基于改进DBNet的招牌文本检测研究
作者: 倪健 池祥
摘要:店面招牌文本是街景图像中的重要信息,招牌信息与地理信息结合用途广泛,为了发掘招牌中的文本信息,实验采用计算机视觉技术,提出一种基于DBNet算法改进的招牌文本检测方法。首先,利用ResNet残差网络提取招牌文本特征;其次,提出一种残差注意力路径聚合网络替换原有金字塔网络,增强多尺度特征融合;最后,对融合增强的特征通过可微分二值化操作加速文本后处理来得到近似二值图,以完成招牌文本与背景的分割。实验结果表明,该方法能够有效地检测出招牌中的文本。
关键词: 招牌文本检测;计算机视觉; DBNet算法;残差注意力路径聚合网络;可微分二值化
中图分类号:TP18 文献标识码:A
文章编号:1009-3044(2023)25-0001-03
开放科学(资源服务)标识码(OSID) :
0 引言
随着服务业的迅猛发展,街道上充斥着各种各样的店面招牌。街景下的招牌文本蕴含着大量宝贵信息,自然场景下的文字检测识别也是计算机视觉领域的重要研究方向[1],将两者结合并辅以地理信息,将来可以应用于地图导航、店铺推荐、智能城市规划分析、商业区商业价值分析等实际落地领域,具有很高的研究价值和业务使用价值。
招牌文本识别的前提是招牌文本检测,因此准确且全面地检测出招牌图像中文本十分必要。街景图像中的招牌文本背景复杂,受光照和角度的影响较大,且招牌中的文本具有不同的尺度、形状、方向和弯曲程度,因此基于手工特征提取的传统文本检测算法适应性与抗干扰较差。目前深度学习场景文本检测方法主要分为基于候选框回归的方法与基于分割的方法[2]。基于候选框回归的方法如EAST[3]算法把完整文本行先分割检测再合并,先进行候选框选取过滤,再进行候选框回归合并,检测速度虽快但是无法检测弯曲文本。基于分割的方法如PSENet[4]渐进的尺度扩展算法,虽能基于像素级的预测弯曲文本,但是需要对同一个文本进行多种预测,使其无法达到实时检测的可能。
本文采用基于分割的DBNet算法对街道上的招牌文本进行检测,旨在解决不规则招牌文本检测困难与检测耗时的问题。首先,利用ResNet网络结构训练大量真实场景数据集,其次,经过残差注意力路径聚合网络进行特征融合增强,最后,通过可微二值化操作加速文本后处理获近似二值图,以实现招牌文本的检测。
1 模型方法
1.1 DBNet算法
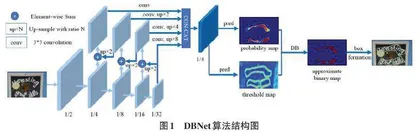
DBnet算法是基于像素分割的,可以满足实时检测的场景文本检测算法[5]。DBNet算法(见图1)可以大致为3个部分:特征提取、特征融合增强和文本后处理。待检测的图像经过ResNet-50特征提取网络得到4个特征图,分别为原图大小为1/4、1/8、1/16和1/32,FPN网络分别将4个不同尺度的特征图进行上采样融合拼接得到特征图F,由特征图F经过头部网络得到与原图大小相同的概率图P(Probability Map) 与自适应阈值图T(Throshold Map) ,将概率图与自适应阈值图进行可微分二值化操作得到近似二值图B(Approximate Binary Map) ,从而获取文本框边界。训练期间对P、T、B进行监督训练,P与B受到相同的监督,P与T的标签由对文本标注框进行膨胀缩放制作而成,膨胀和缩放使用相同的偏移系数,而推理过程时,只需要概率图就可得到结果,无须进行可微二值化操作。该算法虽然检测速度快,但是由于金字塔网络特征融合方式较为简单,导致融合生成的特征图存在细节特征丢失的问题,导致其标定的文本框拟合不够准确。
1.2 可微二值化
在特征融合后进行文本后处理,生成大小相同的概率图与自适应阈值图,将概率图与阈值图进行微分二值化操作生成文本检测最后的结果,可微二值化公式如下:
[Bij=11+e-kPi,j-Ti,j ] (1)
其中,[Bij]为近似二值图上点[i,j]的值,[Pij]是为概率图上点[i,j]的值。[Tij]是自适应阈值图上中点[i,j]的值,为[Pij]的阈值。k是一个超参数,当k=50时,此时可微二值化可以将文本区域与背景区域更好地区分,还可以分离粘连在一起的文本实例,由于此二值化过程是可微分的,当k为50时会产生较大的损失,便于模型优化[5]。
1.3 标签制作
不规则文本区域通常是由多点连线包围而成,先使用Vatti裁剪算法对文字区域进行裁剪,再将原始的文本框收缩膨胀(见图2) ,收缩膨胀的偏移量根据原始文本框的周长和面积进行计算,偏移量D计算方式如下:
[D=S1-r2L] (2)
其中,S、L 分别代表文本框面积和周长,r 代表收缩率,本文设置为0.4。通过收缩标注框(图2红色边界)距离D得到收缩边界(蓝色边界),收缩边界的内部区局为概率图和近似二值化图的标签。向外扩张同样的距离D,收缩边界和膨胀边界之间的间隙(蓝色边界和绿色边界之间的区域)为自适应阈值图的标签,该区域的值预设为0.7,其他区域的值预设为0.3。
1.4 损失函数
在训练过程中,自适应阈值图单独受到监督,概率图与近似二值图受到相同的监督。损失函数可以分为三个部分:概率图损失[Lρ]、阈值图损失[Lt]和近似二值图损失[La][5]。具体表达如下:
[L=Lp+α×La+β×Lt] (3)
考虑到阈值图的结果会影响到近似二值化图的损失,参数[α]、[β]在实验中分别设置为5和10。
1.5 残差注意力路径聚合网络
针对金字塔网络特征融合简单而导致文本框拟合不够准确的问题,改进后的特征融合增强网络采用残差注意力路径聚合网络(见图3) ,将原来单向融合的方式增加反向融合,并且在原有3×3卷积核之后加入残差结构SE注意力机制,基于通道注意力机制的路径聚合网络融合低分辨率但强语义信息的特征图与空间信息丰富但语义信息较弱的特征图,实现空间信息与语义信息双向流动,减少细节特征丢失。该网络融合多层特征,提高检测算法对不同招牌文本尺度的检测能力,这适合于招牌中既有大字体文本行也有小字体文本行的特性。
SE(Squeeze-Excitation) 注意力模块主要由全局池化层、全连接层、relu激活函数和sigmoid组成(见图4) 。squeeze阶段将特征图进行全局平均池化,特征图压缩为长度为通道数的一维向量,对每个通道信息进行特征融合,使一个数值表示该通道的全局感受视野,excitation阶段将特征向量经过两层全连接与激活函数后生成通道权重值,用于表示每个通道的重要性。scale阶段将通过生成的通道权重与特征图相乘,实现通道特征重要性的重新标定。然而改进的路径聚合网络为轻量级网络,特征通道数相对较少,SE注意力模块可能会抑制一些包含重要特征的通道,为缓解这个问题,为SE注意力模块引入残差结构,尽可能保留通道中重要的信息。
2 数据收集与增强
实验选取真实场景招牌文本数据集ReCTS,随机从20 000张中选取16 000张为训练集,4 000张为测试集,该数据集是在不受控条件下采集,招牌上的文本存在中文特有的设计和排版,同时也兼有拍照角度与光照变化等干扰因素。
实验中数据增强策略包括翻转变换 (Flip)、仿射变换(Affine) 、尺寸变换(Resize) 、随机裁剪(EastRandom CropData) ,训练策略采用L2正则,以上策略可以提升模型的鲁棒性与泛化能力。
3 实验结果与分析
3.1 实验环境
实验平台为BML CodeLab,CPU为4核,显卡为V100,内存为32 GB,开发环境为Python3.7、PaddlePaddle 2.2.2、CUDA11.2、ResNet-50等。
3.2 评估指标
评价指标使用准确率(Precision)、召回率(Recall)以及利用这两个值调和计算的平均得分(Hmean),这三个指标来评估算法的性能[6],计算公式如下所示:
[Precision=TpTp+Fp] (4)
[Recall=TpTp+Fn] (5)
[Hmean=Precision×Recall×2Precision+Recall] (6)
3.3 实验结果与分析
实验选取EAST算法、PSENet算法、DBNet算法和改进后DBNet算法进行实验,图5为各算法测试效果图,图左上为EAST算法结果的结果,EAST算法对于水平文本能够较好地加测,对于弯曲的招牌艺术字只能检测到中间部分,图右上为PSENet方法对于招牌店名文本中间能够较好地拟合,但是对招牌店名两端存在漏检的情况,且对于电话号码部分的语义分割出现了问题,将电话号码分割成了两部分,图左下为原DBNet算法图,对招牌文本存在着漏检情况,图右下为改进后DBNet算法对招牌店名文本轮廓贴合效果最好,后续处理的最小外切矩阵比原DBNet算法与PSENet算法更优。
选取EAST、PSENet、DBNet、改进DBNet 4个算法进行训练,将训练好的图片在4 000张测试集上进行测试,得到表1所示的性能指标。EAST算法虽然有不错的实时性,但是精度较低,PSENet算法虽然能够检测弯曲文本,但是精度与召回率较低且无法满足实时检测的要求,改进后的DBNet算法在原有保持检测速度与召回率的前提下提升了精度。
4 结论
招牌检测的应用前景广泛,针对街景招牌文本检测问题,基于候选框回归算法无法检测弯曲文本,分割算法检测速度慢的问题,本文在DBNet场景文本检测算法上,融合残差注意力路径聚合网络,在大量真实招牌场景数据集上训练,得到了更适合招牌场景的文本检测模型。将招牌文本检测模型在4 000张测试集下进行评估,准确率、召回率、检测速度都达到了不错的指标,验证了本模型的可行性,因招牌环境复杂多变、招牌字体样式多样、光线角度等问题,仍存在很大的提升空间,也是后续的研究工作中应该重点解决的难题。
参考文献:
[1] 王潇.自然场景文字检测与识别系统[D].北京:中国科学院大学,2015.
[2] 谭钦红,江一峰,黄俊.一种基于增强特征金字塔网络的任意形状场景文本检测方法:CN114387610A[P].2022-04-22.
[3] Zhou X Y,Yao C,Wen H,et al.EAST:an efficient and accurate scene text detector[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).July 21-26,2017,Honolulu,HI,USA.IEEE,2017:2642-2651.
[4] Wang W H,Xie E Z,Li X,et al.Shape robust text detection with progressive scale expansion network[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).June 15-20,2019,Long Beach,CA,USA.IEEE,2020:9328-9337.
[5] 刘博文.自然场景中文本检测与识别方法及其应用研究[D].延吉:延边大学,2022.
[6] 骆文莉,吴秦.多层次特征融合与注意力机制的文本检测[J].小型微型计算机系统,2022,43(4):815-821.
[7] 吴雅男.基于多尺度注意残差网络的复杂地表云检测[D].阜新:辽宁工程技术大学,2021.
【通联编辑:唐一东】