基于tesseract.js Web 图片文字搜索定位浏览器扩展
作者: 张斌和
摘要:该研究设计和开发了一种基于tesseract.js的Web图片文字搜索定位的浏览器扩展,旨在为用户提供在Web浏览器中准确搜索和定位图片中的文字的便捷工具。该扩展利用tesseract.js作为OCR引擎,直接在浏览器中识别图片中的文字、提供搜索定位功能。实验结果表明,该扩展程序具有准确性和性能,能快速识别图像中的文字并提供准确的搜索定位结果。与传统OCR方法相比,该扩展消除了对专门硬件设备和繁重前期处理的依赖,为图像文字搜索与定位提供了轻量级、方便和高效的解决方案。该扩展可用于网页搜索、文本分析和信息抽取等任务,并具有广泛的应用潜力。
关键词:tesseract.js;OCR;图像文字搜索;浏览器扩展;搜索定位
中图分类号:TP311 文献标识码:A文章编号:1009-3044(2023)28-0060-03
0 引言
随着互联网的迅速发展和数字化内容的日益增加,图片中所包含的文字信息对于网页搜索、文本分析和信息抽取等任务变得越来越重要。然而,传统的文本搜索方法无法直接从图片中检索关键信息,这给利用图像进行准确的文字搜索和定位带来了挑战。
为了解决这一问题,光学字符识别(OCR) 技术被广泛应用于将图像中的文字提取为可供计算机处理的文本形式。然而,传统的OCR方法在应用上存在一些限制,如需要专门的硬件设备和繁重的前期处理。为了提供更方便和高效的图像文字搜索定位工具,近年来在Web浏览器中进行图像识别和OCR的研究引起了广泛关注。
本研究旨在设计和开发一种基于tesseract.js的浏览器扩展,旨在为用户提供一种在Web浏览器中准确搜索和定位图片中的文字的便捷工具[1-3]。该扩展利用tesseract.js 作为OCR 引擎,结合浏览器扩展的功能,实现了直接在浏览器中识别图片中的文字、提供搜索定位功能的能力。
与传统的OCR方法相比,基于tesseract.js的浏览器扩展具有以下优势。首先,通过借助现有的浏览器平台,消除了对专门硬件设备和前期处理的依赖,提供了一种轻量级的图像文字搜索与定位解决方案。其次,扩展程序运行在用户的浏览器环境中,可以在保护用户隐私的同时提供本地化的图像文字处理。同时,基于tesseract.js引擎的高性能和可靠性可以保证文字识别的准确性和效率。
在本研究中,将详细介绍基于tesseract.js的浏览器扩展的设计与实现,并进行实验评估。将讨论扩展程序的功能、准确性和性能,并与相关方法进行比较。最后,探讨该扩展程序在实际应用领域的潜在价值,并提出改进的建议和未来的研究方向。
1 方法
本节将详细介绍基于tesseract.js的Web图片文字搜索定位的浏览器扩展的设计和实现方法。首先介绍系统架构,包括背景脚本、内容脚本和相关的JavaS⁃cript文件。接着解释tesseract.js的作用和OCR引擎的组成。最后详细描述浏览器扩展的关键功能和实现细节。
1.1 系统架构
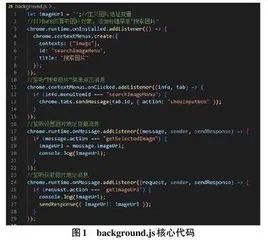
基于tesseract.js的Web图片文字搜索定位的浏览器扩展的系统架构包括背景脚本(background.js) 、内容脚本(content.js) 和相关的JavaScript 文件(tesseract.js、worker.js、tesseract-core-simd.wasm.js) 。背景脚本负责处理扩展程序的安装、右键菜单的创建和消息传递,而内容脚本则负责与当前网页进行交互和执行图像文字搜索定位的实际操作。
1.2 tesseract.js 和OCR 引擎
tesseract.js是基于JavaScript的OCR库,利用Web⁃Assembly技术加载和运行一个OCR引擎的二进制文件(tesseract-core-simd.wasm.js) 。该OCR引擎是基于tesseract项目的开源引擎,经过优化以便在浏览器中进行高性能的文字识别。
1.3 浏览器扩展功能
基于tesseract.js的Web图片文字搜索定位的浏览器扩展具有以下关键功能:右键菜单创建:在图像上右键点击时,通过背景脚本创建一个右键菜单项,使用户能够触发图像文字搜索定位功能。
图像文字搜索触发:当用户选择右键菜单中的搜索图片选项时,内容脚本将发送消息给背景脚本,请求显示一个输入框以接收用户输入的搜索内容。
图像处理与OCR实现:当用户在输入框中输入搜索内容并点击搜索按钮时,内容脚本将获取所选图像的URL,并利用tesseract.js库和OCR引擎对图像进行文字识别。识别的结果将与搜索内容进行匹配和定位,以便进行进一步操作。
搜索定位结果展示:搜索定位结果将以标注的方式展示在页面上,例如在识别出的文本区域周围绘制边框或标记搜索关键词。此外,还可以提供关闭按钮,供用户随时关闭搜索定位结果的显示。
2 实验和实现
本节将详细介绍基于tesseract.js的Web图片文字搜索定位的浏览器扩展的具体实现和实验过程。首先介绍实现细节,包括代码中的各个部分的作用和互动。然后描述实验设置,包括实验环境、测试网页和相关的图像和文本数据集。最后展示实验结果,并对系统功能和性能进行评估。
2.1 实现细节
基于tesseract.js的Web图片文字搜索定位的浏览器扩展包括以下关键部分:背景脚本(background.js) :负责处理扩展程序的安装和更新以及监听消息传递。通过与内容脚本进行通信,接收来自内容脚本的搜索请求,并与图片文本识别模块进行交互。
内容脚本(content.js) :在当前网页加载时注入,负责与网页进行交互和执行OCR搜索定位操作。通过与背景脚本通信,触发搜索请求并接收识别结果,并将结果展示到网页上。
tesseract.js:作为核心库文件,负责加载和运行OCR 引擎。它与worker. js 和tesseract-core-simd.wasm.js进行交互,并提供文字识别的功能。
worker.js:作为后台工作器,运行在浏览器后台,通过与tesseract-core-simd.wasm.js文件的交互执行实际的图像处理和OCR操作。
tesseract-core-simd.wasm.js:包含了基于WebAs⁃sembly的高性能OCR引擎。它与tesseract.js和worker.js协同工作,提供准确和高效的文字识别功能。
2.2 实验设置
为了评估基于tesseract.js的Web图片文字搜索定位的浏览器扩展的性能和功能,本文进行了以下实验设置:实验环境:使用了一台配备现代Web浏览器的计算机作为实验平台。运行Google Chrome浏览器,并确保所使用的扩展程序在该环境下正常运行。
测试网页:选择了一组包含图片中包含文字的网页作为测试对象。这些网页包括新闻文章、购物页面和博客等不同类型的内容,以保证实验的多样性。
图像和文本数据集:从网络上获取不同类型的图片,并给这些图片添加文字,构建用于实验的图像和文本数据集。这些数据集被用来模拟真实的网页环境,以检验扩展程序对不同类型图像的识别和搜索能力。
2.3 实验结果
对基于tesseract.js的Web图片文字搜索定位的浏览器扩展进行了一系列实验,并评估了其功能和性能。实验结果表明,该扩展程序在不同类型的网页环境下能够准确地识别图片中的文字,并根据用户的搜索内容进行定位和框选。
在功能方面,扩展程序能够成功创建右键菜单,并将搜索请求和识别结果传递给后台处理。对于搜索功能,扩展程序能够根据用户的输入快速搜索并定位感兴趣的文本区域,并进行标注展示。在性能方面,扩展程序能够在合理的时间内完成图像处理和文字识别,并以可接受的速度呈现搜索定位结果。
3 讨论
本节将对基于tesseract.js的Web图片文字搜索定位的浏览器扩展进行讨论,包括功能评估和局限性、实际应用场景以及与相关工作的比较。
3.1 功能评估和局限性
针对扩展程序的功能,进行了评估。扩展程序在准确性方面表现出色,能够有效识别和定位图像中的文字。在搜索功能上也取得了良好的效果,能够根据用户的搜索内容快速定位感兴趣的文本区域。此外,扩展程序提供了用户友好的界面和交互方式,例如标记搜索关键词,提升了用户体验。
然而,需要认识到基于tesseract.js的Web图片文字搜索定位的浏览器扩展存在一些局限性。首先,扩展程序可能受到图像质量和复杂度的影响,对于低质量或含有干扰元素的图像,识别和定位准确性可能会降低。其次,扩展程序仍然依赖于tesseract.js 作为OCR引擎,其性能和准确性受到引擎本身的限制。进一步的改进和优化可能需要考虑更先进的OCR技术和算法。
3.2 实际应用场景
基于tesseract.js的Web图片文字搜索定位的浏览器扩展在实际应用中具有广泛的潜在价值。首先,它可以为用户提供网页图像中文字的直接搜索和定位能力,方便用户从图片中获取所需的信息。其次,它还可以用于图像文档的搜索和整理,提高文档管理的效率和准确性[4]。
3.3 与相关工作的比较
基于tesseract.js的Web图片文字搜索定位的浏览器扩展与其他类似的图像文字搜索和定位工具相比具有一些独特的优势。首先,与传统的OCR技术相比,它不需要额外的硬件设备和复杂的前期处理,用户可以直接在浏览器中完成图片文字识别和搜索。其次,基于tesseract.js的引擎和WebAssembly技术,扩展程序提供了高性能的文字识别功能,能够快速和准确地处理图像中的文字。
然而,与其他类似扩展和工具相比,基于tesser⁃act.js的浏览器扩展仍然存在一些局限性。例如,某些专用的OCR软件和服务可能提供更高级的文字识别和定位功能,但它们通常需要付费或在计算能力方面更为要求严格。此外,一些商业化的图像处理和OCR 解决方案可能在扩展程序中尚未完全覆盖的领域中具有一定的竞争力。
4 结束语
设计和实现基于tesseract.js的Web图片文字搜索定位的浏览器扩展,旨在为用户提供在Web浏览器中准确搜索和定位图片中文字的便捷工具。该扩展利用tesseract.js作为OCR引擎,并通过借助WebAssem⁃bly技术实现了高准确性的文字识别和搜索定位功能,提供了直接从图像中获取所需信息的方式。
本研究的主要贡献如下:
首先,提出了基于tesseract.js的Web图片文字搜索定位的浏览器扩展的概念和设计。通过结合现有的OCR技术和Web浏览器技术,实现了一个轻量级、方便和高效的图像文字搜索定位工具,使用户能够在浏览器中直接操作图像并提取其中的文字信息。
其次,详细介绍了扩展程序的架构和关键功能。通过背景脚本、内容脚本和相关的JavaScript文件的协同工作,扩展程序能够与浏览器平台和OCR引擎进行交互,实现图像处理、文字识别和搜索定位等功能。
实验结果展示了基于tesseract.js的Web图片文字搜索定位的浏览器扩展在不同类型的网页环境下的准确性和性能。实验评估表明,该扩展程序能够快速识别图片中的文字,并提供准确的搜索定位结果,为用户提供了一个方便和高效的图像文字搜索定位工具。
尽管基于tesseract.js的Web图片文字搜索定位的浏览器扩展在实验中展现出了良好的功能和性能,但也存在一些局限性和改进空间。改进方向可以包括优化图像处理算法、提高识别准确性,以及扩展更多实际应用场景的适用性。
未来工作可以进一步探索基于深度学习的OCR技术和算法,以提高文字识别的准确性和效率[5]。此外,可以考虑进一步优化扩展程序的用户界面和交互体验,使其更加友好和易用。
基于tesseract.js的Web图片文字搜索定位的浏览器扩展在图像文字处理领域具有广泛的应用潜力,可以在网页搜索、文本分析和信息抽取等任务中发挥重要作用。未来的研究可以进一步拓展应用场景,并深入探索该领域的技术创新和改进方向。
参考文献:
[1] naptha/tesseract.js:一个基于JavaScript的OCR库,提供了在
Web浏览器中进行文字识别的功能[EB/OL].[2023-02-21].
https://github.com/naptha/tesseract.js.
[2] Tshetrim/Image-To-Text-OCR-extension-for-ChatGPT:一个
基于ChatGPT的图像转文本OCR扩展程序,通过整合OCR
技术和聊天机器人技术,实现了图像中文字的搜索和转换
[EB/OL].[2023-02-21].https://github.com/Tshetrim/Image-To-
Text-OCR-extension-for-ChatGPT.
[3] 王晓东,王健,赵玉伟.基于WebAssembly的图像文字识别[J].
计算机应用,2022,42(4):113-119.
[4] 张晓东,程龙,刘志平.基于Tesseract的Web图片文字识别扩
展[J].计算机科学,2020,47(4):107-112.
[5] 张强,郑浩,张亚文.基于深度学习的图像文字识别[J].计算
机学报,2021,44(2):447-460.
【通联编辑:谢媛媛】