘数据爬虫系统的流程如下:
步骤1:分析URL。
步骤2:访问待爬取的招聘数据。该模块使用requests库请求数据,然后通过BeautifulSoup库下载页面信息,并利用lxml解析器解析数据。
步骤3:将数据存储到CSV文件中。
步骤4:对爬取的数据进行清洗、整理、分析等预处理操作。
步骤5:将经过预处理得到的数据存储到MySQL数据库中。
步骤6:数据分析并可视化展示。
招聘信息爬虫系统流程图如图1所示。
2.2 招聘数据爬分析页面结构
在BOSS直聘网的搜索框中输入“Web前端工程师”职位,页面显示与该职位相关的岗位信息。接着在源代码调试界面中使用“审查”选项,发现待爬取的信息缺失,通过在Network选项界面下的Filter搜索框中输入“JSON”,发现存在名为joblist.json格式的条目。经查看发现,岗位数据存储在该条目文件的“jobList”键对应的值中,其存储着每一页30个职位信息,如图2所示。
2.3 分析URL
通过对页面结构的分析,发现存储真实岗位数据的joblist.json文件URL格式为:“https://www.zhipin.com/wapi/zpgeek/search/joblist.json?scene=1&query=Web%E5%89%8D%E7%AB%AF%E5%B7%A5%E5%85%B7&city=101240100&experience=&payType=&partTime=°ree=&industry=&scale=&stage=&position=&jobType=&salary=&multiBusinessDistrict=&multiSubway=&page=1&pageSize=30”。通过翻页对比分析,发现每页URL中的page参数值随页面变化而变化。
因此,可以构建一个循环来获取与搜索岗位相关的不同页面的URL,并将这些URL地址存储在一个URL列表中,以便进行网址请求和数据爬取操作。
2.4 爬取招聘数据
在进行请求URL过程中,为绕开反扒机制,需要在请求的Headers中添加一个“User-Agent”用户代理,这样代码将会伪装成浏览器的形式获取数据。接着通过使用requesrts库的get()方法发送请求并获取数据,然后使用BeautifulSoup库以及lxml解析器解析数据,进一步使用json.loads()方法将获取的数据转化成JSON格式。经分析发现,真实数据存储在“jobList”键对应的值中,通过以访问字典的方式获取这些数据,即data["zpData"]["jobList"]。然而在“jobList”键中所需要待爬取的字段主要有jobName、brandName、cityName、areaDistrict、businessDistrict、jobExperience、jobDegree、salaryDesc、brandStageName、brandIndustry、brandScaleName、skills、welfareList,这些字段分别对应为职位、公司名、城市、地区、商业区、工作经验、教育水平、薪水、品牌舞台、公司行业、规模人数、技能和福利等数据信息。
2.5 数据保存到CSV文件中
本文将爬取的数据存储到CSV文件中。数据存储过程是先使用xlwt库中的Workbook()方法创建一个工作簿,并且在该工作簿对象下使用add_sheet()方法创建一个工作表,通过使用write()方法将所需数据写入到该工作表中,最后调用save('文件路径')将数据保存到CSV文件[5]中。存储在CSV文件中的招聘数据如图3所示。
2.6 预解析数据
由于从BOSS直聘网直接爬取的数据可能存在脏数据,直接使用会影响后续数据分析的准确性和数据可视化效果。因此,使用前需要对这些数据进行预解析操作,以将其转化为有效可靠的数据。预解析数据操作主要包括数据去重、处理空值、数据变换、属性格式化等操作,经过预处理操作的数据可提高数据分析的精确性和可靠性。
1) 数据去重。企业可能会发布相同职位的招聘信息,因此需对重复的招聘信息进行去重操作。通常情况下,一般将“公司名”与“职位”相同的数据视为重复数据,核心代码如下:
df.drop_duplicates(inplace=True)
2) 空值处理。爬取的数据中存在许多空值(Nan)数据,为了确保数据的准确性,采取的处理方法是直接删除包含空值的行数据,核心代码如下:
df.dropna(axis=0, how=”any”)
3) 数据变换。由于数据中“薪水”属性列存在格式不统一的情况,如“***-***K”、“***-***K·***薪”与“***-***/天”。为方便数据管理,现对薪水列进行数据变换[6-8],统一成“***×1000/月”的数据格式。
原始“薪水”属性列是以范围值“a - b”或“a - b·c”的形式存在。因此,可以构造三个新的属性列“最低薪资”“最高薪资”和“平均工资”。在这些范围值前提下,“最低工资”值为a,“最高工资”为b,其中c表示年底多发的薪资部分,即12个月工资+年底多发(c - 12)个月工资,如13薪,表示年底多发1个月的工资。对于按天计算薪水的情况,以一个月工作21天结算工资。对于按小时计算薪水的情况,由于数据量少且对数据分析影响较小,将其删除。经过数据变换有助于标准化薪水数据,以便后续分析。
4) 属性格式化。在joblist.json文件中, 存在名为“技能”和“福利”的属性列,它们以列表的方式存储数据。以“福利”属性列为例,由于不同公司提供不同的福利待遇,导致“福利”长度各不相同,这种不规则性给数据分析带来了一些挑战。因此,需要对“福利”属性列进行数据的规范化处理,以将其转化为更适合进行数据分析的数据格式。
“福利”列属性格式化前,形式如下:
lst = ['员工旅游','定期体检', '餐补','年终奖','住房补贴','节日福利','带薪年假', '免费班车','交通补助','五险一金']
“福利”列属性格式化后,形式如下:
lst = ['员工旅游、定期体检、餐补、年终奖、住房补贴、节日福利、带薪年假、免费班车、交通补助、五险一金']
预解析得到的最终数据如图4所示。
5) 数据保存到MySQL中。系统使用MySQL数据库存储预解析后的数据,创建一个名为“boss”的数据库,用于存储招聘信息,数据库结构见表1。
3 数据可视化
系统最后实现了对BOSS直聘网南昌市与IT类招聘数据的可视化,并将分析结果以图表的形式在前端页面上进行展示。本系统的主要工具包括基于Python Web框架Flask以及开源可视化库Echarts,通过该系统观察招聘数据的相关可视化图表,应聘者可以更加方便浏览招聘信息,为求职者提供了更好的招聘信息可视化平台。
3.1 区域数据分析
通过对南昌市各行政区和这些行政区内各区域的公司数量进行了详细分析,发现一些引人注目的趋势。首先,较为繁华的行政区往往拥有更多的企业,反之企业数量较少。其次,由于交通便捷程度、距离市中心的远近等因素,如进贤县、安义县的公司数量相对较少。
基于上述发现,可以得知,若应聘者选择在繁华的区域或者离市中心较近区域的企业投递简历,拥有更多的机会获得面试资格,并且被录用的概率也会大大增加。该分析结果可以帮助求职者更有针对性地选择投递位置,提高他们的就业机会。如图5所示。