基于PyQt的多表情智能语音聊天机器人系统
作者: 张嗣凰 周伊佳
关键词: PyQt信号与槽; 智能语音调节; 人机互动; 多表情切换; 情绪识别
中图分类号:TP3 文献标识码:A
文章编号:1009-3044(2024)28-0118-03
0 引言
聊天机器人,是一种基于AI的应用程序软件,其核心功能在于利用自然语言[1]实现人与人之间交流的某种形式的仿真。通常情况下,这个系统的运行环境是在某种专门的软件平台上,而且主要是在各种移动设备上,比如电脑、智能手机等。
ELIZA[2](伊莉莎)是最早的聊天机器人,由JosephWeizenbaum于1966年研发完成,它在模拟对话过程中采用模式匹配和替换方法。这款机器的最初设计目标是为了能够帮助心理咨询师解决患者精神问题。1988 年,尤内克斯顾问(UNIX Consultant) [3]聊天机器人系统问世,开发者为加州大学伯克利分校(UC Berkeley) 的Robert Wilensky等人。在设计过程中基本延续了伊莉莎的设计思路和技术原理,主要作用是根据不同用户对UNIX系统的熟悉程度、应用场景、学习需求进行建模实验,帮助用户更好地进行系统的学习。
自1990年起,在美国科学家Hugh G.Loebenr设立的勒布纳人工智能奖项激励下,聊天机器人智能化进程全面提速,其中最具代表性的聊天机器人系统主要有:爱丽丝(ALICE) 、YAP[4]系统(主要用途为查询英国电话黄页)、CSIEC[5]系统(主要用途为针对外语学习者,搜索学习伙伴)、Sofia[6]系统(主要应用于哈佛大学勒布纳奖学数学教学)等。但是聊天机器人系统目前存在一种难以解决的问题,即在与人类进行交流时并不能像人类本身一样实时表现出相对应的表情。
基于以上问题,本文提出了一个基于PyQt的多表情智能语音聊天机器人系统,本系统不仅可以与用户对话交流,还可根据用户语音中的情绪实时地切换表情,提升聊天机器人的情感表达效果。
1 智能语音调节装置
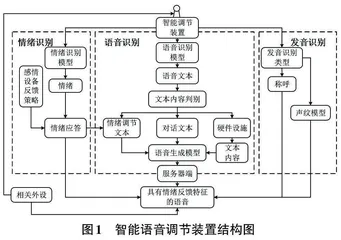
所提出的智能调节装置主要有以下几个模块:唤醒模块、情绪识别模型、情绪对话策略和语音生成模块。其结构如图1所示。
唤醒模块的设计主要目的是对语音调节装置进行唤醒,唤醒方式主要有两种:语音唤醒和距离唤醒。语音生成模块的主要作用是根据前序任务完成后生成的对应模型,在网络状态下生成系统设定的声音特征及相应的情感文字语音,并通过生动的方式播放。
深度学习算法是当前人工智能领域中最受欢迎的情绪识别模型,能够实时识别用户语音中的各种情绪,例如快乐、悲伤、愤怒或平静等。
在对情绪进行识别之前,必须针对语音信号中包含的情感特征进行识别与确定。关于该识别方式,本课题从频谱关联、韵律特征、声学质量特征、融合特征以及深度学习条件下的语音特征等方面进行情感分析。目前,我们已经对声学特征与情感之间的相互关系进行了初步研究,如表1所示。
经过前面的研究,选取有效的特征作为识别模型的输入,使用卷积神经网络的模型应用于频谱图或音频特征(例如Mel频率倒谱系数(MFCC) [7]和低级描述符(LLD) [8]) ,对源自原始音频信号的信息进行训练。与此同时,使用低级描述符(LLD) 和深度神经网络提取与不同角色相对应的语音特征。虽然低级描述符(LLD) 和高级统计功能(HSF) 只能获取语音特征的局部信息,而非全局信息,且随着特征抽取维数的增加,深度神经网络的复杂性也随之增加,难以进一步提升识别精度。在此基础上,本课题提出在原始语音输入中加入全局信号,在一定程度上限制人工合成的特征维数,并获取完整的语音信息。
基于上述研究,本课题提出利用人工合成的 HSF 与 CRNN [9-10]的联合表达,侧重研究特定部位和整体部位的表达,以精准判断语音情绪的强弱。该方法的具体操作方式如下:首先为了使不同类型特征能够投影到相同的特征空间,因此添加隐藏层;其次,对初始确定的特征维度进行降低维度的处理。
网络结构包含以下两项内容:第一项是卷积式特征提取器,该采集器的输入层为一张频谱图,其中纵坐标表示频率,横坐标表示时间,中心坐标表示语音数据量。在此基础上,本课题提出了一种基于颜色的三维坐标系数值表示方法,并利用颜色有效地表征。在处理预切分的语音时,可通过该方法取得任一段的卷积神经网络学习特征[11]。第二项为BMLSTM,在此基础上,每个时间步都与原声音的某一部分相对应,既避免了对音频的剪切,也避免了对语音的填充,又能在一定程度上保持长时依存关系。在计算过程中,将最大池化层、平均池化层和最小池化层进行运算,实现池化矢量的集成化。
2 PyQt 的信号与槽机制
正文内容在PyQt 中,每一个QObject 对象以及PyQt中每个继承了QWidget的控件(这些都是QObject的子对象)均支持信号与槽机制。当信号发射时,连接的槽函数将会自动执行。在PyQt中,信号与槽通过object.signal.connect()方法进行连接。
其中,信号和槽是其中最主要的接口,主要应用于多个对象的互相通信。在Qt的各种特性中起着核心作用,取代了原本复杂混乱的函数指针,使得通信程序的编写过程得以简化。信号和槽包含在所有从QObject或其子类(如QWidget) 派生的类中。当这些对象的状态由于各种因素而发生变化时,该对象会立即发射与之对应的信号,结构如图2所示。
槽的主要作用是接收信号,但通常它们是对象的成员函数。一个槽无法判断是否存在其他信号与其进行连接。同时,在这一过程中,对象也不需要了解底层的通信机制。单个槽可以与多个信号建立连接,同样,单个信号也可以与多个槽建立联系。即使两个信号之间建立了相关连接,这种操作也是可以实现的。在这种情况下,无论第一个信号何时发射,系统都会立即响应,并发射第二个信号。
本文将通过智能语音调节装置在线识别出的用户语音中表达的开心、悲伤、愤怒或平静等情绪作为信号(每种情绪对应一个信号),传递给相应的槽函数(需要提前准备展示机器人表情图片的函数,每种情绪准备一个槽函数,利用PyQt GUI界面[12]) ,通过将一个信号与一个槽连接,实现表情的切换。
3 服务器端
由于该部分涉及的工作冗余性较强,因此解析规则显得尤为重要。在有效获取语音数据后,可以将用户的语音上传至相应的服务器,并使用对应的、带有明显特征的标签,来有效提取其中所包含的数据内容。同时,针对不同的语音和文档,设计便于区分且具有相关性的文档名称解析规则,即为每个文档提供多种正则表达式模板。在确定标签中所包含的数据范围后,对其进行分块,分析其中的目标信息。针对已分析的数据,采用统一格式:id_情感_性别_年龄_ 姓名等。
最后,将已解析出的数据有序存储在HDFS中,并根据分析结果自动完成指定的备份次数。
在本文中,将数据备份为三份,以方便未来的数据存储和数据查询工作。图3为服务器端存储数据的基本流程。
4 结论实验及相关结果
正文描述了通过语音唤醒多表情智能语音聊天机器人的过程。唤醒前,机器人的初始表情如图4所示;唤醒后,机器人的表情如图5所示。
当多表情聊天机器人识别说话者语音时,机器人的表情如图6所示。
在与用户对话时,多表情聊天机器人的表情会根据用户的语音情绪而实时切换。例如:
1) 当聊天语句带有开心的情绪时,机器人的表情如图7所示。
2) 当聊天语句带有生气的情绪时,机器人的表情如图8所示。
3) 当聊天语句带有害羞的情绪时,机器人的表情如图9所示。
4) 当聊天语句带有无聊的情绪时,机器人的表情如图10所示。
5) 当聊天语句带有无奈的情绪时,机器人的表情如图11所示。
6) 当聊天语句带有悲伤的情绪时,机器人的表情如图12所示。
5 结论
本系统利用语音调节装置识别用户的实时语音与情绪,将用户实时的语音转换为文字,通过相关搜索生成语音与用户的交流;同时,将识别出的情绪作为信号,结合PyQt的信号与槽机制进行实时的表情切换。多次实验表明,利用PyQt的信号与槽机制传递智能语音调节设备识别出的情绪信号连接到相应的槽函数中,可以实现多表情的切换,使聊天机器人的情感表达更加贴近实际,提升了用户体验。