一种融合文本主题特征的情感分析画像模型
作者: 何西远 张岳 张秉文
摘要:了解游客的需求和口碑在旅游行业中非常重要。然而,一般情况下,游客的需求和口碑分布在各种途径中。要收集和分析这些信息,需要耗费大量的人力和时间成本,而效率也难以保证。为此,该文章通过对游记评论的情感分析,提取文本主题特征,依靠“旅游四要素”的方法,分别构建用户画像和景区画像,分析用户在景点类型和旅行方式上的偏好,挖掘景区的特色与优势,建立两者的耦合关系。为景区和用户提供精准决策支持和个性化推荐服务。
关键词:用户画像;景区画像;情感分析;文本主题特征
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2023)26-0105-03
开放科学(资源服务)标识码(OSID)
0 引言
随着旅游业的发展和人们生活水平的提高,人们越来越注重旅游质量和体验。同时,网络技术、移动设备和社交媒体的普及,使得游记评论成为游客选择旅游目的地和产品的重要依据[1]。在当前的背景下,用户画像被广泛应用于电商、社交媒体、金融、旅游等领域[2-5]。在旅游领域,基于用户画像和景区画像的构建和分析可以帮助旅游从业者精准地把握游客需求,提供个性化旅游服务,同时对旅游市场的分析和预测也具有重要意义。
目前,在相关文献中,学者们通过对游记评论数据的分析挖掘,成功地构建了用户画像和景区画像,并应用于实际的旅游推荐系统中。例如,燕山大学的刘海鸥等人提出了基于用户画像的旅游情境化推荐模型,通过对游客的基本信息、用户旅游情境和行为数据进行建模,成功地将用户画像运用于旅游推荐系统中,并进行了实验测试[6]。另外,单晓红等人以在线酒店评论为基础,结合用户信息属性、酒店信息属性和用户评价信息属性,成功构建了酒店用户画像。可以为酒店提供决策依据,帮助酒店更好地了解用户需求并进行精准营销[7]。
本文旨在利用数据挖掘和自然语言处理技术来分析游记评论,构建旅游领域的用户画像和景区画像。本文将从游客和景区经营者的角度出发,运用机器学习算法和大数据分析手段分析游记评论中的主题、情感倾向、用户特征和景区特征,以便更好地了解旅游者的喜好、需求和行为模式,挖掘景区的核心优势和服务瓶颈,构建用户画像和景区画像,为旅游从业者提供有用的信息和洞见,进一步促进旅游行业的创新和发展。
1 主要工作及创新
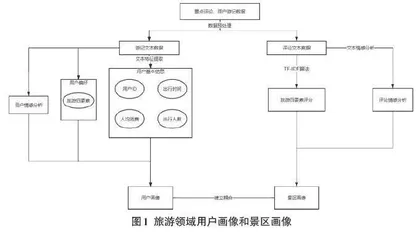
基于上述研究背景,该研究首先分析了旅游领域中游记评论的特征,设计了基于自然语言处理和机器学习的游记评论文本分析方法,实现了游记评论文本的预处理、情感分析、文本聚类等操作,构建了旅游领域用户画像和景区画像,并根据研究结论设计了相应的旅游景区画像评价指标体系。具体的画像构建过程如图1所示。
该研究主要创新包括以下几个方面:
1) 在游记评论文本预处理中,针对游记评论文本的特点和主题,设计了一种基于朴素贝叶斯模型的情感分析方法。该方法利用游记评论文本中的每个单词作为一个特征,对分词文本进行建模,并为样本预设类别。朴素贝叶斯算法通过样本的先验概率计算样本的后验概率,并选择具有最大后验概率值的类别作为样本的最终归属分类类型。
2) 在游记评论文本情感分析中,基于朴素贝叶斯模型的情感分析方法采用了改进的TF-IDF(Transformer Filtered Document Frequency) 算法和SMOTE(Synthetic Minority Over-Sampling Technique) 技术,以更好地进行建模和情感分析。经过实验验证,改进后的算法显示出更好的效果。
3) 针对旅游游记评论数据规模大的特点,采用了分布式数据库MongoDB进行数据存储。MongoDB是非关系型数据库中功能最丰富、最像关系型数据库的一种。使用MongoDB存储旅游评论和游记数据,方便数据的存储、管理、查询和分析,并能够适应不断增长的数据量,是适合大数据存储的解决方案。
2 模型
2.1 文本情感分析模型
文本情感分析技术在目前被广泛应用。该技术有助于旅游企业更好地了解用户的需求和偏好,进而提供更加贴心和个性化的旅游服务。此外,通过文本情感分析,旅游企业可以了解用户在旅游过程中遇到的问题和不满意的地方;这些数据可以帮助企业改善和优化相应服务,提高服务质量,进而增强用户的满意度。本文通过对景区评论和用户游记进行文本情感分析来评估景点的受欢迎程度和了解游客的个人偏好。通过分析景区评论,可以推断出游客对该景点的情感倾向。通过对用户游记进行情感分析,可以更好地了解游客对于出行的态度、偏好以及行为习惯等方面的信息。
本文采用朴素贝叶斯模型进行情感分析。朴素贝叶斯分类的首要步骤是对用户评论数据进行训练,获取单词、短语或其他文本属性的特征及其对应的分类。在情感分类中,将情感视为分类标签,单词或短语作为特征。若有m条文本数据,n个特征,k个情感类别,则使用公式(1) 计算某个文本属于某种情感的概率:
[P(c|x)=P(x|c)P(c)P(x)] (1)
其中,c表示情感类别,x表示文本数据,P(c|x)表示在给定x的情况下,c的后验概率,P(x|c)表示在c的情况下,x的概率,P(c)表示c的先验概率,P(x)表示x在每个情感类别下的概率。在朴素贝叶斯分类器中,通常假设每个特征都是相互独立的(即朴素条件),这个假设使得可以用以下公式计算P(x|c):
[P(x|c)=P(w1|c)×P(w2|c)×...×P(wn|c)] (2)
其中,w表示一个特征属性(单词或短语)。在训练过程中,计算出每个特征在每个分类下的出现概率。在分类时,将待分类的文本中每个特征的概率分别与其在各个分类下的概率相乘,即为该文本属于该分类的后验概率。最终将前述每个特征的后验概率相加,即为该文本属于该分类的概率。结果越靠近1表示情感越正面,越靠近0表示情感越负面。而且设置了阈值,概率大于0.5为积极评论,小于0.5为消极评论。
2.2 文本主题提取模型
本文将景色、住宿、交通和美食作为旅游四要素。本文利用 TF-IDF算法,对景点评论和用户游记的单个词语进行权值计算,并进行旅游四大要素的分类,求出均值,进而得到该景点评论的旅游四要素得分和用户游记的旅游四要素得分。该算法具体的实现公式如下:
在一篇文档 j 中,词语 i的 TF-IDF 值为:
[TF-IDF(i,j)=TF(i,j)×IDF(i)] (3)
其中,TF(i, j)表示词语 i 在文档 j 中的词频,IDF(i)表示词语 i 在所有文档中的逆文档频率,计算公式如下:
[IDF(i)=logNni] (4)
其中,N表示所有文档的总数,ni 表示词语 i 在所有文档中出现的文档数。
综合起来,词语i在所有文档的权重为:
[W(i)=j=1nTF-IDF(i,j)] (5)
通过计算TF-IDF值,可以得到每个词语在文本中的权重值。该权重值可以用来计算景区和用户的旅游四要素的评分。
2.3 整体框架模型
本文利用文本挖掘技术,构建用户画像和景区画像,进而为景点提供更全面和准确的评估和决策支持。整合用户画像和景区画像,可以为景区提供更加精准的推荐服务,也可以为景区经营决策提供更加全面的市场分析和洞察。本文的方法流程包括以下几步:首先,从多个旅游网站上收集游记和评论数据,并进行预处理,包括分词、词性标注、去除停用词等;其次,基于游记评论数据,构建用户画像,提取用户消费水平、出游时间、偏好等信息,最终得出用户在旅游四要素方面的情感占比;然后,对旅游景区的评论数据进行挖掘,提取出景区的关键特征和用户情感倾向,并构建景区画像,得出景区在旅游四要素方面的评分;最终,利用用户画像和景区画像,对用户的偏好进行分析和挖掘,以推荐更符合用户需求的旅游产品和景区。
3 旅游领域用户画像与景点画像
3.1 画像构建
本文利用文本挖掘技术构建用户画像和景区画像。其中,用户画像包括用户基本信息、情感感知和偏好三个维度。通过用户画像,可以直观了解用户的喜好和行为习惯。景区画像包括景区偏好、情感感知和基本信息三个维度。通过景区画像,可以了解景区的特色和优势。
3.1.1 爬取数据
景区评论和用户游记主要是通过Python爬虫在携程、马蜂窝等旅游平台上进行采集。通过Python的Scrapy库和的Selenium库可以获取到海量的数据。获取的景区信息主要包括景点的名称、景区评分、景区简介、景区评论、评论时间和评论评分;获取的用户信息主要包括用户ID、游记内容和用户基本信息。通过景区的特定标签和用户信息可作进一步的分析。
3.1.2 文本预处理
文本预处理主要包括构建标签值和处理文本特征两个部分。预处理的目的是清理无用信息,减少噪声干扰,提高分析的准确度,为后续建模作准备。
1) 构建标签值
针对景区评论数据,本文对评论的评分进行了划分。由于景区评分范围为1~5分,本文将3分以上的评分设为积极评论,将3分以下的评分设为消极评论。将已标注的数据作为训练语料模型的语料,通过把情感评分转化为标签值为1的概率值,成功将情感分析问题转换为文本分类问题。
2) 文本特征处理
针对景区评论数据和用户游记数据,对文本进行分词、去除停用词,提取特征,并划分训练集和测试集。在此过程中,使用停用词表去除无用数据,使用jieba库进行分词,将文本数据划分为单独的词语。接着,使用TF-IDF技术实现文本转向量,以便后续模型的运用。
3.1.3 情感分析
情感分析采用朴素贝叶斯算法。特征值为评论文本经过TF-IDF处理后的向量,标签值分为好评和差评两类,其中好评标签为1,差评标签为0。情感评分为分类器预测出1类标签的概率值。 另外,为了防止样本不均衡对模型的影响。本文采用过采样(SMOTE)进行数据增强,进而提高分类算法的精度和鲁棒性。具体的算法流程如图3所示。
3.1.4 主题提取
本文通过建立景色、住宿、交通和美食四要素的情感词典。通过TF-IDF算法预处理后的数据来完善词典。然后,将文本数据进行分词后,根据情感词典进行匹配。根据标注的情感极性和权重计算景区和用户在四要素方面的情感得分。
3.1.5 数据存储
使用MongoDB数据库存储景区评论和用户游记,方便数据的访问和管理。MongoDB提供强大的查询和分析功能,可以针对不同需求进行复杂的数据查询和分析,得出准确的结论和决策。此外,MongoDB具备良好的数据安全性和完整性,采用备份、恢复和数据加密等技术,保护存储的数据。
3.1.6 可视化
本系统采用了Django作为主要框架,该框架具备简洁、实用和免费开源的特点。此外,本系统还使用了Wordcloud绘制词云图,并使用Pyecharts生成动态交互式图表。
3.2 画像耦合
作为旅游行为的载体,景点具有重要的旅游价值和意义。景点信息与用户行为、情感之间存在着密切的耦合关系。用户画像反映了用户在景点类型和旅行方式上的偏好;景区画像反映了景区的特色与优势。本文利用画像之间的耦合关系,实现了旅游景点的个性化推荐,并提供了改善提升景区质量的建议。
1) 个性化推荐
在旅游推荐中, 用户标签和景点标签相关[8]。根据用户在景色、住宿、交通和美食旅游四要素上的情感占比得出用户标签,由景区在旅游四要素的情感评分得出景点标签。然后,用户标签和景区标签进行匹配,为用户推荐合适的景点。