基于深度学习的船舶识别算法研究
作者: 王静举
摘要:目标检测是深度学习最重要的任务之一,在各种应用场景都发挥着重要作用,比如:人脸检测、车辆自动驾驶检测、遥感检测等。本文以 YOLOv8 模型为基线,探讨深度学习算法在船舶识别领域的应用,以完成对图像中船舶目标的精准检测与识别任务,实现端到端的训练目标。基于 PyQt5 设计了用户操作界面,用于系统的展示和测试。实验测试结果表明,改进后的方法在计算量略微下降的同时提升平均精度到84%。
关键词:深度学习;目标检测;船舶识别;YOLOv8
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2024)23-0037-05
开放科学(资源服务)标识码(OSID)
0 引言
0.1 研究背景及意义
随着中国海洋强国建设的推进,船舶数量和种类不断增加,相关工作部门对船舶监控需求日益增长。本文旨在研究船舶识别算法,通过分析船舶形状实现对船舶种类的准确识别,以提升船舶监控的能力[1]。首先,船舶识别技术能够帮助监测船舶在海上的位置和移动情况,提高海上交通的安全性。通过实时监控船只的位置和航行情况,可以及时事故的发生,有效保护船员和船只的安全。其次,船舶识别系统可以帮助管理者更好地了解船只的分布和航行情况,提高海上交通的管理效率,优化通航路径,从而提升海上交通的运行效率和服务水平。此外,船舶识别技术也有助于发现和防止非法捕捞、海上污染等其他破坏海洋环境的活动。因此本文研究具有重要的研究意义。
0.2 基于深度学习的船舶识别算法应用挑战
通过对船舶识别领域的研究现状可以看出,船舶识别在深度学习的领域发展迅速,对不同情况下的船舶识别有不错的效果,但仍然存在以下一些问题和难点:
(1) 因为目标之间大小差异过大且模型对目标信息级别的区别能力不够,小目标检测精度不够;
(2) 由于模型的参数量大且计算量大,存在模型训练效率不足的问题;
(3) 由于数据集背景目标远多于前景目标,导致困难样本多,模型泛化能力不足。
本文针对以上三个难点进行研究,对网络的改进包括构建更加高效精准的网络模型、设计轻量化模块、更换更加高效的损失函数。为此,本文引入了 GD(Gatherand-Distribute) 机制以提高网络检测头对不同大小目标的检测精度,还采用了基于 Fasternet更加快速高效的模块。
本文采用基于深度学习的船舶识别算法,旨在提高海洋监控和安全管理的智能化水平,为实现海洋强国战略目标和维护海洋生态环境健康做出积极贡献。而通过科技创新,旨在为海洋安全与环境保护事业注入新的动力和活力。
1 YOLOv8的基本原理
YOLO 算法的工作原理是将输入图像划分为多个固定尺寸的网格格点,每个格点负责预测其区域内可能存在的物体的边界框和类别概率。YOLOv8 采用了当前流行的解耦头结构(Decoupled-Head) 来重新设计检测头(Detection Head) [2]。这种结构将分类和检测任务分离开来,同时还将目标检测从基于 Anchor 的方式转变为基于 Anchor-Free 的方式。解耦头的核心理念是在图像分割中引入额外的分支网络,该网络专门用于像素级预测,两条并行的分支分别提取类别特征和位置特征,然后各用一层1×1卷积完成分类和定位任务。这种设计使得模型能够更有效地利用不同层次的语义信息,从而提高分割结果的质量和细节保留能力。
为了进一步提升 YOLOv8 在船舶识别任务上的性能,本文对其进行了以下改进:
1) 引入基于 Fasternet 的 c2f-Faste r模块替换原有 c2f,通过PConv 减少计算量和模型大小,提高精度1.6%。
2) 采用华为提出的 GOLD-YOLO 中的 Gather-and-Distribute机制改进 Head 检测头,增强对不同大小目标的检测能力。
3) 引入 EMASlideLoss 损失函数,结合融合指数移动平均(EMA) 概念和滑动损失机制,提升模型精度和泛化能力。
具体改进和训练过程如下。
2 YOLOv8的改进和训练
2.1 c2f-Faster Block
2.1.1 FasterNet和FasterNet Block
FasterNet 是一种新的神经网络架构,旨在提高运行速度并对许多视觉任务非常有效。这种架构通过使用新型的 PConv(Partial Convolution) 和现成的 PWConv(Pointwise Convolution) 作为主要的算子,进一步提升了其性能[3]。而 FasterNet Block 中最重要的组件就是 PConv,PConv 在减少冗余计算和内存访问量的同时,能够保持高效的空间特征提取能力。PConv 的 FLOPs 更低,这是因为常规卷积和深度卷积对内存的访问次数远高于 PConv。因此,PConv 的网络延迟更低。
FasterNet 最核心的模块就是 FasterNet Block,由激活函数、归一化层、一个3×3的 PConv、两个1×1的 PWConv 卷积组成。 PConv 通过仅对输入特征图的一部分通道应用常规卷积,而保留其余通道不变,从而减少 FLOPs 和内存访问,而 PWConv 用于在 PConv 之后进一步提取特征,同时保持网络的轻量化。总的来说,FasterNet Block 的设计既保持了特征提取的能力,又降低了神经网络的延迟,使得网络更加轻量化。
2.1.2 基于FasterNet改进的c2f-Faster Block
YOLOv8 的 c2f 模块中堆叠了大量 Bottleneck 组件,这使得网络深度足够深,模型性能也会变好,但是模型的参数和计算量却居高不下,为了实现模型网络轻量化,本文在减少计算量和内存访问方面进行了研究,将 YOLOv8 中 BackBone 和 Head 中的 c2f 中的 Bottleneck 替换成基于 FasterNet 的 FasterNet Block,形成了称为 c2f-Faster Block 的新模块。
本文通过引入 c2f-Faster Block 这个创新结构,成功降低了网络模型的计算复杂度和内存访问量,提高了网络在轻量化方面的性能和效率。这些创新对于在资源受限的移动设备上部署深度学习模型具有重要意义,能够加速模型推理速度并减少能耗消耗,推动了深度学习技术在船舶识别算法应用中的可行性和普及度。
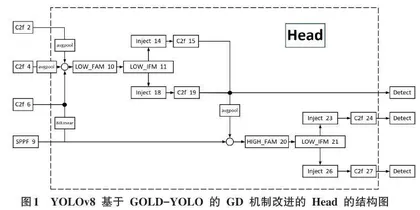
2.2 YOLOv8改进的Head
2.2.1 GOLD-YOLO和GD机制
Gold-YOLO 是一种高效的目标检测模型,由华为诺亚方舟实验室的研究者开发,旨在提升多尺度特征融合的能力[4]。Neck 网络是 Gold-YOLO 的核心创新所在,它使用 GD 机制来增强不同尺度特征的融合。GD 机制包含以下这几种模块,这些模块的组合可以改善不同尺度特征的融合问题。
低层 GD 分支专注于小目标和中等大小目标的检测,它使用Low-FAM(Low Feature Alignment) 和 Low-IFM(Low Information Fusion Module) 来处理从 backbone 提取的 B2,B3,B4,B5 特征图。高层 GD 分支专注于大目标的检测。它将 Low-GD 生成的 P3,P4,P5 特征图进行融合。
2.2.2 基于GOLD-YOLO的GD机制的改进的Head
本文通过引入 Gather-and-Distribute (GD) 机制来改进 YOLOv8 Head部分。YOLOv8 的头部结构被重新设计,以适应 GD 机制,改进后的 Head 的结构如图1所示。新的头部结构包括了专门用于实现 GD 机制的模块,如 Transformer 模块,这些模块能够处理和融合来自不同层级的特征。高效的特征提取:通过 GD 机制,YOLOv8 的头部能够更高效地提取和利用不同级别的特征,这对于提高模型的检测速度和准确性至关重要。
2.3 损失函数EMASlideLoss
YOLOv8 原本的分类损失函数是 Sigmoid 激活函数和二元交叉熵损失的结合,如公式(1) 所示。
[Lossx,y=-1Ni=0n[yilog (σ(xi))+(1-yi)log (1-σ(xi))] ] (1)
本研究针对样本不平衡问题,将 YOLOv8 原分类损失函数结合了指数移动平均(EMA) 的概念和滑动损失(Slide Loss) 的机制[5]。EMA是一种对时间序列数据进行平滑的方法,它通过给过去的观测值赋予指数递减的权重来计算加权平均值。在本次改进中,EMA 用于平滑 IoU 阈值,使得损失函数可以逐渐适应模型在不同训练阶段的性能变化。Slide Loss 机制的核心是动态调整损失函数的某些参数,以适应模型的学习进度,损失函数就是根据预测框与真实框之间的 IoU (交并比)大小来区分简单样本和困难样本。
设置衰减函数用于计算衰减值,如公式(2) 所示,x 是当前的更新次数或训练步数。decay 是初始衰减率,一个介于0和1之间的常数。τ是时间常数,控制衰减速度的参数。衰减值是用于控制不同时期的 [iou当前] 对 [ioumean] 的影响,如公式(3) 所示,指数衰减提供了一种平滑的过渡方式,避免了在训练初期由于数据的随机性而导致的 [ioumean] 的剧烈波动。
[d=decay×(1-e-xτ)] (2)
[ioumean=d×ioumean+ 1-d×iou当前] (3)
调制因子的作用是实施滑动损失机制,即根据模型对样本分类的难易程度来调整每个样本损失的权重,如公式(4) 所示。x 是预测框与真实框之间的 IoU 值,[ioumean] 是动态计算的阈值。当 x 远低于 [ioumean] 时,这些样本为负样本,权重为1,意味着它们对总损失的贡献较小。当 x 的值和 [ioumean] 的值相近时,越近越增加权重,表示对这种模糊的样本有更多的关注。当 x 值大于 [ioumean] 时,该样本为正样本,应该鼓励关注,就会给一个较大的权重。
[a1=1,b1=1a2=e1-ioumean,b2=1 a3=e1-x,b3=1 x≤ioumean-0.1ioumean-0.1<x<ioumeanx≥ioumean] (4)
权重的调制对于训练过程至关重要,首先是平衡正负样本,在目标检测中,负样本(不包含目标的背景区域)通常远多于正样本(包含目标的区域)。调制权重可以帮助减少负样本对损失函数的贡献,从而避免模型对背景过拟合。其次就是关注难分类样本,通过为难以正确分类或检测的样本(如小目标、遮挡目标)分配更高的权重,模型可以更多地学习这些样本的特征,提高对这些情况的检测性能。公式如(5) 所示。
[modulatingweight=a1×b1+a2×b2+a3×b3] (5)
最后是对 YOLOv8 的原损失函数进行一个基础计算,公式如(6) 所示。
[Loss=Lossx,y×modulatingweight] (6)