基于XGBoost的企业排污违法概率评估模型
作者: 邱文韬 黄楠 李俊 李江华
关键词: XGBoost;GMM;污染排放;排污违法行为
中图分类号:TP181 文献标识码:A
文章编号:1009-3044(2023)22-0018-04
0 引言
近年来,我国愈发重视生态环境的保护,环境监管力度不断加强。以江苏省为例,截至2021年3月,全省已发放排污许可证35 000张,基本实现全覆盖。然而,由于排污单位自行监测在固定污染源排污许可制度中占据重要地位, 自行监测实施质量直接影响排污许可制度实施效果。目前,根据企业排污数据判别相关违法行为的研究较少,与监督性监测相比, 排污单位自行监测的基础相对薄弱[1]。因此,通过建立并训练数据模型,借助模型强大的计算能力对企业污染排放行为进行已有数据的归宗辨识,辅助环保部门识别企业是否可能存在偷排、篡改数据或者伪造数据等违法行为很有必要。
1 研究现状回顾
1.1 机器学习在排污监管中的应用研究
机器学习已经被广泛应用于解决各种各样的现实问题,王军霞等人[1]提出按照数据标识判别、单源数据分析、多源数据分析3个层次对监测数据进行分析, 以识别监测数据存在的问题。魏艳等人[2]基于大量污染源自动监测数据的特征分析与异常原因解析,探索建立针对自动监测异常数据的识别规则与标志处理方法,并通过模型训练实现了异常数据的自动标志,该方法按照数据有效性及异常原因进行标志处理,可以为后续数据分析及各类模型训练提供数据基础和保障。陈冲等人[3]对企业催化裂化的监测数据开展数据异常识别研究,从算法的分支步骤与局部度量方面,改进孤立森林算法,提高算法性能,在多个标准数据集上与多个异常识别算法进行对比,验证算法的优越性。但均未深入研究异常数据与可能存在的排污违法行为间的联系。
1.2 XGBoost 算法在预测企业排污违法概率中的应用
本文主要研究XGBoost算法用于预测企业排污违法行为概率,该算法由陈天奇[4]在2016年提出,是在GBDT(Gradient Boosting Decision Tree, 梯度下降树)算法基础上进行的改进,在特征粒度上实现了并行,可以利用CPU的多线程进行学习,提高了算法的效率。XGBoost算法在预测准确率、不易过拟合和可扩展性方面明显优于随机森林、决策树、朴素贝叶斯等算法。Boosting分类器[5]属于集成学习模型,张旭春等人[6]基于黄河流域治污企业的历史环保数据与电力数据,构建了基于Boosting的集成算法CatBoost和AdaBoost的模型预测污水处理厂的告警类型。王为久等人[7]采用XGBoost算法构建了非法经营罪的自动量刑预测模型,并与线性回归、决策树、随机森林、最近邻算法等进行比较,结果证明采用XGBoost算法构建的量刑预测模型在多分类问题和回归问题的预测中均高于其他方法。Shrestha等人[7]基于尼泊尔的电信行业流失客户数据,采用XGBoost算法构建客户流失的预测模型,解决了多数机器学习算法无法解决的如何有效考虑数据集不平衡性质的问题。当前研究多使用GBDT 及CatBoost等,但性能表现出色的XGBoost算法较少应用于预测企业排污违法行为及概率。
2 排污违法行为评估模型构建
2.1 企业排污数据分析
1) 数据来源
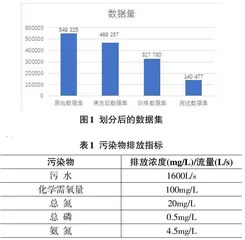
所采用的数据集来自河北省99 家企业2020—2021年的历史排污数据,该数据集共有549 325条记录,每个记录包含6个字段,分别是企业编号、排污口编号、污染物种类、排放时间、排放浓度/流量以及排放总量。
2) 数据预处理
数据处理包括数据导入、数据清洗和数据存储三个步骤。首先在Linux系统下配置每个步骤所需的环境,并设计数据处理的数据流。数据导入阶段将原始数据导入Hdfs,再写入Hive中。数据清洗时,使用清洗规则清除缺失字段的数据,仅保留常见的五类污染物数据,并清除时间维度很少的数据,将清洗好的数据输出到Linux系统中,准备导出。数据存储时,使用Sqoop 将处理后的数据输出到MySQL 中。共有468257条可用数据,选取7:3的比例对数据集进行分割,具体分布见图1:
3) 数据分析
参考《中华人民共和国环境保护法》第四十四条,企业应当遵守分解到本单位的重点污染物排放总量控制指标。为贴合实际模拟企业的污染物排放,数据集扩充时只选择普遍排放的五种污染物进行记录:化学需氧量、总氮、总磷、氨氮、污水。根据《中华人民共和国国家标准污水综合排放标准》,确定了69种水污染物的最高排放浓度和行业排水量,将主要污染物的排放指标细化如表1所示:
魏艳等人[2]对数据异常特征与原因进行了分析,将自动监测数据的异常表现总结归纳为6种类型,分别是异常偏高、异常偏低、异常为0以及逻辑错误等。《水污染源在线监测系统(CODCr、NH3-N等)数据有效性判别技术规范》(HJ 356—2019)也为如何进行有效数据的人工判别提供了流程和方法指引。
4) 标准化处理历史数据的字段名如表2所示。
对数值不连续的business_id和outfall_id 字段采取LabelEncoder编码。将rtime字段拆分为年year、月month、日day。对year进行one-hot编码,使用map()函数提取month day。pollu_id有五类,其初始数据类型为字符串,无法体现特征的联系,所以进行one-hot 编码。
对pollu_pl和pollu_am特征进行标准化处理。原因:不同企业或不同排污口排放同一种污染物时,排放浓度和排放标准均不相同。例如,污水排放流量的阈值远高于总氮排放的阈值,且数据差异较大。为了避免数据偏差,需要在特征处理时进行标准化处理,使数据符合均值为0,方差为1的正态分布。标准化公式如下所示:
2.2 模型介绍
根据生态环境部印发的《环境监测数据弄虚作假行为判定及处理办法》以及《排污许可管理条例》,需要重点监控的排污违法行为主要有篡改、伪造自行监测数据以及偷排偷放等。因此根据排污违法行为分类的要求和原始数据的特点,可通过聚类找出正常数据。首先使用kmeans算法进行初始聚类,再用GMM 算法进行聚类。由于正常数据占比最多,将聚类后最多的数据归为正常类型,其余数据划分为异常类。使用kmeans聚类对四类异常进行细分:篡改、伪造、偷排、其他。
k 均值聚类算法是一种迭代求解的聚类分析算法,其步骤是,将数据分为k 组,随机选取k 个对象作为初始聚类中心,计算每个对象与各个聚类中心之间的距离,将每个对象分配给距离最近的聚类中心。使用kmeans进行聚类后,可得到如图2所示的效果。
kmeans 对不是圆形的簇拟合效果差,所以用GMM模型再进行一遍聚类,将kmeans和GMM聚类后重复的index进行去重,然后将GMM和kmeans聚类后对每一簇的标签进行统一。
3 模型性能测试与结果分析
在训练模型时,有70%的数据用作训练集,30% 用作测试集,通过使用机器学习中评价模型常用的平均绝对误差(MAE)、均方根误差(RMSE)与平均绝对百分比误差(MAPE)作为XGBoost 模型、GBDT和随机森林模型的性能评价指标,对企业排污行为违法概率的预测结果进行评价,结果如表3所示,得出 XGBoost 预测模型在平均绝对误差、均方根误差和平均绝对百分比误差方面均优于传统的随机森林模型,说明XG⁃Boost模型具有更好的可行性。
对各模型判定的企业排污数据正常概率进行对比,可以看出XGBoost预测结果最接近真实数据,而GBDT、随机森林次之,如图5所示:
4 结束语
本文填补了XGBoost算法在企业排污违法概率评估方面的应用研究,基于河北省企业历史两年内排污数据,参照相关法律条文及文献制定数据超标及可疑数据的判定标准,运用大数据技术对数据进行预处理,结合机器学习聚类算法无监督特征提取的特点,对大量数据进行分析与分类,提取各类可疑违法数据的特征,尝试将XGBoost算法运用于预测企业排污违法概率中。从实验结果可以看出,XGBoost算法应用于预测排污数据违法概率是可行的,且性能较传统机器学习算法更优,但由于XGBoost算法在评估污染排放违法概率的应用研究较少,本文没有对模型进一步优化,将来可以进一步改进模型来提升模型精度。