基于变分自编码器的音乐生成模型
作者: 白勇
关键词:变分自编码器;音乐生成;深度学习;双向LSTM
0引言
音乐一直是人类文化中不可或缺的一部分,它不仅是娱乐的形式,还承载着情感、思想和文化的传承。随着计算机科学和人工智能技术的迅速发展,音乐生成技术也得到了广泛关注和研究[1]。传统的音乐生成方法主要依赖于音乐家的经验和技巧,而随着机器学习和生成模型的兴起,人工智能已经成为一种强大的工具,可以帮助人们更好地理解、创作和欣赏音乐[2]。
音乐生成领域自20世纪末开始受到了广泛的关注和研究。近年来,随着深度学习和人工智能技术的发展,越来越多的研究集中在使用神经网络和生成模型来实现音乐生成。文献[3]中,Lim等人提出了一个基于GAN的算法,用来生成具有良好节奏和和声的钢琴音乐。通过对抗训练,模型能够生成高质量的音乐作品。文献[4]中,Huang等人提出了一种基于Trans⁃former的方法,来生成流畅的音乐序列。该模型能够学习音乐的时序模式和结构特征,从而生成具有一定音乐风格的作品。文献[5]中,Jaques等人提出了一个基于强化学习的方法,用来生成具有个性化风格的爵士乐。该模型能够生成符合用户需求的音乐作品。
然而,目前的音乐生成模型仍然存在一些挑战。虽然这些模型可以生成更具创意性的音乐,但其生成结果往往与真实音乐存在较大差距。因此,寻找一种能够从真实音乐数据中学习更加接近真实音符概率分布的音乐生成模型成为当前研究的重点之一[6]。
针对上述问题,本文提出一种基于VAE的音乐生成模型。该模型包含编码器和解码器,编码器将真实音乐数据编码到潜在空间中,解码器则通过对潜在空间的数据进行解码,生成新的音乐作品。通过这种方式,模型能够更好地学习真实音乐数据中的音符概率分布,使生成的音乐更加贴近真实音乐。
1本文模型
为了完成端到端的音乐生成任务,本文借用变分自编码器(VAE)构建音乐生成模型[7]。该模型包含编码器和解码器两个网络,编码器的主要作用是对输入数据进行处理,将其映射为低维度的潜在向量,而解码器负责对编码器生成的潜在向量进行反向映射,最终转换成音乐。
1.1数据预处理
在实验中使用的是MIDI格式的音乐数据,MIDI是一种音乐数字化格式,通过music21可以很方便地提取音符的特征信息[8]。为了减少不同音乐类型之间的影响,本文使用的训练数据主要侧重节拍为4/4拍的音乐。为了减少数据冗余的影响,所有音乐作品都转为C大调,并限制在2~3分钟。共收集20000个MIDI格式的音乐样本数据集。
音符序列表示是一种将音乐数据表示为一系列音符的序列的方法。在MIDI格式中,每个音符被表示为一个事件(event),其中包含音符的音高、开始时间、结束时间等信息。假设有一段音乐,其中包含多个音符,可以将这段音乐表示为一个包含多个音符的序列,每个音符可以用一个向量来表示,其中包括以下信息:
1)音高(Pitch):音符的音高,通常用MIDI音高表示法来表示,取值范围为0~127,其中60表示中央C音符。用pi表示第i个音符的音高。
2)开始时间(OnsetTime):音符开始播放的时间,通常以秒为单位。用ti表示第i个音符的开始时间。
3)持续时间(Duration):音符持续的时间长度,通常以秒为单位。用di表示第i个音符的持续时间。
4)音量(Velocity):音符的强度,通常以MIDI音量表示法来表示,取值范围为0~127。用vi表示第i个音符的音量。
通过将每个音符的信息组织成一个向量,可以得到整段音乐的音符序列向量,表示为:
式中,N为音符序列的长度,表示音乐中包含的音符数量。通过这种表示方式,可以将音乐数据转换为一个序列,以便于模型进行处理和学习。
1.2模型框架
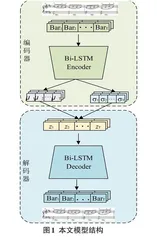
本文设计的模型由编码器网络和解码器网络组成,它们分别负责将输入音乐数据映射到潜在空间中的潜在表示,以及将潜在表示映射回原始数据空间,实现音乐的生成。具体结构如图1所示。下面将详细介绍各部分的具体实现。
1.2.1编码器网络
编码器网络的作用是将输入的音乐数据x转换为潜在空间中的潜在表示z。在本文模型中,编码器网络由Bi-LSTM(双向长短期记忆网络)构成[9]。相比于传统的LSTM(长短期记忆网络),Bi-LSTM的网络结构中隐藏层由两个方向相反的LSTM构成,不仅能够学习过去信息的影响,还能学习到未来信息对当前时刻的依赖关系,其结构如图2所示。
图2中h为前向隐藏层输出,h为后向隐藏层输出,利用公式(2)~(4)可以得到Bi-LSTM隐藏层的整体输出h:
编码器网络参数λ模型为qλ(z|x),其目的是通过训练逼近真实的后验分布p(z|x),使生成z的分布尽可能接近真实音乐数据x的概率分布。为了实现这一目的,假设这个概率分布为正态分布,即p(z|x)=N(0,Ι)。这样,编码器网络的输出只须不断模拟均值向量μ和方差向量σ2,即可不断逼近真实数据的概率分布。这一过程也相当于把输入的相关信息压缩到一个较低维度的潜在空间中。已知输入的音乐数据x={x1,x2,…,x}T在经过Bi-LSTM之后得到ht,通过全连接层之后可以得到均值向量μ和方差向量σ2,计算如下公式:
1.2.2解码器网络
解码器网络是模型中的生成网络,其作用是将潜在表示z映射回原始数据空间,从而生成音乐数据,本文同样将Bi-LSTM网络作为解码器网络。解码器网络的参数为θ,模型为pθ(x'|z),其目的是通过训练尽可能逼近真实的似然分布p(x|z)。在上述过程中,得到均值向量μ和方差向量σ2后,通过采样可以得到z。将z作为解码器的输入,并通过解码器网络将其映射回原始空间,就可以得到原始数据x的重构x':
式中,Wx为解码器网络的权重矩阵,bx为解码器网络的偏差向量,fx为解码器网络的激活函数。得到重构数据x'之后,通过music21工具包可以将其转化成音乐。
1.2.3模型训练
在训练本文模型时,通常使用的损失函数由两部分组成:重构损失(Reconstructionloss)和KL散度损失(Kullback-Leiblerloss,KLloss)。这两部分损失函数共同构成了模型的优化目标,旨在训练模型使得其能够有效地学习数据的潜在表示。
重构损失用于衡量模型生成数据的能力,它衡量了模型生成数据与原始输入数据之间的差异。在音乐生成任务中,可以使用交叉熵损失函数或均方误差损失函数来计算重构损失。假设原始输入数据为x,模型生成的数据为x',则重构损失可以表示为:
2实验
2.1实验配置
本次实验所使用的服务器配置为IntelXeon2640v42.4GHz处理器,500GB运行内存和12GB显存的NVIDIA4080GPU。所用编程语言为Python,框架为PyTorch。
2.2不同参数设置对实验结果的影响
本次实验主要针对不同的隐藏层神经细胞个数以及不同训练次数对模型生成音乐的影响。关于不同隐藏层神经细胞个数,本文做了三组对比实验,对结果数据进行平滑处理,如图3所示。
从图3可以看出,随着隐藏层神经细胞个数的增多,Loss值的收敛速度减小,表明模型生成的预测值和目标值之间的误差更小。然而,随着隐藏层神经细胞个数的增多,训练阶段所需的时间也增加。
为了验证不同迭代次数对生成音乐的影响,本文将不同迭代次数的模型生成的音乐转换成频谱形式进行对比,结果如图4所示。
从图4可以看出,当迭代达到2000次时,生成音乐的频谱开始出现样本频谱的起伏规律,但其分布与样本音乐频谱仍存在较大差距。当迭代达到4000次时,生成音乐的频谱呈现出规律性,并且与样本频谱的分布相似。
2.3音乐相似度
音乐相似度实验旨在比较不同音乐样本之间的相似程度,通常使用各种相似度度量方法来量化音乐之间的相似性。为了验证模型学习真实音乐数据的能力,本文进行了音乐相似度实验。实验选用的相似度度量方法为调整余弦相似度(AdjustedCosineSimi⁃larity)[10],其计算公式如下:
式中,Rˉi为维度i上的均值。实验对于每一对音乐样本和生成音乐,计算它们之间的相似度分数,共计算50对,绘制的折线图如图5所示。
从图5可以看出,生成音乐和样本音乐的相似度均在0.6之上,说明模型能够从真实音乐数据中学到音符在时间尺度上的依赖关系。
2.4音乐主观评价
为了验证本文模型生成音乐的质量,进行了主观评价实验。实验的主要对象是本文提出的模型、基于LSTM的音乐生成网络,以及真实音乐。邀请了8名音乐学院的教师以及30名音乐学院的学生对测试音乐进行匿名打分评价。评分主要从韵律、旋律、调性、流畅度、完整度、悦耳度六个方面进行,汇总最后得分,结果如表1所示。
从表1可以看出,本文模型生成的音乐在评价指标上总体优于基于LSTM音乐生成模型生成的音乐,但与真实音乐之间仍存在一定差距。
3结束语
为了让模型能够更好地学习真实音乐中音符的概率分布,本文引入了变分自编码器(VariationalAuto⁃encoder,VAE)。利用Bi-LSTM网络构建编码器和解码器,将原始音乐数据映射为潜在空间的表示,然后对潜在表示进行解码生成新的音乐,完成端到端的音乐生成任务。通过实验验证,模型生成的音乐较为接近真实音乐。但是也可以看出,模型生成的音乐与真实音乐之间仍存在一定差距,因此提高生成音乐的质量还需进一步研究。