注意力机制优化SSD的戴口罩人脸快速检测研究
作者: 苏海涛 张守棋
关键词: DynaNet-SSD;SE注意力机制;小目标检测;人脸检测;Focal Loss;Mosaic
0 引言
新冠疫情感染期间,佩戴口罩成了一种常态化的现象。口罩成为预防呼吸道传染病的一道防线,可以降低新型冠状病毒感染风险。因此,采用神经网络的方法对人是否佩戴口罩的检测[1]具有重要的研究应用价值。
目标检测是计算机视觉和图像处理中一个重要的研究领域。随着大数据时代的到来,基于深度学习的目标检测方法成了研究热点,虽然检测精度远超过传统的方法,但是仍然无法同时满足对于实时性和准确性的要求。
而戴口罩人脸检测实际上属于人脸检测与图像分类[2]问题,即使用目标检测网络配合图像分类网络,首先确定人的面部位置,然后将图像分类为未佩戴口罩、已佩戴口罩两种情况。同时,口罩数据集较少、佩戴口罩的场景多样化、对模型运行速度的要求等情况,也成为口罩人脸检测中必须考虑的问题。
1 相关工作
随着大数据的出现,计算机硬件性能稳步增强,人们对于目标检测算法的实时性和准确性有了更高的要求,对应的,逐渐加深网络的深度,加大网络的宽度,模型复杂度也随之增高,人们对于计算能力的要求越来越高,加大了训练的难度和时间的消耗。保证网络性能的前提下减少网络参数,压缩网络模型也成了目标检测任务中的一个方向。
MobileNet-SSD[3]算法是将SSD算法中的VGG16[4]特征提取网络替换为MobileNet特征提取网络而建立的算法。在没有减少准确率的情况下,适当减少了网络参数,综合了准确率与速度两个指标。
目前,基于MobileNet-SSD目标检测模型相关文献多是针对特定领域当中的单个类别中单一目标提升检测性能和识别效果,在复杂度较高的图片中对于多类别多目标的检测研究相对较少,特别是针对小目标的检测[5]仍然具有一定的研究价值。
为了平衡网络模型的大小和检测速度,轻量级网络MobileNet 结合SSD 框架可以实现快速的目标检测,MobileNet-SSD能够有效地对网络模型的大小进行压缩,并提高检测速度。但其在戴口罩人脸检测上存在以下问题:
1) 小目标戴口罩图片中,戴口罩人脸检测不全,即召回率偏低。
2) 小目标戴口罩图片中,个别人脸模糊不清,导致准确率偏低。
本文修改MobileNet-SSD的基础网络模型,添加参数计算量小的注意力机制模块,使用Mosaic数据增强算法扩充小目标数据,使用Focal Loss[6]替换Soft⁃ max Loss损失函数,在没有牺牲检测时间的前提下,提高了戴口罩人脸检测效率和识别准确率。
2 戴口罩人脸检测相关技术分析
2.1 SSD 网络简介
SSD算法[7]属于区别于R-CNN的[8]one-stage(训练单个网络)多框预测方法。取决于SSD多尺度特征映射特点,SSD 算法采取了不同尺度的特征图进行检测,并设置了不同尺度以及不同宽高比的先验框(an⁃ fcahuelrt bbooxx))[。9]对然其后进将行这预测些,候得选到框多通个过不同非的极候大选值框抑(d制e⁃(NMS)[10]方法,得到最终类别和最终位置。
相比于Faster R-CNN[11]和YOLO[12]等目标检测模型,SSD结合了YOLO算法的回归思想,并将全连接层以金字塔网络进行替代,从而提取到更多特征,同时又借鉴了FasterR-CNN中的anchor机制,设置了不同长宽比的先验框, 在复杂场景下多目标的情况下,多数修改基础网络形成新SSD算法,小目标检测性能优于YOLOv3[13]和FasterR-CNN,又基于MobileNet 网络参数小的特点,在检测时间方面检测速度相比于Reti⁃ naNet[14]和YOLO V5[15]更快。
2.2 SSD 多尺度映射
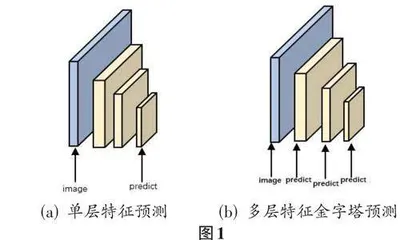
SSD采用特征金字塔结构[16],具有多尺度特征映射的特点,对任意的一幅图片均通过卷积,生成不同尺度的特征图层进行预测,如图1:
(a)只对最后特征图层输出的特征信息进行预测,图(b)对不同尺度的特征图层进行预测。
2.3 MobileNet-SSD
MobileNet-SSD[17]是在SSD网络基础上,使用轻量级卷积神经网络MobileNet 替换SSD 中的VGG16 网络。
MobileNet-SSD的工作过程如下:采用特征金字塔思想获取6个卷积层的特征信息,用来进行多尺度多目标的目标检测,最后进行目标分类和候选框回归。
事实上,MobileNet-SSD 网络模型用来做目标检测的6层特征图分别为:Conv11(F-map1) 、Conv13(F- map2) 、Conv14_2(F-map3) 、Conv15_2(F-map4) 、Conv16_2(F-map5) 、Conv17_2(F-map6) 。对应大小分别为19×19×512、10×10×1024、5×5×512、3×3×256、2× 2×256和1×1×128(用F-map来表示某一特征图)。
在MobileNet-SSD网络中,小物体只有在低位特征图层中特征相对明显,在高位特征图层中经过卷积,特征信息相比低位特征图层少,因此对于小目标检测效果较差。
3 DynaNet-SSD 算法的设计及实现
MobileNet-SSD算法的基础上修改,在数据集方面,通过添加Mosaic数据增强算法[18]扩充数据,使数据集中包含更多小目标戴口罩人脸图片。
网络结构方面,在保留MobileNet的深度可分离卷积的前提下通过修改Conv5和 Conv12为1×1的卷积核,整体修改MobileNet网络结构,形成新网络Dy⁃ naNet,DynaNet包含更多感受野小的特征图层,以及相比于MobileNet更少的参数,并通过感受野小的特征图层进行预测。
同时在Conv5层之后添加一个通道注意力模块,即SE模块,SE模块使用全连接层计算量相比于增加一个卷积层更小,同时SE模块添加在已有的网络上并不会打乱网络原有的主体结构。
在损失函数方面,本文选取Focal Loss二分类类别损失函数代替原网络中Softmax千分类损失函数,通过减少负样本的权重,将损失函数聚焦于正样本中难分辨的类别。最后形成新的DynaNet-SSD算法。
3.1 Mosaic 数据增强算法
Mosaic数据增强算法,是一种针对于小物体检测的数据增强算法。Mosaic数据增强参考了CutMix数据增强方式[19],理论上具有一定的相似性。CutMix数据增强方式利用两张图片进行拼接,但是Mosaic利用了4张图片,极大地丰富了检测物体的背景。
实现思路:先选取4张图片,分别对4张图片进行随机翻转、缩放等,最后按照4个方向拼接到一起。Mosaic流程可视化图如图2所示:
通过Mosaic数据增强算法拼接图片增强了数据集,也把原来大型和较大型的物体缩放缩小组合,使得数据集中的小物体增多,提高了算法检测小物体的精度,如图3所示:
3.2 DynaNet-SSD 特征提取网络
考虑戴口罩人脸检测场景,图片中的人脸相距较远,人脸占比例较小,属于小目标戴口罩图片(人脸占比小于15%)。本文提出的DynaNet-SSD为了能够提高小目标戴口罩人脸准确率和召回率,选取特征信息更多和感受野更小的特征图层进行候选框的预测,并对候选框中的图像进行分类,即是否佩戴口罩的分类。
MobileNet-SSD网络结构算法提取的特征图层是F-map1、F-map2、F-map3、F-map4、F-map5、F-map6。检测小目标的特征图层是F-map1特征图层。
鉴于38×38(F-map1的前一层)的特征图在进一步的卷积过程中会丢失局部特征信息,所以在设计DynaNet-SSD网络结构时,提取38×38的特征图层作为第一特征图。
DynaNet-SSD 沿用了MobileNet-SSD 的Conv1、Conv2、Conv3、Conv4图层,在Conv4的基础上修改卷积核的通道数,卷积之后成为新的Conv5,即DynaNet- SSD将Conv5(38×38×512的特征图层)作为其第一特征图层(DF-map1即DynaNet的第一特征图,以下均用DF-map表示DynaNet选取的特征图),具体流程如图5所示:
DynaNet-SSD在Conv11层修改卷积核通道数,卷积之后形成Conv12(19×19×1 024的特征图层),作为Dmyanpa2N) 。et-SSD 网络提取的第二个特征图层(DF-在Conv12之后的特征图层中,用3×3的卷积核和(1D×F1-的ma卷p3积) 核、进Co行nv标15_准2(卷DF积-m,a选p4取) 其、中Co的nv1C6o_n2v(1D4F_-2 map5) 这三层作为特征提取层,特征图层的大小分别为10×10×512、5×5×256、3×3×256。DynaNet-SSD提取的特征图层相比于MobileNet-SSD提取的特征图层,包含更多小比例人脸特征信息。
SSD算法提取大物体特征明显,在最高位特征图层中检测效果较好,在实际的应用中几乎不会出现大物体漏检错检的情况。所以DynaNet-SSD网络选取Conv17-2(1×1的特征图层,即DF-map6) 作为最后一个特征图。
3.3 添加SE 注意力机制
在第一特征图层后,即 Conv5 层之后添加 SE (squeeze-and-excatation) 模块,由于第一特征图层存在小目标信息较多,通过SE模块更好地提取小目标人脸边界信息,防止卷积过程中有效信息的丢失,同时SE 模块参数量相较于其他注意力机制更少,在不损害检测时间的情况下,提高小目标人脸的检测准确率。
最后是scale操作,在得到1×1×C向量之后,就可以对原来的特征图进行scale操作了。很简单,就是通道权重相乘,原有特征向量为W×H×C,将SE模块计算出来的各通道权重值分别和原特征图对应通道的二维矩阵相乘,得出的结果输出。
总体来说,SE模块会增加网络的总参数量、总计算量,因为使用的是全连接层计算量相比卷积层更小,但是总参数量会有所上升。
3.4 MobileNet-SSD 和DynaNet-SSD 网络结构比较
DynaNet-SSD 整体结构对比图如图6 和图7 所示:其中,Conv14 层之前都进行深度可分离卷积,Conv14层之后进行标准卷积。
38×5D12y,na相N比et-于SSDMo选bi取leN的et第-S一SD特的征第图一层特C征onv图5层是1398×× 19×512包含更多的特征信息;第二特征图层Conv12 是19×19×1 024相比于MobileNet-SSD的第二特征图层10×10×1 024包含更多特征信息;第三特征图层至第六特征图层都是大感受野图层,在小物体方面并没有很大的提升。
以上阐述了相对于MobileNet-SSD的改进思路,为了更直观地分析两种算法的结构,制作了两种不同算法的网络架构图。
3.5 Focal Loss 损失
目标检测损失函数包含两方面损失,分别是位置信息损失与类别信息损失(戴口罩或不戴口罩两类)。
MobileNet-SSD 的位置损失采用L1 距离度量的Smooth Ll Loss策略[20],见公式(4) ,其中,xp ij log2 (ĉpi)是预测框i 与真实框j 关于类别p 是否匹配,若p 的概率预测越高,损失越小,类别的概率公式具体参考公式(1)。