基于Hadoop分布式架构的云存储系统设计
作者: 曹阳
摘要:为满足海量数据的便捷化、智能化存储和分析需求,充分发挥和利用Hadoop分布式架构的运行成本低、容错性高等优势,应用Hadoop分布式架构设计一款新型、先进的云存储系统,从系统架构设计和系统数据库设计两个方面入手,完成系统总体设计。根据系统功能列表,依次设计文件上传、文件下载、文件浏览、其他操作等模块。在Hadoop分布式架构的应用背景下,文章中所设计的云存储系统具有内存开销率低、集群读取效率高、安全可靠等优点,符合预期设计标准和要求。
关键词:Hadoop;云存储系统;预取缓存;数据读取
中图分类号:TP393 文献标识码:A
文章编号:1009-3044(2024)23-0046-03
开放科学(资源服务)标识码(OSID)
在智慧医疗、电商、网络社交媒体等行业的迅猛发展下,包括小文件在内的网络数据呈现出急剧增加的趋势,HDFS(分布式文件系统)在整个Hadoop集群中主要用于海量数据的存储[1]。然而,目前HDFS存储机制缺乏一定的健全性和完善性,存在集群文件规模不易拓展、内存消耗大、访问数据不便捷等问题。云存储系统的设计和应用可以解决这些问题。该系统主要运用Hadoop分布式架构、云存储等技术,具有运行性能高、文件读写速率高、访问效率快、存储能力高等特点,为实现数据安全化存储和管理提供重要的平台支持[2]。因此,在Hadoop分布式架构的应用背景下,如何科学地设计和实现云存储系统是技术人员必须思考和解决的问题。
1 相关技术介绍
1.1 Hadoop分布式架构概述
Hadoop作为一种重要的分布式系统基础架构,可以为用户提供存储平台和计算平台。Hadoop主要是由Apache基金会研发,主要包含以下两个组成部分:1) 分布式文件系统。分布式文件系统凭借着自身拓展性高、容错性强、可用性高等特点,被广泛地应用于集群设备数据分布式存储领域中。2) 分布式运算编程框架。分布式运算编程框架为开发人员提供多个接口,开发人员可以在无须了解底层实现细节原理的情况下,对分布式程序进行有效开发和设计。与其他传统分布式文件系统相比,Hadoop具有运行性能高、安全稳定、开源免费等特点,完全满足大数据时代海量数据存储和管理的需求。借助Hadoop技术,用户可以方便地完成Hadoop集群的安装和部署,这为后期构建分布式云计算平台和存储数据提供了重要的技术支持。
1.2 云存储技术概述
云存储技术主要是在延伸和拓展云计算相关技术的基础上形成的新型、先进产品形态。云存储作为一种常用的存储资源池,主要由数据存储设备、数据管理设备等组成。借助应用程序编程接口,云存储可以为用户提供灵活性强、公开透明的云系统,便于用户根据存储需求分配资源存储空间,实现最大化利用存储空间。此外,授权的用户可以通过互联网与云存储系统有效连接,随时随地存储和分析海量数据。云存储技术主要包含以下几种。
1.2.1 分布式存储技术
分布式存储主要是指使用网络存储的方式,将所需数据传输和存储到分布式服务器上。在数据存储过程中,借助分布式文件系统将数据存储到相应的服务器上,为用户提供强大的数据管理服务。为了确保分布式存储系统的设计质量,需要充分发挥和利用分布式存储技术的透明性、自治性等优势。
1.2.2 存储虚拟化技术
存储虚拟化是一种层次接口封装与抽象的过程。通过应用虚拟化技术,封装层次接口,可以减小系统硬件在容量、接口方面的差异性。然后,将虚拟化产品安装和部署到系统硬件上,确保硬件细节与业务相互分离。通过虚拟化技术,可以实现对系统硬件资源的虚拟化处理,为用户提供简洁友好、操作智能的人机界面。存储虚拟化作为一种常用的虚拟化技术,可以实现对各种虚拟化方法和相关先进设备的统一化存储。通过应用存储虚拟化技术,可以实现对存储资源的有效隔离,确保网络资源与存储数据分开,方便后期针对不同资源信息的管理。
2 系统总体设计
2.1 系统架构设计
本文系统设计主要运用B/S设计模式,将系统架构划分为以下几个层次:1) 用户访问层:该层次将系统操作界面简洁、友好地展示给用户,方便用户进行相关功能操作。2) 应用接口层:结合用户多样化的使用需求,提供相应的应用程序编程接口,并将用户的操作映射到分布式文件系统操作中,屏蔽底层架构的细节。3) 数据管理层:该层次包含分布式文件系统的操作接口,为系统的二次开发提供重要的技术支持。4) 存储层:存储层主要用于重要数据的存储,利用Hadoop框架,实现多个PC机的组合和使用,为用户提供更优质的分布式存储服务体验。
2.2 系统数据库设计
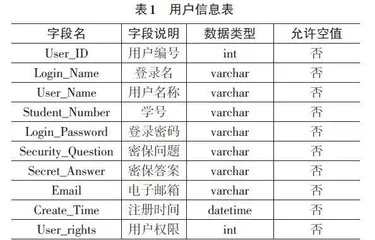
本文系统在具体设计时,主要使用了Oracle MySQL数据库。该数据库具有运行速度快、体积小、免费等优点,通过与SSH空间充分结合,可以有效开发中小型系统的数据库。此外,MySQL数据库功能稳定、强大,完全满足用户个性化使用需求。在本文系统中,MySQL数据库主要用于统一存储和管理用户信息、管理员信息,方便相关人员通过系统数据库进行数据的增加、删除、修改和查询[3]。在实际存储过程中,系统业务文件主要使用Hadoop集群。本文创建了用户信息表和管理员信息表,表1和表2展示了其属性信息。用户信息表包括用户编号、登录名、用户名称、学号、登录密码、密保问题、密保答案、注册时间等属性;管理员信息表包括管理员编号、登录名、管理员名称、登录密码等属性。
3 系统功能实现
3.1 系统功能列表
为了充分发挥和利用Hadoop分布式架构和云存储等技术的优势,确保云存储系统的稳定性和实用性,技术人员应严格按照图2所示的系统功能模块设计示意图完成用户管理模块、目录管理模块和文件管理模块的设计。在实际设计中,选择使用Eclipse作为开发工具,以Java为主要开发语言。在整个Web展示中,主要采用了JSP技术、Spring技术和Hibernate技术这三种技术。具体而言,用户管理模块应用JSP技术,目录管理模块应用Spring技术,文件管理模块应用Hibernate技术。
3.2 用户注册模块
在用户注册与登录模块的具体设计中,需要严格按照注册相关的标准和要求,有效地注册用户信息,并调用MySQL数据库的Create()方法来创建用户信息表。在用户进行登录和注销操作时,需要借助系统数据库来验证用户名和密码的有效性[4]。通过文件上传模块,用户成功登录系统并进入文件上传界面后,点击“上传”按钮,可以实现批量上传多个文件或快速上传单个文件。通过文件下载模块,用户登录系统并进入文件下载界面后,可以自行下载感兴趣的文件。这些文件一方面可以来自用户之前上传的文件,另一方面可以来自其他用户分享的文件。通过文件搜索模块,用户登录系统并进入文件搜索界面后,可以使用关键字匹配的方式对所需文件进行精确搜索。其他操作模块主要包括文件删除、文件重命名、目录新增和目录删除等操作。其中,文件删除操作主要调用File_delete()方法,文件重命名操作主要调用File_rename()方法,目录新增主要调用List_create()方法,目录删除主要调用List_delete()方法[5]。
3.3 文件上传模块
文件上传模块主要是将用户从本地系统上传的文件存储到Hadoop集群中。在用户与Hadoop集群进行交互时,需要通过文件系统类进行设计和实现。首先,调用create()方法完成所需文件的上传。由于本文系统支持用户批量上传文件,因此,在实现文件上传模块时,开发人员使用了Jquery的Uploadify上传插件,该插件可以将文件的当前上传进度展示给用户。在文件上传过程中,分布式文件系统采用流式上传的方式,将文件从Web前端上传到Web服务器,再由Web服务器将文件上传到Hadoop集群中。为了避免服务器性能限制导致系统响应时间延长,本文在设计文件上传模块时为每个用户设置并分配了单个线程。然后,按照一定的上传顺序批量上传多个文件,以确保在某一用户同时上传多个文件时,其他用户可以正常查找和获取感兴趣的文件。此外,在上传文件时还需要分析和判断文件的大小。当所上传的文件大小低于5MB时,需要将多个小文件合并为一个大文件,然后将其上传到Hadoop集群中[6]。
3.4 文件下载模块
在进行文件下载操作时,用户需要向Web服务器发送文件下载请求指令。此时,Web服务器会结合用户请求指令并检测系统的缓存情况,判断系统是否存在需要请求的文件。如果存在,系统会自动向用户返回相应的文件数据;如果不存在,Web服务器会借助分布式文件系统,发送用户的下载请求。在分布式文件系统中,各个客户端之间的连接关系是公开透明的,Web服务器不需要了解内部原理的实现,只须调用文件系统类的方法即可完成对文件的操作。通过使用FileSystem接口内部的Open方法,获取所需文件的输入流,然后调用Read方法,将读取的文件数据流直接传输给指定用户,实现文件的下载目的。
3.5 文件浏览模块
文件浏览模块是本文系统的重要组成部分,主要用于获取和显示当前登录用户所对应目录中的文件列表。在设计该模块时,会调用getFileStatus()方法来获取所需目录对象,并调用ListStatus()方法将文件状态数组直接返回到前端页面。前端页面会将相应的文件列表信息展示给用户,方便用户全面了解和掌握文件状态的详细信息。这为后期实时共享和最大化利用文件状态信息打下了坚实的基础。
3.6 其他操作
在设计和开发其他操作模块时,首先需要调用分布式文件系统的开发人员对本文系统的其他操作模块进行相应的设计和实现。这些操作模块包括文件删除、文件重命名和文件新建等功能。通过调用文件系统类中的Delete()方法、Rename()方法和Create()方法,可以实现文件的删除、重命名和新建,并为用户提供这些其他操作功能。然而,在设计文件删除、文件重命名和文件新建等其他操作模块时,如果文件名或存储位置发生改变,就需要及时更新当前用户目录下所对应的信息,以确保系统的准确性和一致性。
4 结束语
综上所述,本文应用基于Hadoop分布式架构设计的云存储系统具有强大的文件上传、文件下载和文件浏览功能。该系统不仅能够提高小文件的存取质量和效率,还能将名称节点内存开销量降至最低。此外,本文系统采用B/S访问模式,并使用图形界面将相关操作直观地展示给用户,以满足用户多样化的使用需求。尽管本文系统取得了一定的设计成果,但仍存在一些需要优化和完善的方面:名称节点内存消耗仍然是Hadoop面临的最大挑战,需要通过分布式存储文件元数据、拓展Hadoop集群的存储容量来进一步提高文件的执行速度,从而提升用户的使用体验。
参考文献:
[1] 谢帆,彭玉涛.基于Hadoop分布式架构的云存储系统、文件存储实现研究[J].电脑与电信,2022(10):102-105.
[2] 刘姝.基于 Hadoop 的云存储系统的设计与研究[J].郑州轻工业学院学报(自然科学版),2014,29(5):60-63.
[3] 郑海清.基于MongoDB的数据密集型云存储系统设计[J].电子设计工程,2021,29(1):106-109,114.
[4] 孙惠芬.基于云计算的海量大数据存储系统设计和实现[J].信息与电脑,2022(23):147-149.
[5] 张晓阳,许佳豪,胡燏翀.云存储系统中的预测式局部修复码[J].计算机研究与发展,2019,56(9):1988-2000.
[6] 徐翔,张光亚.基于Hadoop的云盘存储系统设计与实现[J].电脑知识与技术,2023,19(3):78-81.
【通联编辑:张薇】