针对Tor匿名通信网络的去匿名化技术研究
作者: 李兵
关键词:Tor匿名通信网络;去匿名化;深度学习
1 简介
洋葱路由(The Onion Router) 简称Tor,是一个用于实现匿名通信的免费开源系统[1],可以隐藏用户的位置和使用情况,避免被网络监视。研究人员一开始设计Tor的目的是用于保护美国军方的在线情报通信。后来随着Tor代码的公开,Tor现在已经成为最成功的公共匿名通信服务,每天有超过200万的用户使用Tor系统进行匿名通信。
Tor通过全球志愿者运行的中继网络对通信进行加密,然后随机反弹。这些路由器以多层方式使用加密,来确保中继节点之间的前向保密,从而为用户提供网络位置的匿名性。
Tor使其用户能够匿名上网、聊天和发送即时消息,通过保持其互联网活动不受监控来进行保密通信,为持不同政见者、记者、告密者、企业、甚至普通用户都提供了良好的隐私保护功能,是一个面向普通用户的低延迟的匿名通信系统。
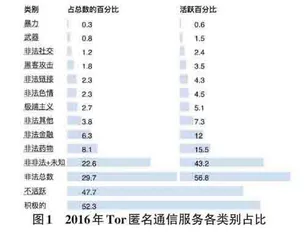
但是,由于Tor提供了匿名、防溯源的功能,是暗网(Dark Web) 的重要组成部分,通过使用Tor匿名通信技术,暗网用户的身份和位置保持匿名,无法追踪,以致犯罪分子从事非法活动可以规避司法审查。2016年Tor匿名通信服务各类别占比如图1所示。可以看出,Tor 上最常托管的内容类型是各种非法内容,包括非法药物、非法色情、黑市武器交易、黑客攻击等。
为了追踪那些利用Tor摆脱监控的犯罪分子,加强对网络空间的安全控制,亟须对Tor匿名通信进行深入分析和研究。近年来,对Tor匿名通信网络的研究成为众多学者关注的焦点。
虽然Tor能够避免流量传输过程的分析,但却不能阻止流量在输入输出时的确认。Tor为了保证日常的网络浏览具有低延迟的特性,没有使用混淆流量特征等可能导致连接变慢的技术,从而给了可乘之机,人们可以通过特定的方法观察用户的输入输出流量,对Tor匿名通信网络的流量进行分析,进一步识别用户浏览的网页,从而破坏Tor通信网络的匿名性。
现有针对Tor通信网络进行流量分析,破坏匿名性的技术可以分为主动流量分析和被动流量分析两种:1) 主动流量分析技术。根据特定模式改变流中数据包的时序,并在网络的另一端寻找该模式,从而可以将一侧的流链接到网络的另一侧并破坏它的匿名性,但是由于流量被改变,隐蔽性较差。2) 被动流量分析。从网络一侧的特定流的流量中提取特征,并在网络的另一侧寻找这些特征,虽然需要长期观察和记录大量的数据,但具有较好的隐蔽性。根据流量位置的不同,被动流量分析又可以分为两类:(1) 网站指纹分析。利用网站内容的差异,通过网络流量推断出用户访问的网站,从而实现去匿名化。(2) 流量关联分析。通过观察并关联进入和离开Tor匿名网络的流量,关联两端的流量,从而破坏Tor的匿名性。
近年来,研究人员利用传统机器学习或深度学习算法,提出了一系列的网站指纹分析方法和流量关联分析方法,并取得了较高的精度。
2 背景知识
2.1 Tor 匿名通信网络
Tor是最受欢迎的匿名通信网络,该网络由6000 多个中继节点组成。
2.1.1 匿名原则
Tor匿名通信网络包含三个代理服务器。需要匿名服务的用户首先在本地运行洋葱代理服务器。洋葱代理服务器负责通信链接建立和数据加密工作。它与目录服务器进行通信,获得全球活动的中继节点信息,然后随机选择三个节点(入口节点、中间节点和出口节点)组成回路。用户的流量经过这三个节点,最后到达目标网站服务器。系统每隔10分钟左右就会重新选择三个节点,每个节点只知道部分信息,这样就能达到匿名的目的。
2.1.2 洋葱服务
Tor 还可以为网站和其他服务器提供匿名性。配置为仅通过Tor 接收入站连接的服务器称为洋葱服务(Onion Services) 。洋葱服务通过Tor 浏览器访问,而不会透露服务器的IP 地址或网络位置。Tor 网络通过从网络内的分布式哈希表中查找它们对应的公钥和引入点来理解这些地址。由于洋葱服务的流量完全通过Tor 网络进行路由,因此与洋葱服务的连接是端到端加密的,很难成为窃听的目标。Tor为洋葱服务和Tor用户提供相互匿名,这意味着互相知道对方的IP地址。洋葱服务和客户端之间的默认路径有六个中继站,通过洋葱服务协议连接。
2.1.3 封闭世界/开放世界场景
Tor进行实验测试通常在两种场景下进行:封闭世界场景和开放世界场景。1) 在封闭世界场景,假设用户只能访问攻击者所监控的网站。例如,如果攻击者监控了100个网站并提取了它们的网站指纹特征,那么用户就只能访问这100个网站。这种场景不够现实,因为现实世界中存在大量的网站,而且用户的选择范围很广。2) 在开放世界场景,用户可以像在现实生活中一样自由访问任何网站,而不局限于被监控的那一组,更加具有现实意义。
2.2 机器学习
机器学习(Machine Learning, ML) 是人工智能研究过程中的一个产物,它是一种可以学习的算法。机器学习可以划分为几个阶段:1) 数据收集。数据能够反映事物的特点和属性;2) 模型训练。利用训练数据和对应的标签对模型进行训练,得到能够预测未知的模型;3) 模型预测。把新的数据输入到训练好的模型中,进行预测。
根据预测值,机器学习可以分为分类模型和回归模型。分类模型预测的结果是一个离散的值,如标记是“好”或“坏”。回归模型预测的结果是一个连续值,例如概率“99%”。本文研究的网站指纹攻击和流量关联分析利用的都是分类模型,只判断用户是否访问某一个网站。
2.2.1 传统机器学习
传统的机器学习算法包括支持向量机(SupportVector Machine, SVM) 、k 最近邻(k-Nearest Neighbor,k-NN) 和随机森林(Random Forest, RF) 算法等。传统的机器学习算法需要事先手动设置训练数据的特征。例如,为了识别猫的种类,需要手动设置猫的特征,包括眼睛、耳朵和头发等。然后通过分析训练数据来训练模型。随着数据数量的增加,模型的识别准确率也会增加,但最终会趋于平缓,达到收敛效果。传统的机器学习算法不适合大数据分析,因为它们不能自动提取特征。
2.2.2 深度学习
深度学习(Deep Learning, DL) 产生于20世纪,当时由于缺乏数据,效果并不理想。随着大数据时代的到来,深度学习的性能大幅度提升,在处理复杂对象如语音和图像方面具有强大的性能。深度学习是机器学习的一个子集,本质上是一个多层的神经网络。神经网络从大量数据中自动“学习”,试图模拟人脑的行为。
深度学习可以自动提取特征,不再需要手动设置特征。特征是在自己的神经网络中逐层分析中获得的。第一层的特征可能是模糊的,但经过逐层训练,区分样本类别的特征会越来越明显。例如,有一组不同宠物的照片,我们想按动物种类进行分类,深度学习可以自动确定哪些特征(例如耳朵)对于区分每种动物最重要。而在传统机器学习中,这种特征层次结构是由人类手动设置的。深度学习随着数据量的增加,性能也会增加。
3 针对Tor 匿名通信网络的去匿名化技术
Tor作为目前最流行的匿名通信网络,针对Tor去匿名化技术研究是学者们关注的焦点。针对Tor的去匿名化技术可以分为两类:网站指纹分析技术和流量关联分析技术。
3.1 威胁模型
3.1.1 网站指纹分析模型
网站指纹分析是利用网站内容的差异,通过进入Tor网络入口的流量推断出用户访问的网站。我们可以通过观察数据包的序列特征(如数据包时间、方向等)获得用户访问过哪个网站的信息。
具体来说,不同的网站有不同的流量模式,浏览某一组网站,从入口流量中提取网站的独特指纹特征。然后利用机器学习方法进行训练,训练得到一个分类器,它的输入是用户的入口流量,输出是访问对应的网站概率。
当用户通过Tor匿名通信网络浏览网站时,可以通过记录下用户和入口节点之间的流量,提取他们需要的网站指纹特征,然后与已知的网站指纹信息相匹配,获得网站信息。
通过这种方式,可以知道用户正在访问的是哪个网站,成功地实现对Tor的去匿名化。网站指纹分析对Tor的匿名性构成了巨大威胁。具体威胁模型如图2所示。
3.1.2 流量关联分析模型
流量关联分析也被广泛用于实现针对Tor匿名通信网络的去匿名化。同时观察记录进入和离开Tor匿名通信网络的流量,然后通过关联两端的流量对Tor 进行去匿名化。
图3显示了流量关联分析的威胁模型。为了实现去匿名化,需要控制大量的恶意中继节点,或窃听自治系统(Autonomous System, ASes) 和互联网服务提供商(Internet Service Provider, ISP) ,从而可以在Tor连接的入口中继和出口中继处截获流量。
由于Tor匿名通信网络加密,无法通过检查数据包的内容来确定入口和出口流量是否有关联,所以需要通过流量特征(如数据包的时间、大小、方向等),将属于同一用户的流量在两端关联起来,从而确定特定用户正在访问哪个网站,实现针对Tor的去匿名化。
3.2 网站指纹分析
由不同信息形成的网站的流量会有不同的表现,所以可以将网站流量信息作为网站的指纹。第一步是找出网站流量最容易区分的特征,例如,浏览网页时发送的数据包的数量、大小、方向等。每个特征数据对应一个网站标签,数据和标签作为训练数据集,训练网站指纹分类模型,使同一网站的数据属于同一类别。训练好的分类模型在输入待识别的网站特征数据时,能够输出每一个标签的概率,从而找到用户在访问哪一个网站。
现有网站指纹分析的工作主要分为两类:一类是基于传统机器学习的方案,一类是基于深度学习的方案。传统机器学习的方案,不能处理大规模的数据,性能有待提升。基于深度学习的方法可以充分利用数据的信息,最后的准确率往往优于基于传统机器学习的方案。
3.2.1 基于传统机器学习的网站指纹分析
现有基于机器学习的网站指纹分析工作广泛采用SVM、k-NN、RF等算法训练网站指纹分类器。当用户浏览网站时,对流量信息进行分析,判定在浏览哪一个网站。
针对Tor匿名通信网络的网站指纹分析研究工作可以追溯到2009年,并在近几年快速发展。但是,以往工作中使用的指纹特征往往是从网站的某个页面提取的,而不是整个网站中提取的,所以称之为“网页指纹”更为恰当。
文献[2]指出网页指纹识别是非常不可靠的,并首次将网页指纹特征进一步丰富为网站指纹特征。同时这项工作提出了一种新颖的网站指纹分析方法,具体来说,将网页的加载过程抽象为一个特征,从而可以分析网页痕迹的累积行为。
文献[2]通过截取一段用户流量,记录了数据包的大小。在求和的过程中插入100个数,从而得到一个固定长度的输入特征。这个特征在拥堵、带宽、页面加载时间等方面表现出较大的稳健性。文献[2]采用了LibSVM算法训练得到分类模型,达到了比当时最先进的方法更高的识别准确率。
由于网站指纹分析的性能往往与所使用的特征和分类器有关,所以相关研究特别注重改进所使用的数据特征和分类器。文献[3]提出了一种新颖的指纹特征提取方法,该方法利用RF分类器对多种网站跟踪特征进行提取,生成固定长度的特征向量,其包含175个特征。RF算法由多个决策树组成,每个决策树选择一个特征进行分类,因此RF算法在特征选择方面具有较大的优势。
然后文献[3]采用k-NN分类器对特征向量进行训练和分类,将特征数据与每个网页标签进行匹配,以找到最佳匹配标签。由于k-NN算法适合于分类任务,该方法的性能与文献[2]相似。文献[3]模型特征提取和分类器训练阶段利用了不同的机器学习算法,并发挥了每种算法的优势。文献[3]还分析了以前工作中使用的各种特征,发现一些简单的特征(如数据包的数量)比一些复杂的特征(如数据包到达时间)提供的信息更多。他们在正常页面、部署了网站指纹防御的页面以及洋葱服务页面上进行了大量实验测试,实验结果表明,文献[3]的准确性优于现有工作。