基于改进型YOLOv8的复杂环境烟火检测
作者: 周杰洋 李扬 李必云
关键词:烟火检测;条件参数化卷积;特征;Yolov8;深度学习
中图分类号:G642 文献标识码:A
文章编号:1009-3044(2024)18-0030-04
0 引言
近年来,由于全球变暖趋势更加显著,导致诸如厄尔尼诺与拉尼娜现象愈发强烈,全球范围内诸如极端干旱与极端炎热天气出现的频率、发生强度与持续时间也在不断上升。根据红十字与红月会国际联合会(IFRC)等机构共同公布在联合国减少灾害风险办公室(UNDRR)统计数据,2020至2022年以来,全球范围内发生野火灾害40余次,共造成274人死亡,影响近110万人,并造成高达数百亿美元的经济损失[1]。
清华大学深圳国际研究生院郑博团队等的研究表明,极端野火普遍性逐渐上升。当野火侵入泥炭地、森林等富含碳、具有较强碳汇功能的生态系统,不仅直接产生大量碳排放,导致泥炭地大火、毁林、森林退化等严重自然灾害,也使野火燃烧过程释放的碳难以被吸收,甚至会阻碍生态系统的恢复与重建,削弱陆地生态系统的碳汇能力,阻碍农业发展[2]。检测与防范野火发生与和蔓延在各国公共基础设施建设中处于战略性地位。
野火导致的火灾发生时,烟雾通常先于明火出现,可作为一种火灾发生的标志[3]。野外火灾烟雾检测研究已经证明了各种检测模型的有效性,取得了良好的结果。而野外环境复杂的背景和烟雾特征提取的困难导致了许多早期检测挑战,如云、水面或雾,这些元素使野外火灾烟雾区分困难,自然光照变化的相互作用进一步加剧这些问题,引发影响下游特征提取和识别过程的图像属性变化。基于YOLO模型[4]进行增强改进,使用预训练的权重作为底层网络的基本参数,调整网络架构参数,以优化传统的YOLOv8模型的效能,从而进行野火烟雾监测。通过将这个改进的网络架构整合到与森林火灾烟雾相关的数据集中,实现了对危险排放物如烟雾的精确识别。
1 相关研究
基于无人机与监控等拍摄的图像与深度学习模型进行研究,为提升对于复杂环境下的野火烟雾的早期检测的准确性与及时性,通过引入CondConv对原始的YOLOv8模型进行优化,从而提升模型的准确率与收敛速度。
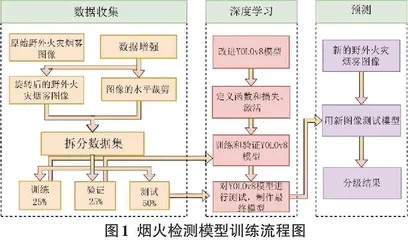
图像收集后,需对图像进行必要的预处理优化与特征增强,并将任务所需识别的目标像素与周围背景分离。这一过程中涉及烟雾和火的特征提取包括在特定白天和光照条件下捕获的图像,其中边缘、角点、运动、颜色属性、亮度级别和强度等方面被视为特征提取过程的组成部分[6]。为了全面研究分割图像并识别重要的关键点,图像经历特征提取相关程序操作。处理后的图像随后被输入到经过训练的模型中,用于对模型进行检验。具体流程如图1所示。
2 材料与方法
2.1 YOLOv8算法
YOLO模型是一种基于深度神经网络的对象识别和定位算法,运行速度快,可以用于实时系统,在计算机视觉领域被广泛引用。在此基础上,众多学者对其进行研究与改进,提出了多种新颖的改进模块与方法。YOLOv8于2023年1月10日由Ultralytics推出,标志着这一演进的重大进展。其网络主要由Head、Backbone与Neck三部分所构成[7]。
在YOLOv8中使用改进后的CSPDarknet53[8]作为主干网络,并通过五个连续的下采样阶段生成五个不同的尺度特征。在之前的主干结构中,其主要是通过借助CSPNet提取分流的思想,同时结合残差结构思想,设计C3 Block,这里的Cross Stage Partial(CSP) 主分支梯度模块为BottleNeck 模块,就是残差模块。在YOLOv8的主干结构中,通过ELAN对C3模块进行改进并最终设计出C2f模块,使得其能在保证模型轻量化的同时获得更为丰富的梯度流信息。其次,YOLO 框架最为重要的设计则是其设计了Spatial PyramidPooling(SPP) 结构[9]。在骨干网络的后期使用了空间金字塔池化快速(SPPF) 模块,通过三个连续的最大池化层自适应地生成具有一致大小的数据,从而池化输入特征图。与空间金字塔池化(SPP) 结构相比,SPPF 通过一系列连续的最大池化层优化计算效率并减少了延迟。
借鉴PANet[10]思想,YOLOv8在其颈部组件中引入了PAN-FPN架构。与YOLOv5和YOLOv7模型中的颈部设计不同,YOLOv8通过消除PAN结构内部上采样后的卷积操作,实现了更简化的配置,同时保留了模型的初始性能。这一策略构建了一个综合的网络结构,统一了自上而下和自下而上的组成部分。通过特征融合,它结合了表层位置洞察和深刻语义细节,从而丰富了特征的广度和深度。
在头部结构上,YOLOv8使用Decoupled-Head和Distribution Focal Loss(DFL) [11],用于目标分类和边界框回归的预测。此外,YOLOv8还改进了损失函数的使用。具体而言,其分类损失为VFL Loss,其回归损失为CIOU Loss联合DFL的形式。VFL主要改进是提出了非对称的加权操作,FL和QFL都是对称的。相对于DFL,其主要是将框的位置建模成一个 generaldistribution,让网络快速聚焦于和目标位置距离近的位置分布。与此同时,分类任务受到二元交叉熵损失(BCE损失)的支持。这一设计有助于提高检测精度加速模型的收敛。YOLOv8是一种无锚检测模型,简化正负样本的区分。整合Task-Aligned Assigner[12]以进行动态样本分配,从而提高了检测的准确性和模型的鲁棒性。
2.2 CondConv
在卷积网络中,使用常规卷积进行构建网络时候, 有如下假设:所有的样本共享卷积网络中的卷积参数。因此,为了提升模型的容量,就需要增加网络的参数,深度,通道数,这将导致模型的计算量和参数量增加,模型部署难度大。然而,在某些计算机视觉应用中, 要求模型的实时性高,这就需要模型拥有较低的参数量和计算量。
为了打破传统卷积的特性,Brandon Yang等人将CondConv中卷积核参数化为多个专家知识的线性组合[5]。并通过提升专家数量提升模型容量,同时因为专家知识只需一次线性组合,故可提升模型容量的同时保持高效的推理。
如图2(a) 所示,CondConv采用更为细粒度的集成方式并利用Combine与卷积都为线性计算的特性,将多套权重加权组合之后,只做一次卷积就能在有效降低复杂度的同时完成相当图2(b) 中所示结构的效果。CondConv在卷积层设置多套卷积核,在推断时对卷积核施加单层全连接,根据卷积层的输入决定各套卷积核的权重并加权求和得到一个为该输入量身定制的一套卷积核,最后执行一次卷积即可。将该过程的公式化如式(1) 所示。
在该计算过程中先对输入做全局平均池化得到向量,然后通过一个全连接层得到一个n 维向量(对应n个专家的加权值),然后再过Sigmoid函数将值约束到[0,1]中,从而作为n 个卷积核参数的加权权重。CondConv具体实现流程如图3所示。
2.3 基于YOLOv8的特征融合网络结构设计
为了增强特征融合网络(Feature Pyramid Net⁃works,FPN) 的特征融合能力和网络的预测能力,对Backbone部分进行了修改。具体来说考虑到实际场景中烟火为非刚性物体,目标大小变化较大,针对存在小目标的情况,且火灾检测对识别的实时性存在较大的需求,引入CondConv提升模型对烟火的识别实时性,如图4所示。
3 实验结果
这一部分详细描述了超参数设置、所使用的训练与测试数据集、实验硬件配置以及用于测定改进的YOLOv8模型在数据集中识别野火烟雾效果的验证过程。为确保所提出的方法的可靠性,所有实验均在一致的硬件条件下进行。实验是在一个自组装的计算机系统上进行的,具体规格包括16GB显存的NvidiaGeForce 4060Ti图形处理单元、32 GB内存和5.6 GHz、20 核CPU 的intel core i7 processor 14700K。改进的YOLOv8模型的输入图像来自一个森林火灾烟雾数据集[13],每个图像都被调整为640×640像素的尺寸。综合评估包括多个方面,涵盖了实验设置和设计、YO⁃LOv8性能分析、方法影响评估、模型比较、消融研究和可视化结果。用于检测野火烟雾监测的模型训练过程中使用的参数如表1所示。
3.1 评估指标
研究依赖于由中国科学技术大学火灾科学国家重点实验室提供的公开野火烟雾数据集以及私有数据集,混合数据集共拥有野火烟雾图像1181张。
检测器准确性的评估通常涉及评估其正确识别实例的能力,且模型的召回率表示其准确预测与总数之比,因此二者可充当其在识别事件方面的能力的关键度量。此外,具有较高召回率的模型能够有效检测大量与火灾相关的图像,同时通过专注于相关目标而保持精确度。本研究中准确度和召回率的计算基于方程式(3) 和(4) ,用于评估烟雾检测方法的准确度和召回率。
3.2 实验结果分析
定量评估旨在全面评估所提出方法的有效性,通过式(3) 至(6) 计算了多种指标,包括精确度、召回率、mAP50 和 mAP50-95。为了应对数据集中烟雾实例的多样性,涵盖不同距离,并包括小区域和大区域,对各种 YOLO 系列模型进行了系统和全面的测试。主要目标是确定一种能够在野火环境中准确检测烟雾的有效方法。
主要关注利用深度学习模型进行野火烟雾检测,特别强调减轻对森林生态系统的影响并确保人类安全。在经过彻底的数据集评估后,因其在迅速检测不同大小和方向的烟雾实例方面的效率,选择YOLOv8 作为主要框架。与通常在该领域使用的更复杂的多阶段目标检测器相比,单级检测器如 YOLOv8 在即时和实时应用方面更为合适。基于 YOLOv8 构建的提出的森林烟雾检测模型在多个性能指标上展现了显著的改进,在精准度与mAP50-95没有显著变化的前提下,略微提升了召回率与mAP50,降低了模型的复杂度且有效提升了模型识别的实时性,此外,模型还拥有着更快的收敛速率。
为了全面评估所提出方法的有效性,分析涵盖了各种目标检测技术及其修改,包括YOLOv5[14]与YO⁃LOv8[7]。改进的CondConv模型与各种目标检测器在野火烟雾数据集上的比较性能分析详见表2和图5。
YOLOv8-CondConv 在收敛速度上相较原始的YOLOv8与YOlOv5相比,具有更高的收敛速度,如图5 所示。其次,表2表明,YOLOv8- CondConv表现出平均均值精度(mAP)的mAP50达到99.499%且mAP50-95达到97.392%,识别达到99.539%的同时模型召回率也提升至99.746%。其识别精度与mAP50-95略微低于YOLOv8但高于YOLOv5,其召回率、mAP50都高于YOLOv8 与YOLOv5。此外,YOLOv8-CondConv 模型复杂度显著低于YOLOv8的同时FPS接近于原始YOLOv8的125%,在保持识别准确性的同时具有更强的实时识别性能,更适应于火灾早期的快速检测。
在使用定量评估方法测试野火烟雾检测方法的效果时,也进行了定性分析。如图6所示,从数据集中选择16张展示了由野火引起的较小且突发的烟雾柱的图像,其中包含被部分遮挡的图像与远处突发的烟火图像,改进后的 YOLOv8 模型可靠地提供了这两类情况的结果。
4 总结
在野火预防和管理领域,对烟雾的迅速检测至关重要,即使是微小的烟雾痕迹,如果处理不及时,可能引发灾难性的野火,威胁生态系统、自然资源和人类生命。本研究介绍了一种针对复杂森林环境中野火烟雾检测的改进型 YOLOv8 模型。野火烟雾检测算法在保持一致性性能方面面临的挑战源于适当训练图像的不足,导致过拟合和数据不平衡等问题。通过在Backbone区域引入CondConv,对识别图像数据中的小烟雾斑块方面表现出卓越性能:识别率99.539%、召回率99.746%、mAP5099.499%、mAP50-95 为97.392%、模型复杂度为7.8GFLOPs,模型每秒传输帧数为256.41。相较于原始的YOLOv8,新模型在精准度与mAP50-95没有显著变化的前提下,提升了召回率与mAP50,降低了模型的复杂度且有效提升了模型识别的实时性,其每秒传输帧数接近于原始YO⁃LOv8的125%,此外,模型还拥有着更快的收敛速率。
在自然环境中提高检测效果的关键在于丰富野火烟雾图像的多样性。后面的研究将致力于在保持模型紧凑性的同时加速检测过程,而不降低准确性,并通过引入多种数据源,如卫星图像和气象数据,用于提高检测系统的精度和可靠性。