改进的骨架线提取及特征点定位算法
作者: 张元东
关键词:文字细化;骨架线提取;特征点定位;视觉关注机制
0引言
近年来,随着符号识别、文字识别、模式识别等识别技术的迅速发展,文字分割技术在医学图像处理、签字印章、自动化线路检测等各个领域得到了广泛应用,而文字细化作为文字分割技术的关键特征描述,也是表征文字拓扑结构特征的重要手段。从计算机视觉角度分析,文字也是一幅传递信息的图像,因此对文字进行细化研究具有重要意义[1]。
文字骨架线的提取是文字细化过程中的重要步骤,骨架线提取的质量高低与算法本身有直接关系。特别是对于结构复杂的文字,提取后的骨骼线可能存在毛刺、连通性断点等问题,甚至出现变形或失真现象,对实际生产应用产生误判影响。因此,在保证文字原始拓扑结构和重要特征不变的前提下,如何优化文字细化算法以获取视觉关注质量更佳的文字骨架线,成为文字识别领域研究的热点问题[2]。
为提高文字细化准确率,国内外学者提出了多种优化的文字细化算法。文献[3]对Hilditch细化算法进行改进,获得了准确率更高的细化算法,但其抗干扰性能较差。文献[4]对EPTA算法进行优化,获取了文字骨架模型,但对文字交叉点及拐点的处理效果不佳。文献[5]基于旋转不变性对Pavlidis 算法进行改进,获得了质量更高的文字细化线,但对于笔画较多的繁体文字仍存在细化不完全现象。文献[6]采用径向神经网络算法设计了一种迭代规则进行文字细化,虽然获得了较佳的文字骨架线,但细化结果严重依赖于参数选择,适用性较差,且算法复杂度较高。文献[7]对Zhang并行细化算法进行优化改进,虽然进一步降低了毛刺现象,但细化的文字骨架线易出现局部信息缺失问题。
以上算法在提高文字骨架线质量方面取得了一定的成效,但细化的准确率和真实性仍存在一定不足。这些算法多是从自身优化角度或给予现有算法存在的弊端进行改进,其细化性能和鲁棒性仍需提升。
本文从骨架线提取和骨架线定位两个方面着手,以获得更符合视觉关注度的文字骨架线。首先,基于深度优先遍历和八邻域特性提出一种骨架线提取规则,并进行迭代判断,提取出准确率更高的文字细化模型。然后,在提取的文字细化骨架线上采用极大似然估计结合空间映射机理定位文字骨架线,提高细化后文字的还原度,以达到真实性高、鲁棒性强的文字骨架线要求和目的。
1 改进的文字骨架线提取算法
针对 Zhang 并行细化算法在细化后文字存在局部信息缺失或毛刺问题,Li 等[8]对 Zhang 并行细化算法进行了优化,获得了质量更佳的文字骨架线,但对于个别繁体文字仍然不具普适性。研究表明[9],文字骨架线是表征文字重要特征的关键信息,其特征主要分布在点和线上。本文首先将文字按书写顺序对笔画进行拆分并逆序压入栈中,然后基于四邻域机制按出栈顺序对每个笔画采用设计的细化规则进行遍历和细化,确定细化后的骨架线点;最后,根据边界点特性采用提出的判别机制筛选骨架线点,获得细化后的文字骨架。
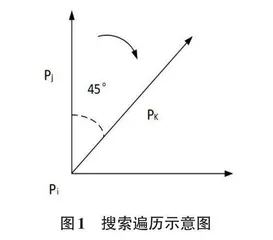
1)首先对当前笔画从任意边界点Pi 出发,沿如图1所示两个方向顺时针次序搜索,两个方向点分别为Pj 和Pk,其中规定背景点像素值为0,前景点像素值为1。
2)对当前边界点Pi 采用设计的细化规则进行遍历,其计算公式如式(1)
式中:∀ ( Pi ,Pj )E 表示点Pj 和Pk 都存在,∃ ( Pi ,Pj )E表示点Pj 和Pk 仅有一个存在,NF ( Pj ) 表示Pj 点四邻域像素值为0的点,NF ( Pk )表示Pk 点四邻域像素值为0的点,⋂表示与关系,Nbp 表示下一邻接点,∇表示终止该方向遍历。
3)对当前点Pi 执行N次操作按公式(2)确定遍历终点,其计算公式如式(2):
式中:Pi (1) 表示遍历初始点,Pi (N ) 表示遍历N次终点,⇒ F 表示执行N 次遍历起始点和终点重合时执行下一公式(3),Ω表示执行N 次遍历起始点和终点不重合时保留遍历过的骨架线点。
4)在起始点和终点重合时,执行设计的判别机制,其计算公式如式(3):
为验证提出算法的有效性,选取HWDB文字数据集中的汉字进行对比分析,图2为本文算法相较于文献[3]、文献[5]和文献[7]算法的文字细化实验对比结果。
从人眼视觉关注机制主观分析,图2中本文提出的改进的文字骨架线提取算法能够获得质量更高的文字骨架线。相较于文献[3]、文献[5]和文献[7]的算法,该算法能很好地消除局部信息缺失和毛刺现象,实验效果更佳。
2 提出的文字骨架线定位算法
针对文字骨架线定位精准度问题,许多学者提出了改进的算法。Han等[10]基于缩放因子提出了优化的特征点定位算法,但单一缩放因子难以实现精确定位且定位准确率不高。本文采用提出的自适应参数估计算法来确定细化后文字骨架线的位置。该算法基于三维空间到二维空间的映射机制,根据坐标参数确定细化后文字骨架线点的实际位置。首先,对提取的文字骨架线点根据似然函数定义确定似然函数参数方程组;然后,对似然函数参数方程组求极值,得到方程组的驻点,即为极大似然函数估计值;最后,根据三维空间到二维空间的映射机制,由估计值确定二维空间坐标点,最终确定文字骨架线的实际位置。
1)首先,细化前文字在三维空间的坐标点Pi 可定义为(αx,βy,γz),细化后文字在二维空间的坐标点可定义为(k1x1,k2 x2 ),则三维空间到二维空间的映射公式如式(4):
对方程组(7)求解得到驻点,记为α'、β'、γ',则α'、β'、γ'即为参数估计值。根据公式(4)即可确定k1、k2的数值,进一步确定骨架线点的坐标位置,最终得到细化后文字骨架线在二维空间的实际位置。
综上所述,根据在二维空间实际位置确定的文字骨架线,按出栈顺序进行合并,最终得到细化后的文字骨架线真实位置。
为验证提出算法的有效性,在提取文字骨架线的基础上,将提出算法与文献[11]、文献[12]和文献[13]中的算法进行对比分析。图3为4种算法的实验对比结果。
从图3中可以看出,本文提出的算法相较于其他三种算法能够更精确地定位文字骨架线的特征点。相较于本文提出的算法,文献[11]和文献[12]的算法在特征点定位上存在较大偏差,而文献[13]的算法在定位精度上有所改善,但其定位效果仍不如本文提出的算法。
3实验结果分析
3.1实验参数与评价指标
为验证本文算法的有效性,在以下硬件配置环境中进行仿真实验:Intel(R) Core(TM) i7-8700,主频为3.2GHz,内存为16GB;软件配置为:Microsoft VisualStudio 2010 和 OpenCV 2.4.10。测试时采用 HWDB 提供的汉字数据集。为评估本文提出算法在不同汉字数据集下的细化性能,使用细化率、相对误差和细化节省时间 T (%) 作为提出算法提取骨架线质量的优劣指标;使用准确率(Precision,PR)、召回率(Recall,RE)以及 F-评价值(F-Measure,FM)作为提出算法综合性能的量化指标[14]。
其中,细化率表征删除的前景像素点与所有前景像素点的比值;相对误差表征获取特征点相对实际特征点位置之间欧式距离相对模型最大边长的百分比。
3.2 实验结果分析
为定量分析本文算法提取文字骨架线的效果,在4种不同分辨率共100组测试数据集下,基于细化率指标与文献[3]、文献[5]和文献[7]中的算法进行对比分析。表1为本文算法相较于其他3种算法的实验对比结果。
从表1中可以看出,本文算法在4组不同分辨率文字数据集下的细化率结果均大于文献[3]、文献[5]和文献[7]的算法实验数值。这表明本文算法对于不同分辨率的文字具有更高的识别精度和更佳的细化效果,能够进一步消除像素缺失或毛刺现象。对于不同分辨率的测试数据集,细化率有所差异,这是由于分辨率越高的文字其边缘像素饱和度越高,但不影响本文算法自身较高的鲁棒性。
在实验结果较佳的基础上,为进一步验证本文算法的适用性,采用细化节省时间(T(%))表征本文算法的算法复杂度。
表2给出了本文算法相较于文献[3]、文献[5]和文献[7]算法的实验结果。从表2中可以看出,本文算法相较于其他3种算法在一定程度上节省了细化时间。
这表明在细化结果得到较大改善的情况下,本文算法能够在一定程度上节省细化时间。
为进一步验证本文算法在骨架线特征点定位精度上的准确性,在8组不同的文字测试集下,针对文字在骨架线端点、骨架线上以及孤立点三种状态的相对误差进行了测试分析。图4展示了4种算法在骨架线端点、骨架线上以及孤立点三种状态下的相对误差对比结果,其中横坐标数字表示测试序列编号。
从图4中的分析可知,本文算法在骨架线端点、骨架线上点以及孤立点三种状态下的相对误差均小于其他3种算法,这表明本文算法在文字骨架线特征点定位精度上更高,即本文算法对于细化文字的还原度更真实。相较于骨架线端点和骨架线上点两种状态,在孤立点状态下,本文算法的相对误差范围更小,误差范围不高于0.8%,这依然证明了本文算法在文字细化方面的优越性能。
为综合考量本文算法的整体性能表现,在准确率、召回率以及F-评价值评估指标的基础上,本文算法与文献[3]、文献[5]和文献[7]中的算法进行了对比分析。图5为本文算法相较于其他3种算法的实验对比结果。
通过对图5中的数据进行分析,在准确率方面,相较于文献[3]算法、文献[5]算法和文献[7]算法,本文算法的PR 值更高,表明本文算法在文字骨架线提取方面具有更高的准确性,即本文算法在文字骨架线的识别率上更具优势。在召回率方面,本文算法的实验结果更为可观,这是由于本文算法在文字细化结果的真实性上具有较强的普适性。相较于其他3种算法,本文算法的FM 值最高,这表明本文算法在文字细化整体性能上表现最佳。综上所述,本文算法在文字骨架线提取方面具有更高的准确性和鲁棒性。
4 结论
本文提出了一种改进的骨架线提取及特征点定位算法。该算法首先基于深度优先遍历及四邻域特性设计了一种优化的遍历规则,以提取文字骨架线,在节省一定细化时间的情况下能够获得主观质量更佳的文字骨架线。然后,结合极大似然估计和空间映射关系,设计了一种骨架线定位算法,可以在确定骨架线特征点的基础上获得还原度更高、稳定性更强的文字骨架线。
实验结果表明,本文提出的算法能够获得质量更佳的文字骨架线,在误差极低的情况下确定骨架线特征点,并还原真实的文字骨架线。