基于YOLOv5的课堂抬头低头行为识别研究
作者: 欧阳维晰 樊万姝 陈麟伟
摘要:近年来,在人工智能技术促进教育改革的大背景下,以深度学习为代表的核心技术推动了教育领域的智能化发展。文章将深度学习技术应用于高校教学课堂场景中,提出一种基于YOLOv5的课堂抬头低头行为识别方法。利用监控视频数据提取图像帧进行人工标注并构建一个包含2 000张图像的数据集。通过K-means和遗传算法生成与该数据集具有更高匹配度的锚框,选取最优参数的网络模型对学生进行检测并识别其抬头低头行为状态。实验结果表明,YOLOv5算法对课堂抬头低头行为有很好的检测识别效果。
关键词: 目标检测; 深度学习; 数据标注; YOLOv5; 抬头低头行为
中图分类号:TP391 文献标识码:A文章编号:1009-3044(2023)29-0009-04
0 引言
随着智能化教育体系的不断发展和完善,如何将人工智能技术更好地应用于高校课堂教学场景中具有现实需求性。目前高校课堂教学纪律主要依靠于教师的管理和学生的自我约束,教室中的监控录像无法实现对课堂上每个学生的课堂行为进行监督与管理,教师不能及时接收学生对教学情况的真实反馈。
鉴于此,利用智能化技术[1]对课堂学生行为进行监测具有必要性和迫切性。针对课堂学生行为的检测识别,传统方法大多使用特征检测算法及分类算法对其状态进行提取和分类。最近,深度学习的快速发展为学生行为检测识别提供了新的思路。不同于传统的人工提取工作,深度学习方法不需显式地给出具体的检测模型,而是利用设计好的网络模型端到端地隐式学习相应的映射函数,在识别精度上有了较大程度提升[2]。得益于深度学习在图像数据集上具有很强的学习能力,本文采用检测速度和精度都较优的YOLOv5 算法对学生课堂抬头低头行为识别,针对学生不同状态实时反馈得到一个合理识别结果。将深度学习技术引入高校的教学质量评估中,实时对学生课堂上的抬头低头状态进行检测,有助于教师及时了解学生的学习状态,根据学生反馈调整教学方式以提高教学质量,推动高校课堂教学的改革和教学体系的优化。
1 基于YOLOv5的课堂抬头低头行为识别算法
1.1 YOLOv5s 网络框架
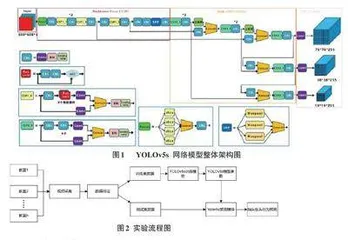
YOLOv5作为基于深度学习的物体检测框架的典型代表,被广泛应用于各类目标检测任务。该算法是YOLO系列目标检测算法的第五代,相比前几代算法,在速度与精度方面都得到了极大的提升。目前,YO⁃LOv5 共有4 种网络模型YOLOv5s、YOLOv5l、YO⁃LOv5m以及YOLOv5x,其中YOLOv5s是YOLOv5系列中网络深度和宽度最小的模型[3],可以更好地应用于小数据集的模型训练。鉴于此,本文采用YOLOv5s模型实现学生课堂抬头低头行为识别。YOLOv5s网络模型主要由Input、Backbone、Neck、Prediction 四部分构成。YOLOv5s算法的整体网络架构如图1所示。
1.1.1 Input
YOLOv5s的输入端采用Mosaic数据增强的方式,对多张大学生课堂图片进行处理,进而扩充数据集,提升模型对小目标检测的性能;在每次训练时,基于训练数据自动学习的方式自适应计算最佳锚框值。在网络训练阶段,模型根据初始锚点框输出相应的预测框,计算其与真实框之间的差异,执行反向更新操作,从而迭代更新网络参数;此外,YOLOv5s对原始课堂的图片进行缩放时使用了自适应缩放技术,在缩放后的图片中自适应地填充最少的黑边,旨在进行推理时,大幅降低计算量,进一步提升目标检测速度。
1.1.2 Backbone
Backbone 主要包含Focus 结构以及CSP 结构[4]。Focus结构用于实现高分辨率图像信息从空间维到通道维的转换,将大小为608×608×3的课堂图片输入到Focus结构,经过4次切片操作得到大小为304×304×12的特征图,再使用1次32个卷积核的卷积操作输出大小为304×304×32的课堂图片特征图。YOLOv5s设计了两种CSP结构:CSP1_X和CSP2_X,分别应用于Backbone和Neck中。CSP结构克服了其他卷积神经网络框架中梯度信息重复的缺陷,在减少模型的参数量和FLOPS数值的同时提高了推理速度和准确率。此外,Backbone 中还加入了SPP模块,增强网络对多尺度特征进行融合的能力。
1.1.3 Neck
Neck是在Backbone和Prediction之间插入的用于更好地提取融合特征的网络层,其采用特征金字塔网络(Feature Pyramid Networks,FPN) [5]和感知对抗网络(Path Aggregation Network,PAN) 相组合的结构进行上采样和下采样。通过自顶向下的FPN,上采样高层特征以传递强语义特征,生成预测特征图。在FPN后添加自底向上的PAN传达强定位特征。FPN与PAN的联合使用可以实现不同的主干层对不同的检测层的参数聚合,同时获得语义特征和定位特征,进一步提高模型的特征提取能力。
1.1.4 Prediction
Prediction主要由损失函数和非极大值抑制两部分组成。YOLOv5s中采用GIOU_Loss [6]作为Bounding box 的损失函数。GIOU_Loss中增加了相交尺度的衡量方式,有利于缓解课堂图片边界框不重合的特殊情况。针对大量目标框的筛选问题,使用非极大值抑制方法对冗余的预测框进行过滤,以获取最优的目标框,进一步提升算法的检测精度。
1.2 实验流程
基于YOLOv5的课堂抬头低头行为识别主要包括数据集构建、模型训练以及抬头低头姿态检测估计三部分。首先通过安装在高校不同教室中的多个摄像头采集多个上课视频信息并截取成帧图片,使用LabelImg对其进行标注以构建抬头低头识别数据集;其次通过YO⁃LOv5s训练模块对数据集进行训练获取模型权重数据;最后使用YOLOv5s预测模块完成学生低头行为预测。实验流程如图2所示。
2 实验结果与分析
2.1 数据集构建
本实验收集了大量大学生课堂上课视频,尽量选择在同一地点,不同时间,人数差不多的视频。首先,从筛选出的每个视频的中间部分每隔5s截取1张图片,共截取100张图片。由于大学生在课堂上的行为状态相对单一,一般只有抬头听课和低头看书两种状态,为保证数据的质量和可靠性,所截取的100张图片里学生的抬头低头状态总量尽量在同一个范围内波动。经以上数据处理后采集并整理得到2 000张数据图片。随后,采用LabelImg开源数据标注工具对学生抬头低头状态进行标签标注,并将图片的标注格式由xml转换为txt文件格式,即YOLOv5s数据格式。图3 为数据集标注样例。txt文件中每行第一个数据表示目标类别,0代表抬头,1代表低头,其余四个数字分别代表目标左上角的坐标和宽高。最后,以7:2:1的比例将标注好的数据划分为训练集、测试集和验证集,并将这些数据集中的图片分别存放相应的.txt文件下。
2.2 评价指标
本实验采用目标检测任务中常用的平均精度均值(mean Average Precision,mAP) [7]来评价模型性能。mAP是基于召回率(Recall) 、精准率(Precision) 以及平均精度(Average Precision,AP) 三个指标。