基于领域不变特征的跨库微表情识别
作者: 尹梦涛 杨亚璞
摘要:针对跨库微表情识别中因训练和测试样本特征分布不一致而造成的识别效果不理想的问题,提出一种基于域内不变特征和域间不变特征(Intra-domain and Inter-domain Invariant Features,IIDIF) 整合的跨库微表情识别的领域泛化方法。IIDIF使用知识蒸馏框架获取傅里叶相位信息作为域内不变特征,通过对齐源域特征之间的二阶统计量作为域间不变特征,同时设计一个不变特征损失将域内不变特征和域间不变特征整合为领域不变特征。在三个广泛使用的微表情数据集CASMEⅡ、MMEW以及SMIC上的实验表明,IIDIF方法的平均准确率为55.37%,优于现有主流的领域自适应和领域泛化方法,验证了所提出的IIDIF方法在跨库微表情识别任务上的优越性。
关键词:跨库微表情识别;域内不变特征;域间不变特征;领域泛化
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2024)09-0027-05
开放科学(资源服务)标识码(OSID)
0 引言
微表情是人们试图隐藏内心真实情绪时所产生的一种自发式面部表情,通常持续时间只有0.04~0.2 s,且变化强度很低[1]。微表情可以准确反映人们真实的心理状态和情绪,无法伪造也不能抑制,在商务谈判、刑侦和心理疾病治疗等领域上具有广泛的应用前景[2]。
近些年来,研究人员在微表情识别任务上提出了许多有效的方法,如能有效提取微表情外观特征的三个正交平面的局部二值模式(LBP-TOP)[3];能准确计算面部细微动作变化特征,并通过时空信息进行微表情识别的光流法[4]等。最近,随着深度学习的发展及其在面部表情识别[5]上的成功应用,深度学习方法也被应用于微表情识别任务[6]。如用于捕获微表情序列细微时空变化的时空卷积递归网络(STRCN)[7]等。
虽然微表情识别研究已经取得了显著的进展,但现有大多数微表情识别方法的训练和测试样本都来自遵循相同特征分布的同一个数据集,而在许多实际应用中,用于训练和测试的微表情样本可能来自不同的数据集。不同数据集的种族、性别、摄像设备等会有所不同,这破坏了训练和测试样本之间的特征分布一致性。在这种情况下,上述微表情识别方法的性能可能会急剧下降。因此,一部分研究人员开始关注训练和测试样本来自不同数据集的跨库微表情识别这一具有挑战性的课题。目前,研究人员大多采用领域自适应方法解决训练集(源域)和测试集(目标域)特征分布不一致的问题。领域自适应方法是迁移学习方法[8]的一种,尝试利用源域中丰富的标记样本信息,通过减少数据集之间的特征偏差来促进对目标域的学习。
然而,领域自适应方法依赖一个强有力的假设,即目标域数据可用于模型适应,这在实际场景中并不总是成立。在许多应用中,目标数据在部署模型之前很难获得,甚至是未知。对此,一部分研究者尝试使用领域泛化方法解决此问题。领域泛化方法的一个显著特点是在训练过程中,目标域是未知的。具体来说,领域泛化的目标是利用来自单个或多个相关但不同的源域数据进行模型训练,使模型能够很好地推广到任何未知的目标域[9]。自2011年研究者们开始探索领域泛化以来,已经提出大量的方法来解决此问题,包括增加数据多样性的数据增强[10]、通过模拟多个任务来学习一般可转移知识的元学习等[11]。领域不变特征学习[12]也是一种主流的领域泛化方法,旨在从不同领域中学习领域不变的特征表示或者对特征进行解耦以获取更有意义的泛化特征,从而有利于跨域泛化。
领域泛化方法虽然更有利于模型的实际应用,但它比领域自适应方法更难以实现,目前与跨库微表情识别相关的领域泛化方法研究工作相对较少。为了更好地利用领域泛化技术解决跨库微表情识别存在的问题,本文提出了一种基于域内和域间不变特征的跨库微表情识别方法(Intra-domain and Inter-domain Invariant Features,IIDIF) 。本文将域内和域间两种不变特征整合为领域不变特征进行模型训练。对于域内不变特征,IIDIF通过知识蒸馏框架捕获对数据进行傅里叶变换之后的高级内在语义,对于域间不变特征,IIDIF利用相关性比对来对齐源域的特征分布,同时设计增加了一个发散损失函数来最大化发散两种不变特征之间的距离,以保证使更多不同的域内和域间不变特征参与模型训练。最后通过实验验证了该方法的有效性。
1 IIDIF模型及方法
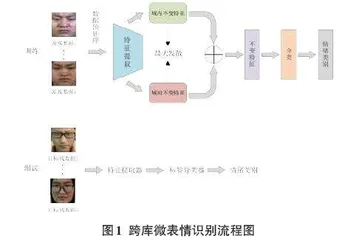
为了提高仅利用微表情源域样本训练出的模型在未知微表情目标域上的识别性能,本文从领域泛化的角度出发,设计了基于域内和域间不变特征的跨库微表情识别算法,跨库微表情识别流程图如图1所示。
在模型训练阶段,首先对训练数据进行预处理,然后利用特征提取器分别提取域内不变特征和域间不变特征,并在最大化两种不变特征之间的距离后,将其整合为领域不变特征进行分类。
1.1 域内不变特征提取
信号由振幅信息和相位信息两部分组成。在信号的傅里叶谱中,相位分量保留了原始信号中的大部分高级语义,而振幅分量主要包含低级统计信息。相位信息的重要性如图2所示。
在图2中,对图片a和b进行离散傅里叶变换。对于单通道尺寸大小为M×N的图像数据[x],其傅里叶变换[Fx]为:
[Fxu,v=m=0M-1n=0N-1xm,ne-j2πmMu+nNv] (1)
式中:[u]和[v]为频率变量,[Fx]振幅分量和相位分量可以分别表示为:
[Axu,v=R2xu,v+I2xu,v12] (2)
[Pxu,v=arctanIxu,vRxu,v] (3)
其中,[Rx]和[Ix]分别表示[Fx]的实部和虚部。
通过上式可以得到a和b相应的幅值信息[Aa]、[Ab]和相位信息[Pa]、[Pb],保持幅值信息不变,交换两幅图的相位信息,最后对重新组合的图像信息进行离散傅里叶逆变换,得到两幅新的图像a*和b*。从结果中可以看出,a*与b相似,b*与a相似,从而说明傅里叶相位包含更多原来图像的信息。
傅里叶相位信息作为一种领域不变特征已经引起许多研究者的关注。例如,Xu等人[13]提出了一种基于傅里叶变换的领域泛化框架,利用傅里叶相位特征不易受域变化影响的特点,从频谱相位分量中学习更多信息以帮助模型获得域内不变的特征。
本文利用知识蒸馏框架获取域内不变的傅里叶相位特征信息。知识蒸馏(Knowledge Distillation,KD) 是一种鼓励在不同网络中包含特定特征的教师—学生训练框架。域内不变的傅里叶相位特征蒸馏框架如图3所示。
将输入教师网络数据[x]的傅里叶相位表示为[x],使用[x,y]训练教师网络后,在教师网络训练完成之后,使用特征知识蒸馏来引导学生网络学习傅里叶相位信息。经过蒸馏引导后,学生网络参数[ws]可以表示为:
[ws=argminwx,yL1fx;w,y+L2FeaSx,FeaTx] (4)
式中:[L1⋅,⋅]为神经网络中常用的交叉熵损失函数,[f⋅;w]为学生网络,[w]为学生网络中的参数,[FeaS]和[FeaT]分别为学生网络和教师网络的特征提取器,[L2]为使学生网络特征接近教师网络特征的均方误差损失函数。
1.2 域间不变特征提取
仅使用傅里叶相位特征可能不足以获得足够的分类判别特征。因此,本文利用多个训练域中包含的跨域知识来探索域间不变特征。具体来说,给定两个域[Si]和[Sj],对它们的二阶统计量(协方差)进行对齐,域间对齐损失函数[L3]为:
[L3=14d2Ci-Cj2F] (5)
式中:[⋅2F]为平方矩阵Frobenius范数,[Ci]和[Cj]分别为[Si]和[Sj]的协方差矩阵。针对本文跨库微表情识别任务只有单个源域的情况,通过使用随机参数在源域上进行采样,得到与源域具有不同特征分布的随机域,之后将源域与随机域进行域对齐训练以获取域间不变特征。
1.3 领域不变特征整合
由于域内不变特征和域间不变特征之间可能存在重复和冗余,为了能尽可能利用更多不同的不变特征,定义一个发散损失函数[L4],通过利用L2距离函数最大化发散域内不变特征[z1]和域间不变特征[z2]之间的距离,以提取更多有利于泛化的不变特征,发散损失函数[L4]公式表示为:
[L4z1,z2=-z1-z222] (6)
汇合公式(4) ,(5) ,(6) ,可以得到IIDIF完整的优化目标:
[ws=argminwx,yL1fx;w,y+λ1L2FeaSx,FeaTx+λ2L3+λ3L4z1,z2] (7)
式中:[λ1]、[λ2]、[λ3]分别为域内不变特征学习、域间不变特征学习以及发散损失函数的超参数,模型通过调整平衡超参数以获得更好的分类性能。
2 实验结果与分析
2.1 数据集预处理
本文在三个公开的微表情数据集上进行实验,分别是CASMEⅡ数据集[14]、MMEW数据集[15]以及SMIC数据集[16]。由于不同微表情数据集之间的情绪类别不统一,为了更好地进行泛化实验,需要对微表情数据集的情绪类别进行重新标注。考虑到3种微表情数据集的情绪类别和实验设置的合理性,本文对实验涉及的3个微表情数据集进行以下重新组织和标注:
1) 对于CASMEⅡ数据集,舍弃类别为“其他”的情绪样本,将“厌恶”“压抑”“悲伤”“恐惧”样本标记为“消极”,将“快乐”样本标记为“积极”,“惊讶”样本的标签保持不变。
2) 对于MMEW数据集,舍弃类别为“其他”以及数量较少的“愤怒”情绪样本,将“悲伤”“厌恶”和“恐惧”样本标签标记为“消极”,将“快乐”样本标记为“积极”,“惊讶”样本的标签保持不变。
3) 对于SMIC数据集,保持原有的“消极”“积极”以及“惊讶”情绪样本类别不变。
重新标注和排序后,每个数据集中的样本数量如表1所示。
由于微表情数据集的样本数量较少,不足以支撑模型训练,因此需要对数据样本进行扩增以增加实验的可靠性。为避免丢失特征细节,仅对微表情序列的起始帧和顶点帧图片采用旋转和镜像翻转这两种方法进行扩增。由于微表情数据集中不同情绪类别的数量相差过大,为避免因样本类别不均衡而造成的实验性能下降,对样本数量较少的类别,将其顶点帧前一帧或者后一帧图像同样视作样本顶点帧,以实现大致平衡不同类别样本数量的目的。经过扩增之后的微表情数据集的样本数量信息如表2所示。
2.2 跨库微表情实验设置
本文实验基于CentOS Linux release 7.6.1810(CORE) 操作系统进行,CPU为Intel(R) Xeon(R) Gold 6226R、GPU为NVIDIA GeForce RTX 3090,实验环境为Python 3.8和CUDA 11.0,深度学习框架为PyTorch 1.7.0。
实验选取三个微表情数据集中的任意2个分别作为源域和目标域进行跨库微表情识别实验,共有6种组合,实验方案如表3所示。
其中:C为CASMEⅡ数据集,S为SMIC数据集,M为MMEW数据集,“→”两边的字母分别为源域和目标域。
2.3 消融实验
2.3.1 模型结构消融实验
本文研究基于领域不变特征的跨库微表情识别,领域不变特征包括域内不变特征和域间不变特征。为了验证这两种不变特征以及加入不变特征损失函数后对模型性能的提升效果,以M→C跨库微表情识别任务为例,设计了如下消融实验,消融实验结果如表4所示,其中“√”表示添加本文模型的相应部分,“—”表示没有添加本文模型的相应部分。