基于多模态数据融合的短视频分类研究
作者: 陈小娥 陈德涛
摘要:文章通过对短视频领域真实场景多模态的数据进行分析研究,对短视频中的标题、音频转文本识别结果以及视频OCR识别结果采用多种不同的拼接方式并展开消融实验。同时,对基线模型进行改进,将文本特征和视频特征分别在权重共享的Embedding和非权重共享的Embedding上将合并的文本模态特征和视频模态特征一起传入BERT网络实现Early-Fusion。实验结果表明,改进的算法有效地提升了分类精度。
关键词: 多模态;短视频分类;Early-Fusion;BERT
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2023)25-0106-03
开放科学(资源服务)标识码(OSID) :<G:\飞翔打包文件一\电脑2023年第二十五期打包文件\3.06xs202325\Image\image1.jpeg>
0 引言
近年来,短视频广泛出现在各种社交平台上,其热度呈爆炸式增长。短视频具有时间短、表现形式多样、信息承载量高等特点,用户可以轻松地利用碎片时间进行获取和分享,深受用户欢迎。通过对短视频进行分类,识别用户特征,了解用户兴趣和需求,从而进行定向推荐或营销具有巨大的商业价值。
常见的短视频通常具有文本、语音、视频三种模态的信息,在不同语义分类体系中发挥着相互促进、相互补充的作用,合理利用好多模态的信息进行多角度的理解才能准确地对短视频进行分类。
本文通过对短视频标题、音频转文本识别结果以及视频OCR识别结果进行模态融合。同时,由于考虑到真实场景数据集中模态缺失的问题,考虑采用jieba分词填充空缺进行实验,并对无关信息进行清洗,降低脏数据对模型训练效果的影响。通过对基线模型进行改进,包括在权重共享的Embedding和非权重共享的Embedding上使用Early-Fusion等方式,同时结合文本特征和视频特征进行提升,并进行验证试验来验证改进的有效性。
1 相关研究与工作基础
1.1 语言序列模型
2018年,Devlin等人[1]提出了BERT模型,并在11个自然语言处理任务中获得了显著的提升。BERT模型的目标是利用大规模无标注语料训练获得文本的语义表示,然后再将文本的语义表示在特定NLP任务中作微调,最终应用于该NLP任务。
Devlin提出的BERT模型原文是在英文数据集上训练的,2019年,哈工大讯飞联合研究院采用WWM(Whole Word Masking) 技术针对中文环境进行优化,实现了中文的全词Mask[2],更符合中文语境;并于2020年提出MacBERT[3],使用纠错型掩码MLM as correction(Mac) 的方法对中文数据进行预训练,缓解了预训练与下游任务不一致的问题。
1.2 SE模块
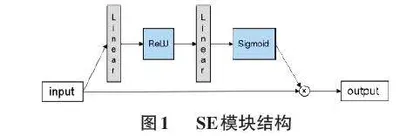
SE模块来自SENet(Squeeze-and-Excitation Networks) [4],SE模块是一个简单的网络子结构,可以方便地插入其他网络增强网络表达能力。文中将SE block加入ResNext中,在ILSVRC 2017获得top-1,SE模块结构如图1所示。
将输入特征使用线性函数压缩成channel /SE_ratio大小的特征,经过ReLU激活函数后再将特征传入用于特征激发的线性层,将特征扩张成channel大小,最后经过Sigmoid函数后与原始输入相乘,得到模块输出结果。
1.3 微观F1分数
精确率指的是被认为正的样本中,实际上有多少是正样本,用于衡量模型正确预测的概率,精确率的公式如下:
[Precision=TPTP+FP]
召回率指的是有多少正样本被找出来,召回率的公式如下:
[Recall=TPTP+FN]
所有类别的精确率和召回率可以表示为:
[Precisionmicro=i=1nTPii=1nTPi+i=1nFPi]
[Recallmicro=i=1nTPii=1nTPi+i=1nFNi]
微观F1分数可以表示为:
[F1micro=2(Precisionmicro×Recallmicro)Precisionmicro+Recallmicro]
微观F1分数考虑了各种类别,适用于数据分布不平衡的情况,类别数量较多对F1的影响会较大。
1.4 宏观F1分数
第i类的精确率和召回率公式可以表示为:
[Precisioni=TPiTPi+FPi]
[Recalli=TPiTPi+FNi]
各个类别的精确度和召回率均值为:
[Precisionmacro=i=1nPrecisionin]
[Recallmacro=i=1nRecallin]
宏观F1分数可以表示为:
[F1macro=2(Precisionmacro×Recallmacro)Precisionmacro+Recallmacro]
宏观F1分数对各类别的Precision和Recall求平均,Precision和Recall较高的类别对F1的影响会较大。
2 基于多模态融合的短视频分类算法
2.1 基线模型
基线模型对两个特征分别做处理,将视频标题传入BERT模块得到文本特征bert_embedding,将视频帧特征传入NextVLAD[5]模块融合视频帧特征,然后将融合的视频帧特征传入SENet模块以增强融合的视频帧特征,得到vision_embedding,将bert_embedding和vision_embedding一起传入ConcatDenseSE模块融合两种模态的特征,最后将融合的特征通过一个线性层作为分类头得到多模态的分类结果,模型结构如图2所示。
2.2 改进的多模态融合网络结构
本文将视频标题、视频帧OCR、语音转文本数据进行拼接,构成文本模态信息,然后对文本模态信息进行Mask,将经过Mask的文本模态信息和视频帧模态信息在BERT Embedding进行Early Fusion,和合并的文本mask和视频mask一起传入BERT网络。由于视频帧特征和文本特征存在空间异质化问题,在视频帧特征和Embedding层之间添加一个线性层来缓解空间异质化问题。将BERT Encoder的最后一个隐藏层参数分别传给MLM Head和Mean Pooling,得到预测结果和MLM损失。模型结构如图3所示。
3 实验结果与分析
3.1 实验数据集
数据集采用2022中国高校计算机大赛的数据集,该数据集采集来自微信视频号的短视频数据,包含了十万量级的标注数据。具体数据格式描述如表1所示。
其中,frames_feature是包含float list类型的视频帧特征,如:[ [0.89, 1.86, -4.67,-4.38 , …], [0.13, 1.11, -2.12, -3.24, …], ],视频帧特征是使用预训练模型每秒抽取一帧提取,每个视频最多提供前32帧的特征,超出的部分直接舍弃。ocr是包含dict list类型的视频OCR识别,如:[{“time”: 0, “text”: “苏炳添创造新纪录荣获小组第一”}, …],该字段为一个列表,记录了不同时刻的OCR识别结果,相邻帧的重复识别已被去除,最多提供前32秒的OCR结果,可能存在空值。
3.2 实验环境及数据集预处理
实验基于PyTorch1.11实现,所有实现均采用CPU:Intel(R) Xeon(R) Gold 5118 CPU @ 2.30GHz(4核)和一块GPU:Tesla V100-32G Specs进行计算加速,在移动云上进行实验。
本文通过对短视频标题、音频转文本识别结果以及视频OCR识别结果进行模态融合,采用了多种拼接和截断方式进行多次实验,取最优的截断方式作为拼接方案。
3.3 评价指标
本文使用F1macro和F1micro作为评价指标,由于涉及两级分类,最终评价指标取一级分类的F1macrol1分数和F1microl1分数以及二级分类的F1macrol2分数和F1microl2分数的平均值[7]。具体公式如下:
F1总=(F1macrol1+F1microl1+F1macrol2+F1microl2)/4
3.4 不同特征截取方案的实验对比
在ernie-1.0[6]预训练权重下,单独对文本部分进行训练,实验结果如表2所示。表2中,title表示短视频标题,asr表示音频转文本识别结果,ocr表示视频OCR识别结果,表2中列出了仅title、title与asr拼接、title与ocr拼接,以及title、asr与ocr拼接四种方式训练后得到的评分结果。
3.5 数据清洗前后的实验对比
原始数据存在一些脏数据,比如无意义文本、装饰性字符等,因此设计了一个删除特殊符号的模块,在传入网络前进行数据清洗。具体实现如下:
pattern = re.compile(r'[^,.,。“”0-9a-zA-Z\u4e00-\u9fa5!-\' \']')
return re.sub(pattern, '', file)
实验结果如表3所示。实验表明,该数据清洗模块对网络评估结果有一定提升。
3.6 改进模型结构的有效性
对基线模型和本文提出改进的模型结构分别采用相同的预训练权重进行实验。实验得到基线模型的评分结果为0.581,改进的模型结构的评分为0.656。实验表明,采用改进的模型结构对评估结果有显著提升。
4 结束语
本文通过在真实场景的大数据集上对改进网络的多个方案进行消融实验,发现在采用ERNIE预训练权重的改进网络上采用MLM和指数平均移动技术并加以对抗训练,通过共享Embedding层的权重并加以参数微调,使得网络评估结果达到最优分数,获得了接近SOTA的效果。
参考文献:
[1] Devlin J,Chang M W,Lee K,et al.BERT:pre-training of deep bidirectional transformers for language understanding[EB/OL]. [2022-08-09].2018:arXiv:1810.04805.https://arxiv.org/abs/1810.04805.
[2] Cui Y M,Che W X,Liu T,et al.Pre-training with whole word masking for Chinese BERT[J].IEEE/ACM Transactions on Audio,Speech,and Language Processing,2021(29):3504-3514.
[3] Cui Y M,Che W X,Liu T,et al.Revisiting pre-trained models for Chinese natural language processing[EB/OL].[2022-08-10]. 2020:arXiv:2004.13922.https://arxiv.org/abs/2004.13922
[4] Hu J,Shen L,Albanie S,et al.Squeeze-and-excitation networks[EB/OL]. [2022-08-27].2017:arXiv:1709.01507.https://arxiv.org/abs/1709.01507.
[5] Lin R C,Xiao J,Fan J P.NeXtVLAD:an efficient neural network to aggregate frame-level features for large-scale video classification[EB/OL]. [2022-08-09].2018:arXiv:1811.05014.https://arxiv.org/abs/1811.05014.
[6] Sun Y,Wang S H,Li Y K,et al.ERNIE:enhanced representation through knowledge integration[EB/OL]. [2022-08-27].2019:arXiv:1904.09223.https://arxiv.org/abs/1904.09223.
[7] 曾祥玖,刘达维,刘逸凡,等.融合多模态特征的新闻短视频分类模型[J].计算机工程与应用,2023,59(14):107-113.
【通联编辑:唐一东】