安徽省历史文化名镇名村知识图谱的构建
作者: 汪俊逸 史东辉 胡涛
摘要:自2005年以来,历史文化名镇名村正以每年两百多的数量不断流失。目前,对历史文化名镇名村的研究主要聚集在村落空间形态和地理学领域,而对名镇名村数字化发展等领域的研究较为匮乏。本研究提出把知识图谱技术应用于安徽省历史文化名镇名村领域,这将解决名镇名村的相关知识关联度低、查询效率低等问题;同时,提出将基于对抗训练的Bert-BiLSTM-CRF作为命名实体识别模型,对安徽省历史文化名镇名村相关知识的非结构化文本进行实体识别,并将抽取的实体对与关系词典进行匹配,得到对应的关系。将抽取、匹配得到的三元组与Py2neo和Cypher语句相结合,实现安徽省历史文化名镇名村知识图谱的自动化构建。
关键词:安徽省历史文化名镇名村;知识图谱;知识抽取;实体识别;自动构建
中图分类号:TP391 文献标识码:A文章编号:1009-3044(2023)28-0005-05
0 引言
历史文化名镇名村是我国文化传承中不可或缺的一部分,它真实地记录了传统的建筑风貌以及民俗民风,这些古村镇承载了我国不同时期的文化与风俗习惯。社会经济飞速发展带来的城市化进程,加速导致了我国古村落的数量锐减。
目前,国内外对于古村落的研究多聚集在空间形态以及对地理学的研究。张泉,邹成东[1]等人借助网格维数推算对我国名镇名村的空间格局进行了特征分析,并基于这些空间特征提出了优化策略以助力名镇名村的保护措施。高旭宏[2]以及Xie[3]等人通过GIS 技术对历史文化名镇名村进行空间特征分析,以此获取地势对村镇的作用。陆林、葛敬炳[4]对徽州地区文化古城镇的地理环境进行分析最终得出地形的特征能够有效延续古村落的文化传承。Chen, Wei[5]采用景观多功能研究方法对村庄改造相关因素进行了探究,结果表明生态、生活之间存在长期和同步相互作用。Gao,Wu[6]在研究传统村落保护问题中提到旅游业的发展是乡村振兴的关键点,而旅游也可以极大地解决名镇名村风俗文化的传承问题。本文在结合前人对古村镇研究的基础上,考虑如何将数字化技术融入名镇名村的保护工作,并将计算机技术与名镇名村相结合,由此促进文化名镇名村的旅游业发展以助力历史文化名镇名村的文化传承及保护事业。
近年来,知识图谱技术越来越频繁地被应用于各个领域,其中陈海玉[7]、刘爽[8]、Pandolfo[9]等人以及周亦[10]等人将知识图谱应用于历史文献领域。张云中[11]将知识图谱技术应用于历史人物游学足迹上,由此实现游学足迹可视化。Zhou[12]等人将知识图谱技术应用于药学领域,以助力药物管理。考虑到名镇名村相关资料的离散程度较高,且知识图谱技术在名镇名村领域的研究尚有欠缺。本文提出将知识图谱应用于名镇名村领域,以此解决名镇名村资料的关联程度低以及查询效率低等问题。
1 数据预处理
1.1 数据来源及获取
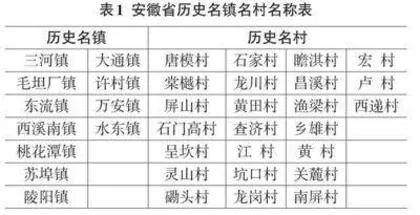
历史文化名镇名村完整地反映着历史时期传统风貌和地方民族特色。本文获取的数据以中国传统文化博物馆、安徽省历史文化名镇名村百科对名镇名村的介绍为主。经过对近20年的中国历史文化名镇名村名单的筛选,最终确定安徽省存在历史文化名镇名村数量为35个。其中共有历史文化名镇11个、历史文化名村24个,如表1所示。
本文所使用的原始数据集是通过爬虫技术,从百度百科及历史文化馆等名镇名村科普网页爬取的非结构化文本。在数据采集的过程中,通过使用urllib 包中的request库函数对网页中HTML格式的文本进行爬取;爬取数据完成后,使用lxml 包中的etree.HTML对获取的HTML数据进行解析,并使用xpath函数通过标签id属性值匹配到原始数据集所需要的文本所在的标签,从而获取本文数据集所需数据。为贴合本研究构建历史名镇名村的知识图谱用于助力古村落数字化发展以及促进其旅游业发展的初衷,本文构建知识图谱所使用的信息主要涉及历史文化名镇名村的地址、气候、景点、古建筑、特色美食以及特色产品等方面。
1.2 数据标注
本文标注所使用的文本数据集是通过爬虫等技术自动获取,并经过人工筛选得到的非结构化文本。为了保证训练数据的标签与实体映射之间的准确性,本文采用人工标注和运用jieba库的分词技术对文本进行分词并结合词典匹配的自动化标注技术对非结构化文本数据集进行高效率、高精度的命名实体BIO 标注工作,其中,实体的头部标注为B-XXX,实体剩余部分标注为I-XXX,非实体部分标注为O。
本文通过BIO标注了41万文字的非结构文本,其中存在实体类型17个,关系类型14个。该数据集共包含6 620句非结构化文本,17个类别共计5 631个标签实体,由图1中的标签统计分析得知,本文所使用的数据集标签分布较为均匀,不会由于某一样本数量过小而导致该标签的分类效果无法提升到最佳效果。其中训练集:验证集:测试集等于7:2:1。
2 安徽省历史文化名镇名村知识图谱的构建
2.1 Schema 层的构建
本文基于Protégé 软件构建知识图谱的概念层(Schema层),具体的概念层如图2所示。Schema层的构建大致可以划分为以下4个部分:1)类别的定义。2)类别的层次。3)对象属性。4)关系属性。
为了合理地构建适用于旅游推荐及历史文化传承的历史文化名镇名村知识图谱,基于安徽省历史文化名镇名村的相关知识进行分析,以名镇名村为核心实体,扩充与名镇名村的旅游业相关联的实体。根据对安徽省文化博物馆相关村镇介绍的分析,本研究的知识图谱定义了17个实体类,以及13个关系类别,具体如图3所示。
2.2 实体抽取
知识抽取技术可以应用于多种数据源,如表格类型的数据、纯文本的数据以及数据库中的数据都可作为知识抽取的源数据。本文中涉及的知识抽取技术在非结构化文本的基础上进行,通过命名实体识别技术以及基于词典匹配的关系抽取技术获取构建所需的节点、关系信息,具体内容有:名镇名村的地址、涉及的景点信息、相关人物以及相关事迹等。