基于YOLOv10s的车辆与行人检测方法
作者: 申静 曾晴 高雅楠 邓楠昆
摘要:针对城市交通场景日益复杂以及自动驾驶中行人与车辆实时检测精度亟须提高的问题,本文提出了一种基于 YOLOv10s 的车辆与行人检测方法。首先,对自动驾驶常用的 KITTI 数据集进行数据分类和格式转换的预处理;然后,将数据集按照 8:1:1 的比例随机划分为训练集、验证集和测试集;最后,采用 YOLOv10s 模型进行训练、验证和测试。实验结果表明,YOLOv10s 在 KITTI 数据集上的平均精度均值为 92.7%,其中 Car 类、Cyclist 类和 Pedestrian 类的 mAP 值分别为 98.4%、92.3% 和 87.4%,检测效果较为优秀。
关键词:城市交通;自动驾驶;行人车辆检测;KITTI 数据集;YOLOv10s
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2024)24-0025-03
开放科学(资源服务)标识码(OSID)
0 引言
计算机视觉被称为计算机的眼睛,为智能交通、自动驾驶等任务的实现提供了技术支持[1]。在自动驾驶中,目标检测是最基本的任务,是后续目标识别、目标跟踪等任务的基础。自动驾驶中的目标检测包括对车辆、行人、建筑物等物体的实时检测,其中最重要的是对行驶道路上的车辆和行人的检测。有效的车辆和行人检测方法有助于自动驾驶车辆及时避开障碍物、及时调整路线规划,对自动驾驶的研究和应用具有重要意义。
近年来,许多学者在车辆和行人检测算法方面进行了大量研究,推出了许多优秀的检测方法。其中,YOLO系列因其在性能与效率之间的出色平衡而受到越来越多的欢迎,成为诸多检测方法中热点研究方向之一[2]。随着 YOLO 系列算法的不断更新,研究者们也提出了许多基于 YOLO 系列的改进算法,这些改进主要集中在非极大值抑制(NMS)、网络结构等方面。例如,王启明等[3]通过改进 K-means 聚类算法生成先验框并使用软非极大值抑制(Soft-NMS)来优化对重叠目标的检测;梁策等[4]通过优化非极大值抑制算法,增加更多的特征层与残差单元,提升对小目标及多尺度目标的识别能力;龚凯等[5]采用轻量化网络 Mobilenetv2 替代 YOLOv4 中原有的主干网络,以获取有效特征层,并降低原有网络的运算量和参数量;郭志坚等[6]通过加入 CA 注意力机制模块和设计 CSP2-DBL 模块改进 YOLOv4 算法,提高网络计算速度;秦忆南等[7]通过卷积模块的替换,将 Neck 网络变为 Slim-Neck 网络,提升算法的平均精度和计算速度。郝博等[8]通过融合 Swin Transform 模块和 C3 模块优化 YOLOv7 模型,提高对小目标的检测精度;邓天民等[9]通过融合内容感知重组特征和自适应权重改进 YOLOv5 模型,提高算法检测精度。虽然以上算法在一定程度上提高了车辆和行人的检测精度,但我国交通环境日益复杂,自动驾驶下的车辆和行人实时检测仍需进一步提高。
1 数据预处理
1.1选择数据集
本文选择的数据集为KITTI 数据集。KITTI 数据集由德国卡尔斯鲁厄理工学院和丰田美国技术研究院共同收集和建立,拍摄于德国卡尔斯鲁厄及其周围,涵盖市区、乡村和高速公路等场景,是目前国际上用于自动驾驶场景中的计算机视觉算法评测最常用的数据集之一。
1.2数据分类
本文将 KITTI 数据集的数据分为三类,分别为机动车(Car)、非机动车(Cyclist)和行人(Pedestrian)。在分类中,笔者将 KITTI 数据集中的汽车(Car)、面包车(Van)、卡车(Truck)、有轨电车(Tram)合并为机动车(Car)类;将行人(Pedestrian)和坐着的行人(Person_sitting)合并为行人(Pedestrian)类;非机动车(Cyclist)类保持不变;而杂项(Misc)则被删除。
1.3格式转换
在 KITTI 数据集的训练数据中,每张图像都有对应的标签文件。原始标签文件中的每一行表示一个物体的标注信息,信息包括类别、观测角度、2D 边界框等数据。YOLO 模型的训练和测试常用的标签格式是 TXT 格式,其标注信息包含了类别和物体边界框的中心点坐标以及归一化后的宽度和高度。因此,本文需要将 KITTI 数据集的原始标签转换为 YOLO 模型常用的 TXT 格式标签。具体转换步骤如下:
1)获取每个原始标签文档对应图像的宽[W]和高[H]。
2)获取每个物体在原始标签文档中的2D边界值,包括左上角点坐标[x1,y1]和右下角坐标[(x2,y2)]。
3)根据公式(1)至公式(4),计算出边界框的中心点坐标[(x,y)]以及宽度[w]和高度[h],并将这些信息归一化。
[x=x1+x22] (1)
[y=y1+y22] (2)
[w=x2-x1] (3)
[h=y2-y1] (4)
4)根据公式(5)至(8)进行归一化处理,得到归一化后的中心点坐标[(x,y)]以及边界框的宽度[w]和高度[h]。
[x=xW] (5)
[y=yH] (6)
[w=wW] (7)
[h=hH] (8)
经过数据预处理,本文将 KITTI 数据集的原始标签转换为 YOLO 模型常用的 TXT 格式标签。然后,将预处理后的数据集按照 8:1:1 的比例随机划分为训练集、验证集和测试集。
2 YOLOv10 算法
YOLOv10 算法是 YOLO 系列的最新一代算法,旨在解决以往版本在目标检测中的后处理和模型架构方面的不足。通过消除非极大值抑制(NMS)处理和优化模型设计,YOLOv10 提升了检测性能和效率[10]。
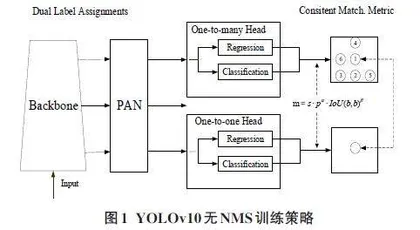
2.1 无 NMS 训练
YOLOv10 算法采用了双标签分配策略。在一对多标签分配策略的基础上,引入了一对一标签分配策略。这使得模型不仅能够提供丰富的监督信号,还能避免在推理过程中使用 NMS,从而提高模型的推理速度和效率。此外,YOLOv10 还采用一致性匹配公式,确保一对一标签分配策略能够提供更高质量的样本,进而提升整体性能,如图 1 所示。
2.2 优化模型设计
YOLOv10 模型在设计上进行了优化,包括使用轻量化分类头、空间与通道解耦的下采样方式,以及引入 CIB(Compact Inverted Block)模块,旨在减少计算成本并提高效率。此外,通过采用大核卷积和部分自注意力(PSA,Partial Self-attention)机制,模型在保持低计算成本的同时,提高了检测精度,如图 2 所示。
YOLOv10 系列包含5个模型,从小到大分别是 YOLOv10n、YOLOv10s、YOLOv10m、YOLOv10l 和 YOLOv10x。YOLOv10n 是最小但速度最快的模型,而 YOLOv10x 则是最精准但速度相对较慢的模型。用户可以根据具体的检测场景需求选择合适的模型。考虑到本文中检测目标大多为小目标,且对检测实时性要求较高,因此选择 YOLOv10s 模型作为车辆与行人检测的模型。
3 基于 YOLOv10s 的车辆与行人检测方法
本文提出的基于 YOLOv10s 的车辆与行人检测方法如图 3 所示。
1)选择数据集。本文选择的数据集是 KITTI 数据集。
2)数据预处理。
数据预处理包括数据分类和格式转换。将 KITTI 数据集的数据分为3类,分别是机动车(Car)、非机动车(Cyclist)和行人(Pedestrian),并将原始标签转换为 YOLO 模型常用的 TXT 格式标签。最后,将数据集按照 8:1:1 的比例随机划分为训练集、验证集和测试集。
3)训练模型。将预处理后的训练集输入 YOLOv10s 模型进行训练,从而得到训练后的车辆与行人检测模型。
4)验证模型。将预处理后的验证集输入训练好的车辆与行人检测模型进行验证,以获得验证后的模型。
5)测试模型。将预处理后的测试集输入经过验证的车辆与行人检测模型中进行测试,以获得检测结果。
3 实验与结果分析
3.1 实验平台
为验证本文方法的有效性,搭建了相关实验平台。操作系统为 Windows 10 专业版,集成开发环境为 PyCharm 社区版 2023.3.2,编程语言为 Python 3.6,深度学习框架为 PyTorch 1.8.0,CPU 为 12th Gen Intel(R) Core(TM) i5-12400F 2.50GHz,GPU 为 NVIDIA GeForce RTX 3060 Ti。
3.2 实验评价指标
本实验采用精确率(Precision)、召回率(Recall)和平均精度均值(mean Average Precision)三种指标来衡量 YOLOv10s 模型对车辆与行人的检测效果。其计算公式如下(9)、(10)、(11)、(12)所示。
[P=TPTP+FP×100%] (9)