天文数据处理流水线可视化建模的研究与实现
作者: 唐家宁 吴开超 张晓丽
关键词:流水线建模;数据处理自动化;快速射电暴;gRPC;布局管理
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2023)03-0060-06
1 引言
天文学是一门以观测为基础的学科,从观测数据中搜寻信号总结规律,因而对数据运算处理都有很大需求。天文数据处理的流程复杂,传统上多依赖人工,处理效率较低。当前观测数据规模快速增长,现有处理方式难以满足PB级天文数据的快速处理要求。500米口径球面射电望远镜FAST(Five-hundredmeterAperture Spherical radio Telescope) 是我国于2016年建成的世界上单口径最大、灵敏度最高的射电望远镜[1],每年观测产生的数据量达15PB。快速射电暴(Fast Radio Bursts,FRB) [2]是FAST的主要科学目标之一,也是当前射电天文领域的热点研究方向,FRB搜索计算处理的算力需求大、流程复杂、人工依赖性较强,需提升计算处理效率,以加快科研成果的产出。
为解决以FRB搜索为代表的天文数据处理中存在的问题与挑战,在对其处理过程复杂、冗长、数据算法独立性较高等特点深入分析的基础上,设计了流水线(Pipeline) 模型,将整个数据处理过程分为若干步骤,每一个步骤都设计为独立的数据处理模块,整个模型采用流水线工作模式[3]将所有处理模块以有向无环图(DAG,Directed Acyclic Graph) 串联起来,通过设计流水线处理引擎,来驱动对流水线DAG模型的自动化处理。
基于此构建天文数据处理自动化流水线平台。流水线平台主要包括流水线处理引擎和支持与科学家交互的流水线建模工具软件。本文主要研究天文数据处理中的流水线建模技术以及建模中的可视化交互及可视化呈现。基于平台分布式架构,通过对接流水线处理引擎,实现流水线模型自动化执行,进而减少人工操作。
2 可视化建模相关研究工作
可视化建模中涉及模型自身与模型可视化表达,基于经典的MVC模型开展相关研究是其中重要的研究内容;流水线建模应用涉及大量数据交互,gRPC(Google Remote Procedure Call) 支持高效的数据序列化,是当前最重要的分布式对象协议之一,可为分布式的流水线建模应用提供底层支撑;模型图中的部件自动布局管理也是模型可视化的重要研究内容。
2.1 MVC模型
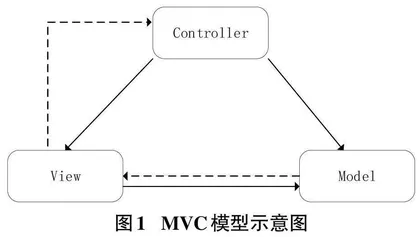
MVC 设计模式由Trygve Reenskaug于1970年代在Xerox Parc首次提出,其根本目的是构建人类用户理解的业务模型和计算机数字模型的桥梁[4]。1988年Krasner和Pope详细解释了smalltalk中的MVC模式,如果在构建应用程序时考虑模块化,尽可能将功能单元彼此隔离,使应用逻辑设计更易于理解和修改,而无须了解其他逻辑单元[5]。按MVC模式,可将用户应用程序分为三个部分:主应用域模型、模型数据展示和用户交互。MVC模型结构如图1所示。
1) 模型Model
模型负责管理与数据相关的所有任务:验证、会话状态和控制,引入模型管理可降低应用代码的复杂性。模型层负责应用程序的业务逻辑,通过封装访问数据(SQL/NoSQL/文件等)的方法,提供一个可重用的代码库[6]。
通常一个模型是用数据构建的头脑中的抽象,验证和认证,由定义感兴趣领域的代码组成,封装存储在数据库中的数据及其操作,并与不同数据源的交互,执行业务规则。通过有效设计使得模型在应用程序间变得高度可重用。
2) 视图View
视图负责图形界面管理。针对Web应用,所有表单、按钮、图形元素和应用程序内部的所有其他HTML元素,可用于生成RSS聚合器。通过将应用程序的设计与应用程序的逻辑分离,当设计师决定改变应用程序的界面时,可降低出错的风险[6]。
Web应用中视图层控制数据显示方式和用户交互模式,并提供收集用户数据的方法。视图通常不应包含属于应用逻辑的元素,以使其更容易供设计师使用。视图层通常利用模板技术来实现,模板中使用特殊的HTML基于相关内容来插入和生成注释,设计人员可看到渲染视图之前的整个标记,这使得模型处理对于前端开发人员透明。
3) 控制器Controller
控制器负责事件处理,事件则由用户交互或系统进程触发。控制器绑定所有应用逻辑,将View的显示与View的功能绑定。模型则负责检索数据并为视图建立执行路径。控制器还负责统一的错误处理。控制器接受用户交互请求后,访问模型的功能,与模型交互检索所需数据生成视图,并解释接收到的数据,准备相应的数据格式,以便在视图中显示。
2.2 gRPC通信
gRPC是一个高性能、通用的开源RPC框架,基于ProtoBuf(Protocol Buffers) 序列化协议开发,且支持众多开发语言。面向服务端和移动端,基于HTTP/2设计,具有诸如双向流、流控、头部压缩、单TCP连接上的多复用请求等特征[7]。
在gRPC 里客户端应用可以像调用本地对象一样,直接调用其他不同机器上的服务端应用的方法,能够更容易地创建分布式应用和服务,请求流程如图2所示。
1) 客户端(gRPC Stub) 调用M方法,发起RPC调用。
2) 对请求信息使用Protobuf 进行对象序列化压缩(IDL) 。
3) 服务端(gRPC Server) 接收到请求后,解码请求,进行业务逻辑处理并返回。
4) 对响应结果使用Protobuf进行对象序列化压缩(IDL) 。
5) 客户端接受到服务端响应,解码请求体。回调被调用的M方法,唤醒正在等待响应(阻塞)的客户端调用并返回响应结果。
对于技术选型,流水线平台基于gRPC进行前后端通信,有如下优势:
1) 性能好,传输效率高:流水线模型运行过程中数据层和视图层的数据规模都比较大,需要在前后端频繁通信,gRPC通过Protocol Buffers定义接口,基于ProtoBuf可将数据序列化为二进制格式,减少数据量,大幅度提升性能[8],且gRPC采用HTTP/2.0协议进行传输,可以减少TCP连接次数,更加节省网络带宽。总体上传输效率相较json数据流快6倍。
2) 简化编程,编码效率高:流水线平台客户端基于JavaScript实现,服务端基于Java实现,gRPC可以跨语言使用,支持多种语言,基于proto文件可生成客户端和服务端目标代码,通过前后端对象的序列化实现通信,序列化反序列化直接对应程序中的数据类,不需要解析后再进行映射,前端可直接调用后端接口方法,简化流水线建模工作平台工作流程,提高编码效率。
2.3 图表布局管理(Diagram Layout Management)
数据流建模中数据流模型以图表形式展示并与用户交互,基于布局管理算法实现图表的自动绘制,使得其具有良好可读性,并符合美学要求。自动布局算法接收指定图表元素之间连接关系的抽象图(DAG)作为输入,并根据美学产生相应的图表作为输出。基本策略是逐步构建布局,首先构建好拓扑结构,减少边之间的交叉;随后,图表的形状根据沿边缘出现的角度做调整;最后给图赋予维度,得到图的网格骨架[9]。
数据流模型通常都是手动生成的,或者使用图形编辑器生成;在这两种情况下,图表的布局都由设计者负责[10]。自动布局管理在以下方面对建模过程非常有用:降低制作和维护图表的成本;自动生成符合美学的图表,增加图解表示的表达能力;整合图表的构思和制作阶段;图文文档自动统一管理,增加用户和设计者之间的通信带宽。常见的自动布局管理如表1所示[11]。
3 流水线可视化建模的设计与实现
3.1 设计思路及方法
流水线平台主要包括流水线处理引擎和支持与科学家交互的流水线建模工具软件。本文聚焦于天文数据处理中的流水线建模技术以及建模中的可视化交互及可视化呈现。向上面向科学家用户的使用需求,研究数据处理全生命周期的建模管理,提供图形化管理界面,支持数据处理流水线的可视化交互及可视化呈现;向下对接流水线处理引擎,完成对流水线模型的驱动。驱动过程主要依靠后端调度算法,具体实现过程不是本文研究重点,不做具体介绍。流水线建模实现主要通过构建流水线建模工作台,完成Pipeline模型绘制,得到可视化模型数据结构,经过Pipeline 执行流程,赋予模型计算能力并且得到流水线处理引擎可工作的DAG模型数据结构。基于模型管理,完成流水线启动以及运行过程可视化展示,辅助用户分析。基于此,提出具体设计思路、实现方案及方法。
1) 基于DAG的流水线模型设计
流水线平台实现数据处理自动化的关键在于模型数据结构定义,需构建各计算任务间的依赖关系,完成流水线处理引擎数据驱动。天文数据处理流水线是由一系列串行的、数据驱动的处理模块组成的数据处理过程。流水线的数据流程中通常不存在分支或循环。第一个模块将原始数据作为输入,对其进行处理,并将其结果发送到第二个过程,依此类推,最终以最后一个模块产生的最终结果结束。软件平台层面上可理解为由相互连接的数据集和处理模块组成的有向无环图,因此流水线数据结构可基于DAG进行定义,以yml文件形式进行保存。模块封装和数据组织是流水线定义的重要环节,因此可定义两类节点,数据集节点和处理模块节点。DAG的起点和终点为数据集,数据集和处理模块交叉互联。数据集中应包含数据集名称节点实体路径等信息,处理模块应包含处理模块名称、输入输出数据集、下级处理节点、工作基础镜像等信息,yml文件具体定义形式如下所示:
2) 流水线建模工具的构建
流水线建模工具包括流水线建模工作台以及流水线相关管理界面,主要基于MVC模式实现模型构建与模型输出功能。Model模型层用于数据处理、逻辑处理,View视图层用于显示用户界面,Control控制层作用于模型和视图上,控制数据流向模型对象,并在数据变化时更新视图。
针对流水线可视化建模需求,视图层需要为用户提供一个通过简单拖拽节点组件来构建Pipeline模型的工作台,构建好的Pipeline模型可保存、可复现、可创建流水线实例,提供模型启动、模型执行过程、输出结果可视化的模型管理界面。Pipeline模型结构需与数据层相匹配,模型中包含的相关数据应有节点、连线、位置等信息,各节点默认配置项、配置参数选项等。基于此,将上述功能划分,应用于视图层设计,模块结构设计如图3所示。
①节点组件。
节点组件可理解为流水线建模过程中的模型算子根据Pipeline定义形式,定义两类节点组件:数据集节点和处理节点。
a) 数据集节点:此类节点为用户提供数据处理所需的数据,包括建模流程交互功能和实例创建后数据管理功能。建模流程交互功能允许用户拖拽至流水线建模工作台,作为算子使用;数据管理功能在模板实例创建后,可显示数据列表,支持数据详情查看等。
b) 处理节点:此类节点用于封装数据处理过程中的各类算法,实现对单位数据实体(单个实体、一组实体)的数据变换、数据过滤、数据传输等处理功能。该节点允许用户在建模流程交互功能中拖拽至流水线建模工作台,作为算子使用。允许用户在模板实例创建后查看处理过程任务列表,支持任务详情查看。
②流水线建模工作台
流水线建模工作台为用户提供Pipeline模型构建功能。选用HTML5交互性图形库中图表布局管理技术,支持用户在图形编辑界面进行编辑,支持用户拉取具备连接关系的数据自动生成拓扑图。用户可通过图形编辑界面构建流水线模型,也可通过导入具备一定连接关系的数据自动生成流水线模型,数据结构参考下文提到的可视化数据结构,自动布局无需节点位置关系。