基于领域词典和Sentence-BERT的智能问答系统
作者: 李强伟 王鑫 陈浩民 赵坤 仝思凡
摘要:主流的问答系统主要分为基于语义和基于文本匹配两种,而在基于文本匹配的问答模型中,通常是将问题对直接进行相似性比对进而得出最终的答案。然而,自然语言长问句一般比较冗余,如果直接进行计算,受冗余部分影响,正确率一般不高。为解决上述问题,文章提出了一种基于Sentence-Bert和领域词典的智能问答系统,旨在实现更高效、更准确地问答。系统采用领域词典来过滤问句中的冗余部分,再使用训练好的Sentence-Bert句向量模型对预处理后的问句进行向量化,并计算余弦相似度来找到最匹配的问题。实验结果表明,相比Sentence-BERT,提高了问句相似性比对的精度。
关键词:领域词典;智能问答;Sentence-BERT;FAQ;相似性比对
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2023)25-0021-04
开放科学(资源服务)标识码(OSID) :<G:\飞翔打包文件一\电脑2023年第二十五期打包文件\4.01xs202325\Image\image1.jpeg>
0 引言
问答系统是自然语言处理(Natural Language Processing,NLP) 领域的重要分支,随着自然语言处理技术的发展,对问答系统的研究也越来越多。通常认为最早的问答系统理论是由Alan Mathison Turing提出的图灵测试[1]。1966年,由Joseph Weizenbaum研发的Eliza系统,是通过模板特征实现的,即通过人工定义对话模板完成问答[2]。
问答系统通常要求以自然语言形式描述的问题为输入,并输出一个简洁的答案或答案列表,而不是一堆相关的文档。对于问答系统,主要需要解决三个问题:首先,机器需要理解用户输入的问题是什么;其次,机器需要根据这些问题的关键点检索并处理相关信息;最后,机器需要将答案返回给用户。问答系统的关键在于提高问题检索召回的精度和效率,如何合理利用现有模型和方法,达到检索系统的整体优化和性能提升[3]。目前最受关注的是基于知识图谱的问答系统,有多种方法可供选择,包括基于模板、语义解析、向量和深度学习[4]。知识图谱的问答系统有多种方法来回答问题[5]。其中,基于模板的方法使用预先设计的查询模板来匹配问题并进行查询,避免了语义解析的难题[6];基于语义解析的方法则通过分析问题的成分,构建逻辑表达式,并将其转换为知识图谱的查询语言进行查询。基于向量的方法则利用表示方法将知识图谱映射到低维向量空间,然后将问题中的实体和关系还原到相同的向量空间,并通过向量之间的距离或相似度来推理答案。最后,基于深度学习的方法则通过神经网络学习问句和知识图谱中的语义信息,获得字向量或词向量,并使用深度学习模型计算向量之间的相似度并进行排序,以推理问句的答案[7]。Bert句向量生成指的是通过Bert生成文本的句向量[8],生成的句向量能准确表征句子的语义。采用生成式的掩码语言模型(Masked Language Model,MLM),该模型是一种双向Transformer结构[9]。
原生的 Bert 在下游任务中表现出色,但是将其用于句子相似度等任务时,生成的句子向量效果不佳。为了解决这个问题,本文采用了Reimers N 等人[10]在 2019 年提出的句子向量计算模型 Sentence-BERT 模型。该模型可以获取句向量,并通过句子向量的Cosine相似度来衡量文本相似度。此外,文本句子中的冗余部分对相似度计算有很大的影响,特别是在使用词向量模型时[11]。
因此,本文根据领域知识库创建了领域词典[12],它是一种应用于具体领域的信息化工具,能够从大量语料中抽取出简洁凝练的词汇来传递某个特定领域的特征信息[13],以过滤冗余信息,支持特定领域的自然语言处理任务。最终,本文总结对句向量与去自然语言冗余的研究,提出了一种基于领域词典和 Sentence-BERT 的快速文本匹配方法,来更高效、更准确地解决问答任务。
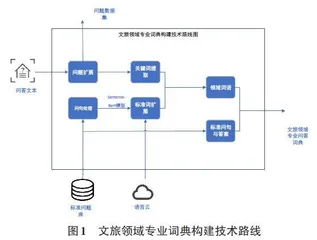
1 领域词典建立
领域词典构建模型如图1所示。首先,进行问答文本的扩展;然后对扩展好的问答文本进行关键词短语的去杂与提取,对标准类库的问题进行处理得到标准短语并进行扩展,最后整合得到每个问题的相关领域短语。最后,加入原标准问题及对应答案,完成领域词典的建立。
1.1 问题扩展与关键词提取
对爬取到的原始问题进一步扩展,按照自然语言问法进行数据标注,尽可能地覆盖所有自然语言问法。并且由此生成后续训练的问题文本数据集。
关键词语提取是对一类问题(即一个标准问题与其对应的扩展问题组成的问题集)筛选出能代表其问题核心的词语。首先对所有问题文本进行分词,使用停用词表对词堆进行第一轮筛选,过滤掉大部分词频高但是没有计算意义的词;其次,对过滤好的词使用词频权重计算,即进行关键词挖掘,最后进行排序,算法如下。
算法1:getkeywords算法
输入:所有问题分词形成的词堆Row,一类问题分词形成的词堆W,停用词表stopwords,计算TF值模型tf_Cal;计算IDF值模型idf_Cal。
输出:某类问题的关键词与权重值的字典 dict。
1: P= []
2: SP=[]
3: dict = {}
4: For w1 <- Row:
5: if w1 not in stopwords then
6: P.add(w1)
7: For word <- P:
8: For w2 <- W:
9: if w2 not in stopwords then
10: SP.add(w1)
11: dict[word]<-tf_Cal(word ,P[a,b])*idf_Cal(word , P)
12: return dict.sortByValue()
1.2 标准词扩展
通过对标准问题库的标准问题进行处理,同样进行分词和去除停用词。标准库中的问题十分精简,需要对其关键词语进行扩充,迎合自然语言的多样性,增大领域词典的处理一词多义的能力。主要做法是使用哈尔滨工业大学社会计算与信息检索研究中心研发的“语言技术平台(LTP) ”进行远程同义词获取,再使用HuggingFace提供的可直接使用的Sentence-Bert预训练模型对搜索到的同义词与1.1.2获取的同类问题关键词进行相似性比对,即保证所扩充的同义词对本问题有意义。
经人工筛选过滤掉抽取错误,选择其中的200个词语作为测试语料。设置并比较12组过滤阈值后,最终确定阈值为0.75。在此阈值下,从实验语料中,共识别出同义词48组,同义词识别准确率为50.24%,召回率为65.41%。实验整体准确率不高、召回率高的原因归结为词向量的本质是基于语料的训练结果,预训练模型在专业语义方面表现效果不是很好。因此先通过实验确定阈值μ,然后将原始词语进行自动识别同义词,然后人工进行再次验证并筛选出高质量同义词形成词典。
1.3 完善领域词典
设计领域词典的基本架构,本词典的最小单元为一个标准问题,为这些标准问题加上问题编码和分类编码。将关键词与扩展词作为该问题下的相关领域短语集,并整合问题与答案,形成最终的领域词典。
领域词典基本信息如下
[{
"sname": 问题类型,
"questions": [
{"qid": 标准问题的唯一标识,
"sid": 问题类型的唯一标识,
"question": 知识库中的标准问题(135个),
"words": 问题相关领域词语,
"answer": 知识库中标准问题的标准答案
}]}]
2 系统构成及问题处理
如图2所示,使用领域词典构建阶段产生的问题文本数据集进行模型训练,得到最终识别问句的Sentence-Bert词向量模型。输入用户的问题后,先通过之前构建好的领域词典对其进行冗余过滤,过滤后的问句再放入模型中进行计算返回top1答案。
2.1 句向量训练
对词典构建阶段扩展的问题数据集进行处理,划分为正负样本作为输入,使用HuggingFace提供的Sentence_transformers进行数据处理,即将单个问题转化成Bert可识别的InputExmple,并打上正负样本的标签,再随机打乱,按照8∶1的比例划分训练集和测试集。并且以huggingfac提供的Sentence-BERT中文预训练模型uer/sbert-base-chinese-nli为基础进行训练。
如图2所示,把正负样本喂给预训练的Sentence-BERT模型,然后获得每个标记的向量表示,用两个一样的BERT模型。把句子1喂给第一个BERT模型,把句子2喂给第二个BERT模型,然后计算模型输出的标记表示的均值(池化)。u,v分别表示输入的2个句子的向量表示,|u-v|表示取两个向量的绝对值,(u, v, |u-v|)表示将三个向量在-1维度进行拼接,因此得到向量的维度为 3×d,d表示隐层维度。
令u代表句子1的表示,v代表句子2的表示。然后通过余弦相似计算这两个向量表示的相似度:Similarity=cos(u,v)。
2.2 系统构成
本系统由领域词典、句向量模型、问题处理器三部分组成,如图3所示。领域词典用于过滤冗余词、匹配关键词、提供标准问句与回答;句向量模型用于计算去冗余句子的句向量以及该句向量与标准句子的文本相似度;问题处理器用于接受用户问题并进行文本预处理,调用领域词典去冗余、调用句向量模型计算文本相似度。
2.3 用户问题处理
如图3所示,用户输入问题后,先进行分词,去掉停用词,剩余的每个词再与之前构建的领域词典的每个词进行文本相似性比对,相似结果大于阈值υ才可被认定为是有效词,再将剩余词拼接起来,使用训练好的Sentence-BERT模型将其与标准库中的标准问题进行文本相似计算,同样设置阈值a,返回相似度大于a的top1问题,并对应的答案。具体算法如下:
算法3:QueryDealing
输入:用户问题Query,领域词典短语库W,领域词典问题答案对DicQAs,词语相似度阈值e,句向量相似度阈值a,句向量模型Sbert,停用词表stopwords。
输出:相似度top1的答案A。
1: ql = []
2 :ql <- split(Query)
3 :For i <- ql do
4 : If i in stopwords do
5 : ql.remove(i)
6 :Query <-””
7 :For j in ql do
8 : If W.similarity(j) > e do
9 : Query.append(j)
10:For z <-DicQAa.keys do
11: simList <-(z,Sbert.similarity(z,Q))