基于机器学习的网上问政文本分类方法
作者: 於雯
摘要:随着信息技术的发展,政务服务的水平也得到了提升,各级政府部门都开通了网上问政服务,留下了大量的群众留言,只通过后台人工对留言进行分类,效率低下,费时费力。本文提出基于机器学习的方法,对网上问政的文本进行分类,利用自然语言处理的技术对文本进行合理的预处理操作,利用词向量工具Word2vec将文本表示成向量的形式,通过机器学习算法支持向量机(SVM)的方法进行文本分类。实验表明,在基于机器学习的文本分类中,经过预处理和词向量模型表示后的文本,使用SVM分类方法对网上问政文本进行所属机构类别取得了90%以上的准确率。
关键词:自然语言处理;机器学习;网上问政;文本分类;SVM
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2023)06-0022-03
开放科学(资源服务)标识码(OSID)
0引言
智慧政府的建设为群众提供了更多样的政务服务途径,开通网上问政方便群众可以通过互联网完成对相关问题和政策的咨询,不受时间地点限制,方便群众办事,拓宽了政府服务渠道。对于网上问政的问题和留言,需要根据问题的类型分类以便归口到对应的政府机构进行回复与处理,而有不少群众对于自己所需要咨询的问题并不能准确划分归口部门,导致问题不能及时得到有效处理[1]。通过自然语言处理对网上问政的留言文本进行分类可以更加高效地对留言进行分类,对群众关切的问题进行及时回应,提高政务服务的水平。
自然语言处理就是将人类语言转换成计算机可以理解和处理的语言,利用计算机技术实现更加智能的机器理解与后续处理。自然语言就是人类沟通交流所使用的语言,根据地域和种族的不同,不同国家和民族都会有自己的语言,主要有英语、汉语、俄语、法语等。不同的语言类型也有不同的语法结构,需要采用不同的处理才能达到理想的效果,针对中文的文本预处理,目前主要有中文分词、去除停用词、词性标注、向量表示等,根据不同的文本特征进行预处理可以大大提高文本处理的准确率。支持向量机模型在多个自然语言处理问题中都取得了较好的实验结果,本文利用SVM的算法对网上问政文本分类,采集网络上公开的、实际的网上问政文本,通过文本预处理对网络文本进行分词,去除停用词得到更加规整的文本形式,采用词向量模型Word2vec将文本转换成计算机更容易处理的向量形式,最后采用SVM分类方法对文本向量进行分类,并验证分类的准确率,同时还验证了采用不同的预处理操作,以及词向量模型对于分类准确率的影响。
1 文本采集与预处理
1.1数据采集与清洗
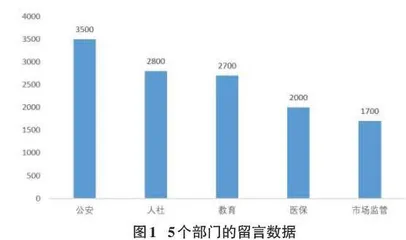
从某市政府网上问政平台公开的政务留言数据中,采集网上问政留言数据,并按群众留言数量排序得到问政数量最多的前五个政府机构,分别为:人社、医保、市场监管、公安、教育。由于采集到的网络文本存在着网络符号,重复文字,需要对采集后的原始网上留言数据进行清洗、规整、补录和统计。第一,针对采集到的留言数据进行清洗,删除针对研究没有意义的符号、重复和缺失留言数据;第二,对采集到的部分半格式化的信息进行格式化,如将包含中文的留言数据字段规整为整型字段。数据清洗流程为之后的数据分析和分类提供优质的基础数据。最终清洗后得到共计127000条留言数据,5个留言数量较高的机构数据数量如图1所示。
1.2 中文分词
中文句子的最小单位是字,而词才是具有语义的最小单位,并且具有非常丰富的语义及结构特征。在对文本进行文本分类,对文本语句进行按词的划分具有决定性作用,因此分词的准确性是保证分类结果准确的基础。相比英文每个单词都以空格结尾,对句子进行了天然的切分,所以中文文本不具有良好的切分标志,所以需要对句子按照词语进行切分,只有正确地按照词句进行切分才能对句子进行分析。对句子的正确切分就是自然语言处理领域的分词,准确的中文分词也是目前的研究难点。
目前针对中文的分词工具有很多种,国内比较常用的分词系统包括:jieba分词、中科院的 NLPIR中文分词系统,哈尔滨工业大学语言技术平台(LTP)分词系统等。jieba分词是一种常用的开源分词库。它提供了一种非常适合文本细分的分析模式-精确模式[2]。主要是因为它能够根据分割模型以最精确的方式分离句子。同时,jieba 还支持用户自定义的词库,可以有效地提高准确率。本文采用比较常用的jieba分词来进行分词处理。
1.3 去除停用词
停用词(Stop Words)是指在自然语言处理中可以过滤掉的一些没有实际意义的功能词,这些词在文本中出现的频率较高,但对文本表达没有实际意义,中文常用的停用词有代词“这”“那”,助词“的”“了”,介词“在”,语气助词“呢”“啊”等[3]。去除这些无实义的高频停用词可以降低特征向量的空间维度,提高分类的准确率,本文使用哈工大的停用词表来对文本中的停用词进行处理。
1.4 词向量表示
网上留言属于非结构化文本,不便于使用计算机处理和理解,需要将其按一定的规则把文本转换成数值模型的词向量,使计算机能理解并加以处理。这也是文本处理的一个重要问题,如果可以准确合理地将文本表示成数值类型,将会大大提高计算机的处理和分析难度。利用最简单的想法,对每个词语进行赋值,句子就是每个词语数值的集合,但是这些散乱的数值便不能有效地表示出语义信息,因此采用一种神经网络的语言模型,CBOW(Continuous Bag-of-Words)模型是一种经过改进的神经网络语言模型,主要通过映射层替代隐层,实现了输入层词向量的相加,从而降低了模型的计算量。CBOW模型是由预知的上下文来得出单词出现的概率。主要结构是由输入层、投影层和输出层三层结构组成,模型的学习目标是根据输入层输入的信息和输出层输出的条件概率最大化对数似然函数:
[L=w∈Cl))] (1)
其中,[W]是从语料库[C]输入的词语。 CBOW 模型的原理可以解释为,假设已知上下文,通过上下文来预测中间最可能出现的词。因此模型的输入是上下文词向量,经过投影层简单求和,再输入输出层,输出出现概率最大的词[W]。
本文将使用 Word2vec训练词向量,Word2vec词向量模型包含了 CBOW 模型,用高维向量表示词语,并把相近意思的词语放在相近的位置,并且使用实数向量(不局限于整数)只需要用大量的某种语言的语料,就可以用它来训练模型,获得词向量。在本文的实验中,对采用不同的预处理进行实验对比,验证预处理操作对文本分类结果的影响。
2 SVM 文本分类
支持向量机是一种监督学习算法,是一种广泛使用的机器学习方法,SVM算法具有泛化能力强,能够很好地处理高维数据,无局部极小值问题。SVM算法利用核函数将词向量映射到高维的空间中,使在低维空间中不可分的特征在高维空间中变得可分,从而完成分类的任务,利用 SVM 分类模型对词向量提供的数据特征进行文本分类,根据训练集数据将模型参数学习到最优,然后利用训练好的模型对测试集数据中文本类型作出预测,最后根据预测结果判断训练模型的好坏[4]。针对文本二分类任务,SVM模型分类的原理是将通过预处理阶段生成的文本词向量经过核函数的映射作用,分布到更高维度的空间中,然后将问题转化为在高维空间中的线性分类问题,找到可以分隔的最大区间超平面,并且两个最大的超平面中的每一个超平面在每一侧都有两个其他超平面。两个超平面彼此平行,并且最大化两个超平面的间距就是最优的分隔超平面。支持向量机模型如图 2所示。最大间隔超平面表示为:
[Wx+b=0] (1)
两个平行的超平面为:
[Wx+b=1] (2)
[Wx+b=-1] (3)
y表示数据的分类标签,-1表示属于机构1的数据,+1表示属于机构2的数据。令:
[f(x)=Wx+b] (4)
将两个相互平行的超平面上的点称为支持向量,满足:
[|Wx+b|=1] (5)
因此,从支持向量到最大间隔超平面的距离为:
[Wx+bW=1W] (6)
设间隔的大小为[M],那么:
[M=1W] (7)
最大化[M]等价于:
[max1W→minW2] (8)
因此,满足最大间隔超平面所需的条件是:
[minW2] (9)
满足于:
[yiWxi+b≥1;i=1,2,...,N] (10)
转化为拉格朗日优化问题,利用拉格朗日乘数法进行计算得到式(11):
[LW2,b,α=12W2-i=1NαiyiWTxi+b-1](11)
其中,[αi]是拉格朗日乘子。
SVM算法的特性对于二分类问题可以较好地处理,而对于多分类问题就要对SVM算法进行改进,目前针对多分类的问题,SVM算法的改进方法主要有两种,第一种是对每两个类别之间都构造一个SVM 二分类器,对每一个分类器判别出的所属类别计数,最终计数最大的那个类别就是该文本所属的类别;第二种是对于M个分类,对一个类别和剩余的M-1个类别之间构造一个二分类进行分类判别,如果不属于第一个类别,就继续在剩余的M-1个类别中继续构造分类器进行判别。由于第二种方法中M-1个类别的数据量会明显大于某个单一类别的数据量,造成数据失衡,导致一个样本可能属于多个类,因此本文中采用第一种方法构建多分类的SVM分类器。