一种结合PSO优化调参的SVM数据分类和预测研究
作者: 肖明魁
摘要:支持向量机(SVM) 和粒子群优化(PSO) 是两种常用的机器学习和优化算法,它们各自在数据分类和预测中有广泛的应用。研究提出了一种基于SVM和PSO相结合的新型算法,用于数据分类和预测。该算法首先使用SVM对数据进行初步分类,然后使用PSO对SVM的参数进行优化,以提高分类和预测的准确性。对比实验结果,表明该算法在相同数据集上的分类和预测性能均优于传统的SVM算法。因此,该算法在实际应用中具有很大的潜力,并可以为数据分类和预测提供更好的解决方案。
关键词:支持向量机;粒子群优化;机器学习;数据分类和预测
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2023)26-0032-04
开放科学(资源服务)标识码(OSID)
0 引言
随着大数据时代的到来,数据分类和预测已经成为众多领域中不可或缺的重要任务,例如金融风险评估、医疗诊断、图像识别等。因此,如何高效、准确地进行数据分类和预测成为当前机器学习和数据分析领域中的研究热点。支持向量机(SVM) 是一种常用的机器学习算法,具有良好的分类和预测性能,但是其性能很大程度上取决于选取的核函数和参数。粒子群优化(PSO) 是一种优化算法,能够在搜索空间中找到最优解[1]。然而,SVM和PSO各自在算法的时间复杂度、搜索空间的局限性等方面都存在一定的问题,因此本文提出了一种基于SVM和PSO相结合的新型算法,旨在充分发挥两种算法的优点,同时避免它们各自存在的问题,以提高数据分类和预测的准确性和效率。
1 SVM和PSO概述
1.1 SVM和PSO简介
支持向量机(SVM) 是一种常用的机器学习算法,可以用于数据分类和预测。SVM通过找到一个最优超平面,将不同类别的数据分开,从而实现分类[2]。SVM具有良好的泛化能力和鲁棒性,被广泛应用于不同领域的数据分类和预测任务中。
粒子群优化(PSO) 是一种基于群体智能的优化算法,可以用于求解复杂的优化问题。PSO通过模拟鸟群觅食的过程,通过不断更新每个粒子的速度和位置,来搜索最优解。PSO具有全局搜索能力、易于实现和收敛速度快等优点,在数据分类和预测中也有着广泛的应用[3]。对于一组粒子,每个粒子的位置表示为 xi=(xi1 ,xi2 ,...,xid),速度表示为 vi=(vi1 ,vi2 ,...,vid),其中 i=1,2,...,N,d 表示问题的维度,N 表示粒子的数量。假设当前全局最优解为 v=(v1,v2,...,vd),则粒子i的更新公式为:
[vi=ϖ×vi+c1×rand()×(pbesti-xi)+c2×rand()×(gbesti-xi)] (1)
其中,ω是惯性权重因子,c1 和 c2 分别是学习因子,rand()是随机数,pbesti 是粒子 i 的个体最优位置,表示粒子i在搜索过程中找到的最优位置,gbesti是粒子群整体最优位置,表示粒子群历史最佳位置向量[4]。通过不断的迭代更新粒子的位置和速度,使得每个粒子不断向着局部最优解和全局最优解靠近,最终达到问题的最优解。
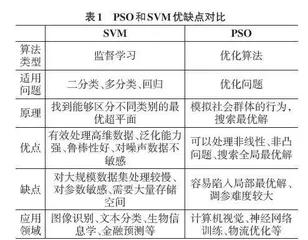
1.2 相关算法的优缺点分析
SVM和PSO在不同领域发挥不同作用,两种算法的优缺点如表1所示[5]。
2 SVM和PSO相结合的算法设计
SVM通常用于分类和回归问题,而PSO用于解决优化问题,将它们结合起来可以得到一种强大的算法,可以在分类和回归问题中得到更好的性能[6]。具体来说,SVM和PSO的结合可以通过以下步骤实现:
首先,定义SVM的目标函数,包括SVM的惩罚参数C、核函数类型和参数等。通常,SVM的目标函数是一个凸函数,可以使用凸优化算法求解。
接着,将PSO算法应用于SVM的优化问题中。在PSO算法中,将SVM的目标函数作为适应度函数,将惩罚参数C、核函数类型和参数作为搜索空间中的变量。
根据PSO算法的原理,初始化一组随机粒子,并迭代更新每个粒子的速度和位置。更新后的位置和速度将用于计算适应度函数,并根据适应度函数的值来更新每个粒子的最优位置和全局最优位置。
重复迭代更新直到达到预定的停止条件,例如达到最大迭代次数或收敛到一个阈值。
最后,将找到的最优解应用于SVM模型中,得到用于分类或回归的模型。
需要注意的是,将SVM和PSO相结合的算法设计并不唯一,具体的实现方式可能因应用场景和问题而异。因此,算法的性能和效果也需要通过实验验证和调优来确定[7]。
3 实验设计与结果分析
通过SVM和PSO相结合进行分类和优化问题的求解,SVM是一种传统的分类算法,PSO是一种全局优化算法。二者结合可以得到更好的性能。
3.1 实验设计和数据集介绍
本实验的设计思路是结合支持向量机和粒子群优化算法来提高SVM的分类性能。具体地,利用PSO算法来优化SVM的超参数,以求得更优的分类器[8]。在PSO算法中,将SVM的参数C和gamma作为粒子的位置,通过不断迭代更新粒子的位置,找到使分类器性能最优的超参数组合。
本实验采用的是UCI机器学习库中的Wine Quality数据集,该数据集包含了红酒的化学特征以及对应的品质评分。
3.1.1 算法框架
SVM和PSO结合的数据分类和预测算法的主要思想是,将SVM和PSO两种机器学习算法结合起来,利用PSO算法对SVM模型进行超参数优化,从而提高SVM模型的分类准确率,并提高预测精度[9]。
算法框架如下:
1) 输入:训练样本集、测试样本集、超参数。
2) 使用原始SVM分类器进行分类,并对测试结果进行评估,包括准确率、精确率、召回率和F1得分。
3) 使用网格搜索SVM分类器进行分类,并对测试结果进行评估,包括准确率、精确率、召回率和F1得分。
4) 使用PSO算法优化SVM分类器的超参数,并对测试结果进行评估,包括准确率、精确率、召回率和F1得分。
5) 输出所有分类器的测试结果。
6) 将所有分类器的测试结果存储到一个表格中。
流程图如图1所示:
3.1.2 算法实现
本文结合Wine数据集和Python语言,编写程序实现SVM和PSO结合的数据分类和预测算法。
首先导入了需要用到的模块,包括 pandas 用于数据处理, numpy 用于数值计算, random 用于生成随机数,以及 sklearn 中的模块用于数据集加载、模型训练、性能评估等。使用 datasets.load_wine() 方法加载红酒数据集,将数据集赋值给wine变量,数据集中的特征矩阵和标签分别赋值给 X和y变量。代码如下:
import pandas as pd
from sklearn.datasets import load_wine
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import train_test_split
from sklearn import svm
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, classification_report
import numpy as np
import pyswarms as ps
# 读取数据集
wine = load_wine()
X, y = wine.data, wine.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
然后,使用原始的SVM分类器对数据进行分类,并计算准确度、精确度、召回率和F1得分等指标。接着,使用网格搜索算法对SVM分类器的参数进行优化,并计算模型的评价指标[10]。最后,使用粒子群优化算法对SVM分类器的参数进行优化,并计算模型的评价指标。代码如下:
# 原始SVM分类
svm_clf = svm.SVC(kernel='linear', C=1, random_state=0)
svm_clf.fit(X_train, y_train)
svm_pred = svm_clf.predict(X_test)
svm_accuracy = accuracy_score(y_test, svm_pred)
svm_precision = precision_score(y_test, svm_pred, average='weighted')
svm_recall = recall_score(y_test, svm_pred, average='weighted')
svm_f1 = f1_score(y_test, svm_pred, average='weighted')
# 网格分类
parameters = {'kernel':('linear', 'rbf'), 'C':[1, 10]}
svc = svm.SVC()
grid_clf = GridSearchCV(svc, parameters)
grid_clf.fit(X_train, y_train)
grid_pred = grid_clf.predict(X_test)
grid_accuracy = accuracy_score(y_test, grid_pred)
grid_precision = precision_score(y_test, grid_pred, average='weighted')
grid_recall = recall_score(y_test, grid_pred, average='weighted')
grid_f1 = f1_score(y_test, grid_pred, average='weighted')
使用粒子群优化算法对SVM分类器的参数进行优化,并计算模型的评价指标。具体来说,使用了 PySwarms 库实现了一个全局最优 PSO,来寻找 SVM 模型的最佳超参数[11]。优化目标是最小化错误率,即最大化分类准确性。
首先,定义了一个 optimize_svm 函数,它接受 SVM 模型的超参数(C和gamma) ,训练 SVM 模型并对测试数据进行预测,最后返回分类性能度量指标(准确性、精度、召回率和 F1 得分)。在这个函数中,使用了Scikit-learn库中的accuracy_score、precision_score、recall_score 和 f1_score 函数来计算分类性能度量指标。