医疗信息系统中基于关键词和特征向量拼接的数据定位方法
作者: 叶章辉
关键词:医学数据处理;词向量;向量拼接
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2024)18-0064-03
0 背景
在智慧医疗领域中,医疗与互联网技术的结合为医疗行业带来了许多新的机遇和挑战[1]。智慧医疗的概念涵盖了诸多方面,包括电子病历、远程医疗、健康监测等,整合海量数据信息并实现医学数据收集和分析,为临床实践和决策起着重要的作用[2]。其中,医院信息系统作为支撑智慧医疗的重要组成部分,也在不断地更新和发展。在医院信息系统中,信息的整合和提取成为一个关键的步骤,尤其对于临床研究所需的数据往往需要从多个系统中收集。由于不同系统之间的数据格式和结构各异,基数据集之间缺乏关联关系,这给信息查询和匹配带来了困难。跨系统信息提取和整合对工程师的能力提出了更高的要求。针对缺少关联关系的基数据集,单纯通过人工遍历的方式进行信息查询,不仅效率低,而且准确率难以得到保证。对于医学研究而言,信息的准确性尤为重要。基于上述需求,能够准确高效地整合多系统数据关联信息成为一个极为重要的研究方向。
1 研究现状
传统的人工遍历搜索方式在进行信息查询和匹配任务时,匹配的效率较低且匹配准确性难以保证。因此,研究人员采用了各种技术方法来解决该问题。数据库中各表所存储的信息多为文本和数值数据,所以文本处理技术被广泛采用,将数据集中的文本内容进行关键词提取,然后把各表格数据转化为特征向量,再通过向量的相似性计算来实现数据查询匹配任务。向量的相似性计算是一种常见的方法,可以通过余弦相似度或者欧几里得距离来计算特征向量之间的相似度,并以此来确定向量间的匹配程度。
然而,仅基于相似性计算存在局限性。它依赖于特征向量的表征能力,无法提供较高的匹配准确率。为了提高效果,一些研究采用机器学习算法实现信息匹配和查询任务。QUELLEC G等[3]介绍一种基于机器学习算法的案例查询算法,通过调整决策树的结构降低查询的次数同时提高查询的效率。QUELLEC G 等[4]通过基于贝叶斯网络的样本匹配算法计算出样本匹配度,再将基于置信度的模型进行异构特征的类比,利用推理方法提供了解决方案,并取得了较好的查询性能。然而在超多分类的信息查询匹配任务中,模型的效果可能无法得到很好的保证。
另一方面,基于文本信息处理技术以及基于深度学习算法技术也被广泛应用于关键信息提取,可以为关联数据库的信息匹配提供有效的支持。王小华等[5]研究分析了基于文本信息抽取技术以达到提高文本信息关键内容的识别效率。汪少敏等[6]采用深度学习算法为非结构化的病例文书内容进行关键信息的提取。深度学习算法通常用于处理非结构化的文本数据,如医学文献、临床报告和电子病例等。在本文所研究的问题中,所处理的是结构化的数据,既可以是文本数据,也有可能是数值型数据,并不适用于深度学习算法模型的应用场景。
2 基于文本和数值的信息匹配方法
本文研究了一种医疗数据信息查询匹配方法。该方法能够在缺少表结构信息且只提供少量样本数据的情况下,准确快速地从数据库中定位目标数据所存放的表格位置。该方法可以处理的数据类型不仅包括文本,还包括数值型数据。通过获取文本的关键词和数值数据的特征信息构建特征向量,并通过向量拼接的方式将原来超大量级的多分类问题转化为二分类问题,从而提高建模计算的效率。下面将以医学研究的数据获取为例介绍该方法的实现方式。
首先需要确定需要进行定位匹配的数据库中表格集。将原始数据库中的表格数据称为基数据,即上文提到的缺乏表格关联关系的数据库表格集合。将基数据集中的每个表格中的每一列定义为基类,即每一列都可能是所要查找数据的基数据。用于查找的样本数据称为预测数据集。
2.1 数据集的导入
1) 基数据集导入:基于医学研究中遇到的信息提取和匹配需求,基数据集通常以二维表格形式存储在数据库中。表格数据为结构化数据,表格之间的关联关系可能已知,也可能缺失(本文介绍的方法适用于关联关系缺失的情况)。
2) 预测数据集导入:作为样本数据,为达到预期效果,测试集的样本数量应得到保障,同时样本数据应具有足够的代表性。
2.2 基数据集的词频统计
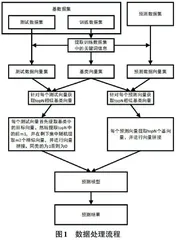
如图1所示,对基数据进行划分,并利用随机筛选的方法将提取的基数据分为训练数据集和测试数据集,对训练数据集进行首次遍历。
逐一遍历训练数据集中的每个表格,若表格的记录条数较多,可以通过随机抽样的方式选择一定数量的行进行处理,例如可以随机选择3 000条表征该表格的整体数据信息。为了降低单次计算时的内存资源消耗,设定单次读取表格中的固定行数(例如单次读取500行的表格数据)。然后再依次处理固定行数表格中的每一列数据,若为文本数据则先进行分词处理并统计每个词的词频信息,若为数值数据,则统计每个数值出现的次数。
2) 基类的类型判断,即确定表格中每一列是文本数据还是数值类型。主要通过文本类型和数值类型各自的占比进行评估。遍历基类中的每个样本,如果其内容不是数值型则判断该样本为文本类型;如果其内容是数值型,则进一步判定:对数值型设定一个取值区间(例如1e-6 ≤ X ≤ 1e6) ,如果落在该区间则认定为数值类型,否则判断为长数值型文本。最后设定类型占比的阈值(比如设定阈值为70%) ,遍历完基类的所有样本,若数值型占比大于该阈值则认定该列为数值类型,否则认定为文本型数据。以血常规检查为例,部分指标可能由于样本质量或系统原因导致数据异常,以“异常数据”或【<0.001】形式存储于数据库表格,造成该列既有数值也有文本。但若血常规结果集中数值类型占比较高,则认定该列为数值类型。
3) 针对被确定为文本类型的基类,须再次进行遍历操作。针对纯文本内容,通过自然语言处理中的分词操作对文本进行处理,例如“患者自述发热三天,服用泰诺没有得到缓解,至今还是发热”。经过分词操作得到:【患者,自述,发热,三天,服用,泰诺,没有,得到,缓解,至今,还是】共计11个词,对应的词频除了【发热】为2,其他词频为1。完成分词后,剔除停用词(如“这”“是”“的”等没有具体意义的词),从而获得文本基类的关键词集合。对于长数值型数据(如身份证、电话号码等),通过切片处理的方式获取固定长度的数字关键词。完成分词后,统计所有关键词的词频,假定基类关键词数量为keyword_num,设定筛选的关键词个数为TN,若keyword_num小于TN,则选择该文本列的所有关键词,否则取前TN个关键词。最后整合并去重所有文本类型基类关键词,形成基数据集的词袋(bag of word) ,作为特征向量的关键词维度。
4) 针对数值型的基类,采用统计学方法处理数据,首先排除基类中非数值型的样本数据,然后计算该基类数据的最小值、均值、最大值、四分位数和标准差,作为数值特征信息的特征向量。
2.3 基类向量集的生成
1) 通过2.2完成了每个基类的类型判断,并完成了文本类型基类的词频统计,得到该数据库所对应的词袋(bag of word),和数值类型的统计学特征数值。基类特征向量的维度包含:文本类型(T1) ,数值类型(T2) ,文本长度的平均值(T3),数值特征维度V1~Vm,关键词维度W1~Wn,其中V表示对应的数值特征维度上的取值,W表示特征词维度上的取值,得到的单个特征向量如公式(1) 所示。
(T1,T2,T3,|V1,V2,...,Vm,|W1,W2,...,Wn) (1)
2) 如果该基类是数值型数据,将文本类型的维度赋值为0,数值类型的维度赋值为1。文本长度的平均值为0,并添加最小值、均值、最大值、四分位数和标准差等统计指标,同时将关键词维度上的数值均设为0。
3) 如果该基类是文本型数据,文本类型的维度赋值为1,数值类型维度赋值为0。文本长度的平均值由计算得出,而数值统计维度均为0。关键词维度则基于该基类的关键词词频进行归一化处理,将归一化的数值赋值到对应的关键词维度中。
4) 将训练数据集生成的向量集称为基类向量集,测试数据集生成的向量集称为测试向量集,预测数据集生成的向量集称为预测向量集。
2.4 新类别特征向量生成
2.4.1 测试向量的相似向量集筛选
1) 遍历测试向量集中的每一个测试向量,利用向量相似性(如皮尔逊相关系数、余弦相似度等)计算其与基类向量集中非同源向量的相似性分数值。然后选取相似性得分排名前topN的基类向量,形成基类向量子集,通过该方法可以显著缩小单个测试向量的基向量集的范围。
2) 从基类向量子集中选择前m1个与测试向量最相似的基向量,标记为M1;再从剩余的基向量子集中随机选取m2个基向量,标记为M2;最后提取与测试向量同源的基向量,命名为M3。这一筛选方法帮助控制样本集中不同相似度样本的比例。理论上,M3是与测试向量最相近的(因为是同源数据),M1次之,M2与测试向量相似度最弱。该方法有助于减少待处理的基向量数量。
3) 将M1和M2中的每个基向量与测试向量进行拼接。原先单个向量的维度为(3+m+n),通过拼接组合,得到的向量维度变为2(3+m+n),其中前半部分为测试向量,后半部分为基向量。给拼接向量赋予一个类别标签,表示非同源数据为0。
4) 把M3 同测试向量进行拼接,操作同步骤3所述,为拼接向量赋予一个类别标签,表示同源数据为1。
5) 重复步骤1)~4),生成测试向量的新类别特征向量集。
2.4.2 预测向量集的相似向量集筛选
1) 依次遍历预测向量集中的每个预测向量,采用上个步骤中1所述的方法计算其与基向量集中所有基向量的相似性分数值。
2) 根据相似性分数值,从基向量集中选取前X个最相似的基类向量子集。
3) 将前X个基向量与对应的预测向量进行拼接,其中前半部分为预测向量,后半部分为基向量。同时记录下对应基类向量的类别标签,作为最终的类别预测结果。
4) 依次处理单个预测向量,得到一个包含X个拼接向量的集合,并最终生成新的预测向量集。至此完成了拼接向量集的生成以及待预测数据向量集的生成。通过控制m1和m2的大小,调整数据集中正负样本的占比比例,从而避免正负样本比例差异过大而影响建模效果。
2.5 建模与预测
1) 建立预测模型,将基于测试向量集生成的新类别特征向量集划分为新的训练集和新的测试集。采用分类算法进行建模,例如逻辑回归、随机森林和GBDT等。新的训练集用于训练模型,新的测试集用于评估模型效果。评估模型效果的指标包括准确率、精确率、召回率、F1 Score、ROC曲线和AUC值。
2) 完成预测模型构建后,依次将每个预测向量对应的X个拼接向量输入已训练好的预测模型中。预测的结果以概率值的形式返回,即每个拼接向量都返回一个概率,该概率值表示预测向量与所拼接的基向量相似(同源)的概率。然后根据预测概率值排序,选取概率值最大的前R个拼接向量,解析出其对应的原始基类,作为预测向量最可能对应的基类,完成数据查询匹配的任务。
3 结束语
本文介绍了一种基于表格数据进行关键词和特征向量拼接的数据定位方法。该方法不仅分析了表格中数据的类型信息,还整合了文本处理和关键词提取技术,并运用了统计学数值特征信息,从多个维度对表数据特征进行了表征。通过向量相似性计算进行基类的筛选,从而控制正负样本比例,并采用向量拼接的手段得到最终的拼接向量集。最后,利用分类算法建立预测模型,实现基于少量样本准确、快速和高效地定位数据源的目标。各大医疗系统通过多年的数据积累拥有海量的数据资源。要充分利用这些数据资源,对数据库信息必须有清晰的了解,才能更好地挖掘医学数据的价值。本文介绍的方法可以准确高效地进行医学数据查找匹配,一次处理、多次使用,提高了数据查找的效率,为临床研究人员的数据收集提供保障,从而更好地进行临床研究,更充分地利用积累的数据资源。