基于联邦学习的无监督跨域车辆重识别方法
作者: 刘世豪
摘要:在车辆重识别的实际应用场景中,车辆图像通常来自不同区域的摄像头,路侧边缘计算单元的计算能力有限,无法实时完成模型训练。如果直接部署统一的模型,由于地域差异,同一种网络无法适应所有地域的图像风格,从而影响车辆重识别的准确性。针对以上问题,文章深入分析了车辆重识别算法的特点,提出了基于联邦学习的无监督领域自适应车辆重识别方法。
关键词:深度学习;车辆重识别;跨域车辆识别
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2023)26-0007-04
开放科学(资源服务)标识码(OSID)
0 引言
车辆重识别是智能交通系统的前沿研究课题,旨在识别在多个非重叠跨域摄像头拍摄的车辆图像中的同一辆车。尽管车辆重识别已取得了一些进展,但在实际应用中仍存在以下局限性:
传统车辆重识别算法采用有监督的训练方式,但标注成本高,需寻求高效的无监督方式;不同域的偏差会导致源域模型在目标域的测试准确率下降,无法直接应用于新的未知域;不同区域的图像来自不同摄像头,路侧计算能力有限,无法实时更新模型。
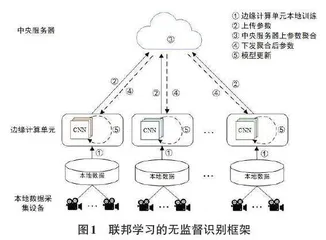
本文提出了一种基于联邦学习框架[1]的无监督领域自适应车辆重识别方法。该方法通过有监督预训练源域数据和无监督训练目标域数据来解决以上问题,并可以动态聚合多个预训练模型以实现相互适应。使用联邦学习结构,在边缘计算单元中部署不同结构的骨干网进行局部训练。在服务器中,多个模型通过协同学习进行聚合并相互适应,以获得最优参数。
1 车辆重识别模型
1.1 联邦学习框架
本文使用联邦学习技术进行车辆重识别。在深度学习模型训练阶段,采用了源域到目标域的模型集成方法,该方法包含了源域监督学习和目标域无监督适应。
如图1所示,本方法采用三层结构。最高层结构是中央服务器,具有高性能计算和数据共享能力,能够执行全局缓存和聚合计算任务。中间层有多个边缘计算单元,每个采用不同的CNN网络结构,负责训练重识别模型参数并上传中央服务器。底层是若干监控摄像头,每个区域的摄像头归属于该区域的边缘计算单元,将采集到的车辆图像原始数据上传到边缘计算单元中。
1.2 边缘计算模型
在模型中,边缘计算单元会接收到本地数据采集设备采集的图像数据,并使用这些数据进行模型训练。实验阶段,本文使用带有标签的源域数据的模型预训练和不带标签的目标域数据的模型训练相结合的方式对本地模型进行无监督领域自适应的模型训练。
本文将源域数据记为SD:
[SD=xSi,ySiNSi=1]
该源域数据有[NS]个数据样本,每一个数据样本上都有对应标签,其中[xSi]和[ySi]表示图像样本和车辆样本,每个图像样本和每个图像中的车辆样本相关联。将目标域数据记为[TD=xtiNti=1],在该样本集中,含有[Nt]个图像样本,每个样本[xti]中没有原始数据的标签。本文利用源域数据中的标记样本和目标域中未标记的样本来得到跨域模型,实现车辆跨域无监督重识别。
1) 源域监督学习:利用边缘计算单元中对应的源数据集训练不同结构的模型,然后将训练得到的网络模型转移到无监督的目标域。边缘计算单元使用融合SE注意力[2]模块的Resnet-50、DenseNet和Inception-v2模型。通过控制尺度,保留可用性较高的特征,控制和减弱图像的背景特征。[θk]表示融合注意力机制的网络模型[Mk]在有标记的数据上训练后的参数,预先训练好的网络可以捕获训练数据的分布及其聚类的预测。网络模型[Mk]将输入的图像样本[xsi]转换为特征表示[fxSi∣θk],并输出图像中的车辆样本的预测概率[pjxsi∣θk]。边缘计算单元的CNN网络主要采用交叉熵损失函数和三元组损失函数来进行网络的优化[3]。
本文将带有标签平滑效果的交叉熵损失函数定义为:
[LSidθk=1NSi=1NS j=1MS qjlog pjxSi∣θk] ,
[qj=1-σ+σMs]
当[j=ysi]时:[qj=σMs]
[Ms]是源域车辆标识的数量,本文将设置为0.1。交叉熵损失表示图像的网络输出的预测值和实际真实样本标签之间的差异。
考虑到传统形式的三重损失函数无法支持多网络的软标签训练,本文中采用soft-max的三重损失。损失函数定义为:
[LStriθk=-1Nsi=1NS log PSiθk] ,
[Psiθk=efx5ik-fx5i-kefxSiθk-fxSi+θk+efxSiθk-fxSi-pk]
式中,[Psi](⋅)表示源域中负样本对之间的最大距离,[xSi+]表示正样本,[xSi-]表示负样本。本文用带有标签平滑效果的交叉熵损失函数和softmax的三元组损失相结合的方式以提高网络预测的准确性。损失函数定义为:
[LSθk=LSidθk+LStriθk]
2) 目标域无监督学习:由于目标域上的图像没有进行人工标注,所以目标域无监督的学习过程由一个基于聚类的伪标签生成过程和一个特征学习过程组成,如图2所示。训练共三个步骤:目标域图像的特征提取;将提取的特征进行聚类分簇;将聚类生成的簇用作伪标签对模型进行训练。
①目标域图像的特征提取:使用上一步有监督训练得到的预训练模型网络对目标域数据进行特征提取,每个目标域样本图像[xti]的卷积特征[fxti∣θk],将得到的特征向量进行重排序之后进行聚类。
②特征进行聚类分簇:在聚类阶段使用k-means的聚类方法。
③模型训练:将聚类生成的簇用作伪标签对模型进行训练。
为了在聚类的过程中获得稳定的伪标签,本文引入身份损失函数和三重损失函数组成的决策损失函数。身份损失定义为具有标签平滑的交叉熵损失,这里的三元组损失函数与监督学习中的保持一致。整体聚类决策损失函数可以表示为:
[Ltvot θk=Ltidθk+Lttriθk]
针对不同模型间的独立性,本文在每个计算单元向中央服务器提交参数的过程中引入时间平均模型。中央服务器使用经过时间平均的模型参数来对其他网络进行监督训练,减小因实验参数不稳定对整个模型训练的影响。通过时间平均模型得到的参数定义为:
[ΘkT=λΘkT-1+(1-λ)θk]
[ΘkT-1]是模型[Mk]前([T-1])次的时间平均模型参数,在初始阶段[Θk0=θk],为尺度因子,取值范围为[0,1)。利用该网络该模型的时间平均模型得到的样本图像的特征表示[fxti∣ΘeT]和分类置信度的预测为[pjxti∣ΘeT]。
1.3 模型聚合
图3展示了本文提出的基于联邦学习的多网络协同学习模型。边缘计算单元中部署的网络使用硬伪标签进行监督模型训练,从而能够捕获训练数据的分布。使用中央服务器下发的硬伪标签和本地模型聚类产生的在线软伪标签共同训练协作网络。通过使用在线硬伪标签训练边缘计算单元上的网络,可以迭代改进学习的特征表示,提供更准确的软伪标签,并进一步提高学习特征的鉴别性。
对于每个边缘计算单元网络模型,本文将其他模型的时间平均模型和当前网络一次的分类预测模型之间的交叉熵损失定义为相互身份损失,某一个模型的相互身份损失设置为所有的其他模型在学习该模型时损失的平均值。将其表示为:
[Ltmid θk∣θe=1Nti=1Nt j=1Mt pjxti∣ΘeTlog pjxsi∣θk]
整个模型的相互身份损失可以定义为所有模型[Mk]相互身份损失的平均值:
[Ltmid θk=1m-1e≠km Ltmid θk∣θe]
另外,在对不同边缘计算单元上传的网络模型预测进行聚合时,考虑到由于网络结构的差异,可能造成聚合不收敛。针对聚合过程中的相互三元组损失,本文将其他模型在学习某一模型之间的相互三元损失定义为:
[Ltstriθk∣θe=1Nti=1Nt LbcePtiθk,Ptiθk]
上式中的[Pti](⋅)表示负样本对之间的softmax距离,[Lbce()]表示二进制交叉熵函数。整个模型的相互三重损失也可以定义为所有softmax三重损失的平均值,可以计算为:
[Ltmtriθk=1m-1e≠km Ltstriθk∣θe]
综上所述,对于中央服务器中训练网络的损失函数为:
[Ltone θk=Ltmid θk+Ltmtri θk+Ltvot θk]
为了适应不同网络模型的异质性,本文引入了一种权重正则化模块。它根据每个边缘计算单元网络模型的集群间和集群内分散度来调制不同模型的权重值。网络模型在提取图像特征后,用聚类算法将所有样本分组为[Mt],聚类为。每个模型的权重可定义为聚类间散点和聚类内散点之和的比值,以此得到每个网络模型的权值。在协同学习的过程中,该权值表示中央服务器对各边缘计算单元提交的模型参数进行融合时的置信度。簇[Ci]的簇内散度可以计算为:
[Siintra=x∈Ci fx∣ΘT-μi2] ,[μi=x∈Ci fx∣ΘT/nit]
[μi]是簇[Ci]的平均特征,[nit]表示[Ci]中的特征个数,簇间散度的定义为:
[Sinter=i=1Mt nitμi-μ2] ,[μ=i=1Nt fxt,i∣ΘT/Nt]
[μ]表示所有训练目标域样本的平均特征。簇间散度与簇内散度之和的比率R可以定义为:
[R=Sinteri=1Mt Siintra]
如果一个模型具有较好的识别能力,则当簇间散度较大或簇内散度越小时,R的标量就会越大。
对于主服务器中的动态聚合,在每个迭代的特征学习之前,每一个模型[Mk]的权重[wk]可以定义为R的均值归一化。所以对上述互相关身份损失和互相关三重损失可以重新定义为:
[Ltmidθk=1m-1e≠km wkLtmidθk∣θe]
[Ltmtriθk=1m-1e≠km wkLtmtriθk∣θe]
通过权重正则化方案,中央服务器中调节了每个边缘计算单元的权重,以促进在目标领域的识别。在训练过程,将硬伪标签和软标签与提出的软损失相结合,对多个边缘计算单元进行训练。
1.4 实验参数
本文采用DenseNet-121、ResNet-50和Inception-v3作为三个分支。使用骨干网络与SE注意力机制融合来提取图像特征。对于训练集的每个标识,用随机选择的车辆和随机采样的图像进行采样,用于计算批处理三联体损失。使用权重衰减为0.000 5的Adam衰减函数。设置初始学习率为0.000 35,在总共80个epoch的训练中,在第40个epoch和第70个epoch达到之前值的1/10。
在目标域训练的过程中,共有100个训练迭代过程,学习率设置为0.000 35。在每一次训练迭代过程中都进行一次500个集群的聚类,一次训练迭代过程由800个训练迭代组成。
1.5 实验结果
将本文提出的算法与现有具体有代表性的无监督领域自适应的车辆重识别算法进行比较[4]。对比算法如下:
①FACT:该算法使用车辆的显著特征和卷积神经网络提取的GoogleNet深度特征进行融合作为伪标签进行无标签目标域的车辆重识别[5]。