注意力机制在YOLOv5瓶颈层的改进与研究刘炫东
作者: 罗立宏
关键词:YOLOv5;小目标;协同注意力机制改;瓶颈层;深度可分离卷积
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2024)28-0001-07
0引言
目标检测一直是计算机视觉中的重要研究方向,被广泛应用于医学、交通、工业、农业、军事、航天航空等众多领域。随着大数据时代的到来和GPU性能的提高,深度学习在计算机视觉各领域,尤其是目标检测任务中,得到了广泛应用。自2014年起,基于深度学习的目标检测算法不断涌现。二阶段网络如RCNN、Fast RCNN[1]、Mask RCNN[2]等,虽然检测的准确性较高,但实时性不强,不适用于如公路车辆检测、行人口罩佩戴情况检测等高实时性要求的场景。为克服这一缺点,YOLO[3]于2016年问世。作为单阶段目标检测网络,YOLO具备极高的实时性,同时保持了与二阶段网络相近的准确性。此后,更轻、更快的单阶段目标检测网络逐步进入学者们的视野,开启了单阶段目标检测网络的新纪元,如不基于框的单阶段目标检测FCOS[4]、CenterNet[5]以及基于框的单阶段目标检测SSD[6]等也接连问世。
2020年,YOLOv5以其最高140FPS的检测速度和小体积的优势,在各大目标检测领域取得了良好的效果。后续研究为提升其性能进行了多种尝试,如将可变卷积[7]应用于主干特征提取以获取更多关键特征,然而这可能因学习多余的位移而降低网络的实时性;还有将Backbone转变成VGG[8]、Resnet[9]等网络进行特征提取,但训练和预测的代价过高,难以满足工业和交通领域的实时性要求。引入MobileNet[10]、Shuf⁃fleNet[11]作为Backbone,虽然提升了训练和检测速度,但精确度也有所降低。
为了兼顾实时性和精度,人们引入SE(Squeezeand-Excitation)[12]、TA(Triplet Attention)[13]、CBAM(Con⁃volutional Block Attention Module)[14]、CA(Coordinate At⁃tention)[15]等注意力机制,通过增加计算量来换取更高的准确性,且增加的计算量对实时性的影响微乎其微。文献[16-18]在各自领域引入上述模块进行了研究,均取得了不错的效果。然而,改进后的模型未在如COCO、PASCAL VOC等一般数据集上进行性能验证。同时,人们还发现YOLOv5s在目标边界框判定上不够精准;使用YOLOv5m、YOLOv5L因模型过大受到硬件限制,无法满足更高实时性要求的场合。
因此,本研究提出了一个基于YOLOv5的算法改进,将协同注意力机制改(Coordinate Attention New) 引入瓶颈层以提高特征提取能力,并使用深度可分离卷积来降低网络的复杂程度。改进后的算法能够在一般数据集上实现精度与速度之间更好的平衡。
1 YOLOv5概述
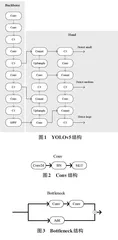
YOLOv5网络整体结构如图1所示。
YOLO算法基于将一张图像划分为若干网格来寻找目标质心,从而使用边界框识别目标类别。该算法演变到了YOLOv5阶段,按照模型大小可分为s、m、l、x,这些模型在架构上相同,仅在网络的深度和宽度上有所不同。整个算法由输入、Backbone和Head三个部分组成。输入部分使用Mosaic技术、图像剪切拼接等技术对输入图像进行预处理;Backbone部分则采用卷积、CSP改进和SPPF来进行特征提取;Head部分使用FPN+PAN的特征金字塔结构,实现了在不同尺度特征图上的目标检测。最终,通过计算中心坐标损失、宽高坐标损失、置信度损失和分类损失,并通过非极大值抑制(NMS) 减少冗余的边界框,以提高检测准确性。
Conv是主干部分的卷积复合模块,由卷积层、批标准化和激活层组成,具体结构见图2。
如图3所示,Bottleneck是一种类似于残差网络的模块结构。该结构通过两个卷积(Conv) 模块先减少再扩增通道数,以提取更显著的特征信息,并使用加法(Add) 操作来控制是否进行残差连接。
CSP[19]的改进在网络架构中被命名为C3,该架构由瓶颈层和多个Conv模块组成,与之前的YOLOv5的BottleneckCSP相比,减少了一个Conv模块,如图4所示。这种改进能够在不降低检测精度的情况下减少参数数量,从而提高运行速度。
SPPF是SPP(Spatial Pyramid Pooling) [20]的改进版,其结构从并联的三个最大池化转换为串联的三个最大池化。最终,将这三个最大池化的结果与原始权重进行拼接。这种转变在不显著损失精度的情况下,大幅提升了推理速度。具体结构如图5所示。
2 改进
2.1 协同注意力机制(CAN)
YOLOv5网络能够通过卷积获取图像的局部特征,但在捕获图像特征的过程中,卷积会逐渐损失图像的位置信息,从而导致目标边界框回归精度降低。CA机制通过将位置信息嵌入信道中,使网络能够在不显著缺失位置信息的前提下进行特征提取,同时避免产生显著的计算开销。
然而,CA机制仅考虑了空间因素,而忽略了通道在特征提取过程中的影响。在YOLOv5的训练过程中,随着卷积核数量的增加,通道的数量也随之增加,需要通过评估来确定哪些通道包含关键信息。因此,本研究基于CA机制提出了一个新的模块CAN。
CAN借鉴了SE机制,对特征图的每个通道的重要性进行评估,从而获取关于特征图通道的权重因子。如果通道上包含的关键信息越多,则其权重数值越高。CAN结构如图6所示。
3 改进的网络总体结构
图 9 为 CAN-YOLOv5 的整体网络结构。该网络基于 YOLOv5,使用 CAN 模块提高了网络的特征提取能力和检测精度,并引入分组卷积以降低网络的复杂度。其中,星号 (*) 表示在 C3CAN 的 BottleneckCAN 中使用了深度可分离卷积。
4 实验与结果分析
4.1 实验环境与参数设置
具体实验环境如表1所示。
所有 YOLO 模型初始学习率为 0.01,动量参数为0.937,最终学习率为 0.1,批量大小 (BatchSize)为 32,衰减参数γ 为32。使用官方的预训练模型YOLOv5s.pt,并采用 epoch 为 3、动量参数为 0.8的 warm-up 方法预热学习率。在 warm-up 阶段,采用一维线性插值更新学习率。预热结束后,使用随机梯度下降法更新学习率。测试和验证的置信度阈值设置为0.001,IOU阈值设置为0.6。其余超参数均与官方给出的超参数文档保持一致。
4.2 数据集与预处理
本研究采用 COCO 和 PASCAL VOC 数据集进行实验。COCO2017 数据集共有 80 个类别,训练集使用 COCO2017 中的 train 部分进行训练,共 118 287 张图像;验证集使用 COCO2017 的 val 部分进行验证,共 5 000 张图像;测试集使用 test 部分进行测试,共4 070 张图像,并将测试结果上传到官方平台进行评估。PASCAL VOC 数据集共有 20 个类别,训练集使用 train+val 2007 和 2012 进行训练,使用 test 2007 进行测试。
对于 640×640 的图像,使用 k 均值聚类算法对目标框进行聚类,在 VOC 数据集中获得 99.8% 的最大可能召回率(BPR) ,在 COCO 数据集上获得 99.5% 的BPR。相应的三种尺寸的锚框,最终锚框尺寸如表 2 所示。
在数据集图像上,使用了随机裁剪、变换、翻转、缩放以及调整亮度、曝光、色调、饱和度的方法进行数据增强。此外,还使用了 Mosaic 数据增强。Mosaic 数据增强首先生成一张空白画板,随机选择一个位置作为目标中心,通过裁剪、缩放、翻转等操作,使多张图像围绕该中心进行拼接,生成一个新的图像。这种方法有利于网络在较短时间内学习多张图像的特征,同时能够有效防止过拟合,增强鲁棒性。Mosaic 数据增强的效果如图10所示。
5 结束语
为了有效解决目标边界回归精度不高以及误检率较高的问题,并提高小目标检测能力,本研究对 YO⁃LOv5 模型进行了改进。通过采用 CAN 模块,提升了网络对目标边界框回归的精度,从而降低了误检率。为减少引入 CAN 模块后增加的模型复杂度,采用了深度可分离卷积以减少参数量和计算量,提高了实时性。与 YOLOv5s 相比,CAN-YOLOv5 在 VOC 数据集上的[email protected] 和 [email protected]: 0.95 分别提升了 5.0% 和8.5%;在 COCO 测试集上的 AP、AP50、AP75、APS、APM 和APL 分别提高了 1.2%、1.2%、1.9%、2.5%、1.8% 和2.9%。参数量和计算量分别降低了 12.5% 和 18%,进一步降低了模型的复杂度,能够更好地适用于移动应用和其他实时性要求较高的应用。未来的研究将尝试将 CAN 模块应用于其他特征提取网络。