基于虚拟机调度策略的云计算Web应用资源弹性调度研究
作者: 肖志良 汪丽娟 郑雁予
关键词:虚拟机调度;云计算;Web;应用资源;排队论
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2024)21-0095-03
0 引言
在云计算环境中,资源的科学调度对任务完成时间以及服务质量具有显著影响,最终也会影响用户的体验。在特定的调度策略下,该策略直接决定了资源使用效率和资源分配方式,同时也与服务提供商的各项利益密切相关。资源弹性调度是指系统根据应用需求和服务质量目标,动态地调整计算资源分配的管理方式。在基于虚拟机(Virtual Machine, VM) 的云环境中,弹性调度策略尤为重要,因为它们能够在不同的资源需求阶段有效分配和回收计算资源。
李双刚等人[1]设计了一种自适应虚拟机迁移的总体框架,该框架通过对虚拟机迁移进行建模,提出了“迁移路径”和“服务开销”等概念,为系统中所有迁移的虚拟机规划最优的迁移路径,以最小化系统总的服务开销。测试结果显示,基于该框架设计的调度算法能显著减少云计算中的计算开销。然而,前人的研究在云计算Web应用资源调配方面仍有不足,因此本研究旨在进一步探讨和改进基于虚拟机的调度策略,以优化Web应用的资源配置,实现缩减成本、提升性能、保障服务质量的目标。
1 基于排队论模型的云计算Web 应用资源弹性调度方法
1.1 调度模型整体结构与排队网络设计
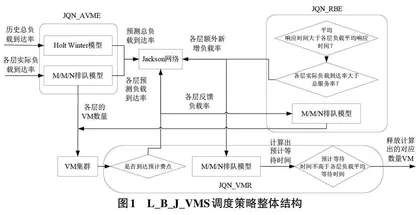
针对多层Web系统中各种依赖复杂导致的负载传递信息困难问题,此次研究设计出一种基于负载预测、瓶颈删除、Jackson排队网络的VM调度(Virtual ma⁃chine scheduling based on load prediction, bottleneck re⁃moval, and Jackson queuing network, L_B_J_VMS) 策略[2-3]。设计出的VM调度策略整体框架见图1。如图1所示,L_B_J_VMS利用排队论模型建立了一个开放的Jackson排队网络,用于模拟整个网状Web系统的负载处理,这一网络的基础是Jackson排队网络。VM 调整方法包括两种新增策略:基于Jackson排队网络的主动VM 扩展方法(Active VM Expansion MethodBased on Jackson Queuing Network,JQN_AVME) 和基于Jackson 排队网络的反应性瓶颈消除方法(A reac⁃tive bottleneck elimination method based on Jacksonqueuing network,JQN_RBE) 以及一种VM资源释放策略:基于Jackson排队网络的VM缩减方法(VM reduc⁃tion method based on Jackson queuing network,JQN_VMR) 。这些策略旨在保持各层负载的平均响应时间,以维护整个Web系统的平均端到端响应时间。在L_B_J_VMS中,JQN_AVME会提前供应资源,供应的依据是预测结果的负载量,而JQN_RBE这会按照设置的不变间隔对性能瓶颈进行识别,并开展消除处理,最后使用JQN_VMR方法判断处于预计费点的VM能否满足给定的释放条件,这将决定后续是否需要继续租赁操作。
首先设计排队网络。在Web应用中,各层对象的功能可能差异较大,因此需要处理由消费者或程序生成的各种类型的负载。这些负载被路由层根据需求分配到不同层进行处理,其中处理过程是随机的,但通常遵循特定的概率分布。许多研究假设负载到达间隔和服务时间遵循指数分布。L_B_J_VMS采用M/M/N模型对这些负载队列进行建模,形成一个包含K 层的开放Jackson排队网络。系统中每一层相当于信息网节点,负载会按照处理状态选择对应操作:负载处理结束后就会离开系统,若被设定继续处理,就会制造出额外的负载。由于路由层接收指定类型负载时存在一些随机特点,会引起负载在系统内部各层之间的转移也变得随机。这种负载转移可以通过具有有限状态的离散Markov随机过程来定量描述,从而得到表示负载模式的概率转移矩阵。各层的指定负载传递概率是按照之前的对应负载数据到达率计算出的。
1.2 预测供应策略设计
现在设计JQN_AVME方法。在考虑VM的创建和启动时,需要注意这个过程通常持续1到2分钟。这个时间特点非常重要,因为如果VM创建和启动的时间太长,可能会导致系统在处理负载时效率下降,进而影响整体性能。缩短这个过程的耗时,可以应对VM创建未完成时可能出现的性能折损问题。
一个有效的方法是通过分析历史数据来预测未来的负载到达率。由于负载的变化通常呈现出某种长期的周期性,可以利用时间序列预测算法来估计未来的负载情况。在复杂的网状多层Web系统中,考虑到负载规则存在变化可能,预测整个系统的难度相较于单一层面预测更简单、精确。因此评估各种时间序列计算算法和深度学习循环神经网络算法等多种预测方法后,这里选中能兼顾时间序列趋势和波动周期的Holt-Winter模型开展预测工作。这种模型能够提供关于未来时刻i + m 的预测值,帮助估计整个Web 系统预期的总负载到达率[4-5]。结合使用排队模型,能得到每层的预估待处理负载量。在M/M/N模型的基础上,每层的负载处理过程可以量化表示。假设每层中包含N 台性能相同的VM,每台VM的服务率确定时,可以计算出处理特定负载所需的平均等待时间。基于这些计算,可以确定各层待处理负载最大容许平均等待时间对应的最小VM数量。但是因为直接使用逆函数求解VM数量的计算复杂度较高,选择采用逐台递增VM数量的方式更为合适,计算将在预计的平均等待时间低于所允许的上限时停止。
至此,可以得到JQN_AVME 的整个计算流程:首先,按照之前的总负载数据到达率和Holt-Winter预测模型,计算出网状Web 的总负载率。然后,计算各层未来的负载率。再通过遍历搜索方式确定每层满足平均等待时间上限的最小所需VM数量,并根据各层现有的VM数量进行相应的调整。总的来说,通过JQN_AVME方法,可以有效地预测和调整VM的数量,以应对不断变化的负载需求,从而确保系统性能不受VM 创建和启动时间的影响。JQN_AVME方法通过对历史负载数据进行分析和预测,可以更加精准地匹配资源需求,从而优化整个系统的性能和资源利用率。
1.3 瓶颈消除策略与虚拟机释放策略设计
JQN_AVME的有效性主要由Holt-Winter模型对VM数量的预测精度决定。但考虑到负载的波动属性,预测值、实际值之间会存在一些误差。而且负载类型与用户需求关系密切,这些需求的改变往往代表着Web系统的负载模式也会反复波动。这些因素可能导致系统的VM供应低于最小容许值,从而违反与消费者签署的服务水平协议(Service Level Agreement,SLA) 。为此,系统的瓶颈需要被定期监控,同时通过有效应对方法来消除瓶颈,避免在去除瓶颈时在其他层引发新的瓶颈。
L_B_J_VMS策略的目标是通过维持各层负载的平均等待时间,满足整个Web系统的平均响应时间。当某层的平均响应时间超过SLA规定的限度时,该层被视为瓶颈层。如果JQN_RBE对应的VM数量能够处理各层的全部负载,基于M/M/N模型的各瓶颈层需要新增VM。如果某层的当前负载率低于现有VM的总服务率,则新增VM不会增加该层需要处理的负载。反之,如果当前负载率已高于现有VM的总服务率,则负载队列长度将持续增加,并且新增VM会增加该层的负载率。这可能导致其他层的负载量增加,从而形成新的瓶颈。为了计算消除所有瓶颈后Web系统各层的最终预期处理请求率,需要考虑当前层新增VM 导致的负载增加以及其他层新增负载对该层的影响,这可以基于Jackson平衡方程获得。根据队列的不同状态,最终的处理请求率可能是层内实际负载与最终新增负载之和,或层内VM总服务率与最终新增负载率之和。
综上,JQN_RBE处理瓶颈问题的流程如下。第一步是比较各层的实际平均响应耗时和SLA上限来分辨瓶颈模块。第二步计算瓶颈模块预期的新增负载、各层的新增总负载、消除后总负载,并使用VM遍历搜索方法再次获取消除瓶颈后各层VM需求,目的为各层新增VM提供依据。
JQN_VMR策略的目的是避免由于释放VM和频繁创建带来的租赁代价上升与性能变化。JQN_AVME、JQN_RBE策略只会按照预估的负载到达率来设置增加VM。VM的释放操作仅在达到预定的计费点并满足释放条件时进行。释放VM必须满足:删除某VM后,所在层的剩余VM也能处理预计后续的负载到达率。考虑到JQN_AVME 和JQN_RBE 策略对VM数量的调整,需要计算不同时间间隔内的预测负载到达率、处理系统瓶颈后的负载到达率以及实际接收的负载到达率。如果满足条件,VM在达到计费点时可以被释放;否则将继续租赁直到下一个计费点。
2 云计算Web 应用资源弹性调度方法性能测试
2.1 性能测试实验设计
为测试此次设计的模型性能,现在设计并开展一项实验。在实验平台上,随机选择2023年10月8日至2023年10与16日的实际Wikipedia负载数据来评估各算法。通过分析Wikipedia访问记录,将每个请求视为一个独立会话,并根据其URL的文件夹层次对请求进行分类,也即构建了一个拥有9层结构的网状Web系统,每层具有不同功能并模拟租赁Amazon EC2 上的同构VM。由于不同请求的大小不一,每个层级的VM服务率和子SLA也各不相同。
使用基于CloudSim开发的复合层次Web模拟系统进行测试,测试环境是Eclipse,编码JDK选用1.8.132-Bit版本。出于模拟请求暴涨带来的负载模式现象、用户在Web网页的日常访问模式(例如上午和下午的高峰期)目的,模拟实验中对某层的请求率每24 小时进行两次调整,每次调整持续2小时,以模拟实际访问模式的波动。
2.2 性能测试结果分析
现在将前人设计的比例依据瓶颈消除策略(Pro⁃portional Provisioning Method,PPM) 、行业内常用的消息队列(Message Queue,MQ) 、内容分发网络(ContentDelivery Network,CDN)、轮询调度(Round Robin,RR)作为对比的云计算Web应用资源弹性调度方法开展性能测试实验。由于云计算Web应用资源调度的目的是减少云计算数据传输耗时,因此这里选用请求端到端的平均响应时间作为对比指标,统计结果如图2所示。图2中,横轴代表测试开始后的时间,单位为分钟,纵轴代表各实验方案计算得到的请求端到端的平均响应时间,单位为秒,不同的线条样式代表不同的调度算法。观察图2可知,测试开始后,各调度算法的端到端的平均响应时间并未无显著变化趋势。整个实验过程中L_B_J_VMS、PPM、MQ、CDN、RR 调度模型的请求端到端平均响应时间分别为13s、32s、61s、31s、39s,可见此次研究设计出的调度模型调度效果最好。
3 结束语
针对云计算Web应用资源调度中存在的响应速度慢,VM资源调度利用水平不足的问题,此次研究设计了一种基于排队论模型的云计算Web应用资源弹性调度模型。测试结果显示,整个实验过程中L_B_J_VMS、PPM、MQ、CDN、RR调度模型的请求端到端平均响应时间分别为13s、32s、61s、31s、39s。可见此次研究设计出的调度模型处理后的系统云计算请求端到端的平均响应时间整体低于常见的调度模型,调度效果最好。但此次研究由于条件所限,未能将设计的模型在多种不同云计算场景下开展运算测试,这也是未来研究需要关注的方面。