基于改进双线性的细粒度图像分类方法
作者: 王长庚
摘要:文章研究了基于双线性卷积神经网络,结合可变形卷积和核化网络对动物数据集进行细粒度图像分类。其中,可变形卷积通过对特征值进行调整,能自适应被识别物体的特征边界,核聚合网络克服了BCNN仅关注线性相关的缺点,在非线性领域进一步增强细粒度特征的提取能力,丰富了不同通道间的卷积特征。实验在不同动物数据集上进行,与BCNN模型、其他改进BCNN的模型对比,精确度达到98.85%,同时证明了优异的泛化能力。
关键词:细粒度图像分类;双线性卷积神经网络;可变形卷积;动物分类;目标检测
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2023)30-0006-05
开放科学(资源服务)标识码(OSID) :
0 引言
动物分类学历史悠久,其核心思想是根据动物的体态、习性等客观特征,以相似性为评估标准,构建整个动物体系。在农业领域中,正确的动物分类,有助于畜牧业、渔业养殖领域中遗传育种的筛选,而生物存在生殖隔离的特性,决定了畜牧业培育优良高产的动物品种前,需要区分并梳理动物大类内的各种子类,然后才能从类内不同品种的动物特性中归纳优良高产动物的杂交方法。这样对某一大类精准划分不同子类的过程称为细粒度分类(Fine-grained Classification) 。细粒度分类相对于类间的粗粒度划分,更加注重类间差异小、类内差异大两种模式识别[1]。例如,渔业养殖中“红鲷鱼”和“金头鲷鱼”,以及畜牧作业生产中“美洲赤犬”和“维希拉猎犬”作为同类动物的不同细类(图1) ,它们仅在毛发长短、身体颜色、形态、动作、亮度、拍摄角度等细微处存在差异,非领域专家很难区分开来。此外,在识别作物与杂草、昆虫品种识别[2]、遥感识别、农用机型、木薯病害检测[3]等场合,亦亟需高效细粒度分类技术。
捕获被识别物体的图像只是细粒度图像分类技术的基础,更多的是依靠卷积神经网络(Convolution Neural Network) 对图像进行分析。卷积神经网络模拟人对物体的分类方式,在图像上以卷积的方式提取被识别物体的边界、形状、颜色、大小等表层信息,随着卷积层加深,神经网络甚至能对被识别物体的特征进行高维抽象使得分类精确度更高,但传统的神经网络在训练时非常依赖于硬件设备,卷积层的加深会给计算资源带来沉重负担。在农业分类领域,这样的高成本与畜牧业推广“低廉、高效”的主旨相悖。因此,既要保证细粒度图像分类高精度的同时,又能减少计算资源的消耗是值得探索并深入研究的。本文基于双线性卷积神经网络进行改进,在不同动物数据集下进行实验,对比分析主流分类方法的优劣,提出综合性能优异的深度学习模型。
1 国内外研究现状
传统的图像分类十分依赖人工标注特征,这样提取的特征标准不一且人力成本高昂。深度学习技术的引入迅速解决了这一症结,受生物学启发通过模拟人的神经系统,设计人工神经网络,让模型自下而上地自主学习不同动物的子类特征,强有力地弥补了传统识别动物子类方法的不足。尽管Zhang等人[4]提出了强监督细粒度分类Part-based R-CNNs,通过记分函数标记被识别信息,同时基于几何约束的方法对特征建模,该模型在CUB200-2011(Caltech-UCSD鸟类数据集)上证明了比传统的细粒度分类方法具备更高精确度。He等人[5]提出另一种强监督分类模型Mask R-CNN,通过引入线性插值法,在Faster RCNN进行目标检测时,配合语义分割法FCN完成图像分类任务。强监督算法保证了细粒度图像分类的高精确,但训练时使用大量人工标注信息,包含类别、局部区域位置、标注框等,人工成本昂贵。因此,特别需要仅输入被识别物体的类别,就可以训练输出的算法,即弱监督学习。Mahmoudi等人[6]利用SVM替换全连接层,将输入特征映射到更高维空间进行分类,使用效果未能达到人们的预期。而后,Wang、Yan等人[7-8]分别引入多尺度学习和注意力机制来改进特征学习,He等人[9]通过定位法关注差异性局部区域,都在一定程度提高了图像识别精确度,却严重依赖人工特征设计。Yao等人[10]探讨了将迁移学习融入文本细粒度识别,较之特征学习取得了更好的效果,但是未能有效应用在包含信息更多的细粒度图像分类领域。Lin等人[11]设计了双线性卷积神经网络(Bilinear Convolutional Neural Networks,BCNN) ,作为第一个支持端到端训练的协方差池化模型,其创新点是双通道协同工作,一个通道用以提取细分类物体的特征,另一个通道用以特征定位,每个通道中都配置有独立的卷积神经网络。Gao等[12]立足于BCNN,从特征分布的维度重新构建感受野,并取得了一定的进展。但是,这些模型都未能关注到特征图的通道数、特征的空间位置,以及特征融合过程中产生的非线性映射的问题。
2 相关工作
2.1 可变形卷积
常规的卷积过程是多个固定的卷积核对特征图进行下采样的过程,例如在BCNN中卷积核大小为3×3,通过步长参数对3×224×224的初始化图像进行特征提取。这样的过程始终在一个规律性的区间内捕捉特征值,如图2所示,细粒度图像特征关键之处就是微小差异,而且被识别动物的边界、体态等特征又根据拍摄角度的不同呈现不规律的特征。对此,本文改进BCNN的卷积过程,引入可变形卷积,对关键特征值进行微调,使得卷积过程中拟合被识别物体复杂的边界特征。
常规卷积和可变形卷积对比如图2所示。由此可以看出,常规卷积是在一个3×3的固定范围内提取特征,而可变形卷积通过引入位置偏置,可以扩大感受野,将周边特征也纳入特征搜索范围。对被识别物体的卷积过程分解,进一步解读可变形卷积的差异,如图3所示。可以看出,常规卷积在狗的脖颈部位得到激活,且采样区域为3×3的正方形,这也表明了感受野受限于卷积核大小。然而,可变形卷积拥有非固定大小的卷积核,将激活区域扩大了狗的耳朵、四肢,显而易见,可变形卷积激活区域更贴近被识别物体的真实体态。
假设[Pn]表示已知特征区域[R]内的任意一点,在常规卷积后得到的结果可表示为:
[f(Pn)=P'n∈Rw(P'n)x(P'n+Pn)] (1)
其中,[P'n]表示区域[R]内位置,[w(P'n)]表示[P'n]的权重,[x]表示输入特征图的集合。可变形卷积在此基础上引入一个方向向量[{ΔPn|n=1,2,...,N}]代表位置偏移,且[N=R]。即可变形卷积公式为:
[f(Pn)=P'n∈Rw(P'n)x(P'n+Pn+ΔPn)] (2)
可变形卷积的实现过程如图4所示,在经过常规的卷积后,需要进行再卷积,这样做的目的是使卷积核变形,为得到被识别物体形态的不规则特征做准备,即调整卷积核的偏移量。偏移量通过方向向量表示,在平面图像识别中,从x和y两个方向发生位置偏移,从而达到偏移卷积核的目的。
从整体过程来看,特征输出与卷积偏移是同时进行的,为了在反向传播过程时也同步进行,偏移值x和y的反向传播需要通过双线性内插法完成。双线性内插法本质上是三次线性插值运算,即已知特征图的四个坐标点[Q(0,0)=(x0,y0)]、[Q(0,1)=(x0,y1)]、[Q(1,0)=(x1,y0)]、[Q(1,1)=(x1,y1)],双线性插值点[P=(x,y)]未知。故推导P点坐标公式如式(3)所示:
[f(P)=f(Q(0,0))(x1-x)(y1-y)(x1-x0)(y1-y0)+f(Q(1,0))(x-x0)(y1-y)(x1-x0)(y1-y0)+f(Q(0,1))(x1-x)(y-y0)(x1-x0)(y1-y0)+f(Q(1,1))(x-x0)(y-y0)(x1-x0)(y1-y0)] (3)
2.2 核聚合网络
核函数优化其实指的是kernel trick,本质上核函数是在做内积运算,并且在卷积神经网络中,随着深度的增加,数据维度也在增加,但是核函数内积却能保持不变。数学推导中,核函数必须连续,并且自身结构是具备对称性。基于此特性,最常见也是最成功的核函数应用是在SVM中,在低维数据映射到高维空间过程中起到了绝对作用。所以核函数适合在图像、文本、特征序列等数据集中找到一个相关关系,如果当前数据维度失效,那么便不停地向高维做再映射的操作,由于空间维度无上限,也就是说核函数映射也是无上限的,直至核函数在高维空间中找到一个相关关系足以很好地区分数据。也正是由于核函数支持高维空间映射的特性,所以如果目前数据所在维度无法拟合一条合适的线帮助分类的话,高维空间一定存在一个合适的分割区域,这个分割线如果返回到低维空间时,可能会表现出非线性关系,核函数可表达为[kernel(x,y)=<ϕ(x),ϕ(y)>]。
在输入图像通道上,双线性卷积网络首次以外积的方式保留了特征之间的线性关系,但是对于非线性相关的特征表达还不够深入,会产生信息损失,降低图像分类准确率。葛疏雨等人[13]引入核函数弥补特征信息,本文也对外积步骤进行指数核函数优化,使得卷积特征利用率能够进一步提高。
基于可变形卷积得到的特征图,开始核化三步骤,如图5所示。步骤1为归一化过程,对特征图进行L2范数归一化得到新的特征矩阵,其中[n]代表通道数,[N]代表特征图的乘积矩阵。步骤2为核化过程,以指数核函数的方式对外积结果进行核聚合操作,构建非线性特征关系。步骤3为矩阵幂正规化过程,对已构建非线性关系的特征进行指数幂输出,且输出结果为对称矩阵,故仅取上三角部分便可得到图像的特征输出,为softmax层做准备。
图5中,已知核函数公式为[P=K(XXT)],则指数核函数如式(4) 所示,其中[β>0]且支持参数调整。指数核函数还支持反向传播,故损失函数[l]对应矩阵[P]的反向传播公式如式(5) 所示,其中,“[∘]”表示基本积计算(Hadamard product) 。
[P'=K(XXT)=exp(β⋅XXT)d*d] (4)
[∂l∂A=β⋅P∘∂l∂P] (5)
3 实验过程
3.1 实验环境
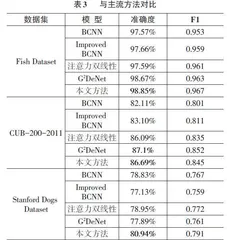
数据集介绍:适用于动物细分类的数据集较少,为了测试网络的性能和泛化能力,本文选择Fish Dataset、CUB-200-2011、Stanford Dogs Dataset等3种数据集进行实验。Stanford Dogs Dataset是 ImageNet 数据集的子类,由Stanford提供的狗类数据集,包含120种子类,图片数量合计20 580张,实验过程中划分训练集14 406张,测试集6 174张。CUB-200-2011是由加州理工学院提出的鸟类基础数据集,包含200 个类别,11 788张图片,实验过程中划分训练集8 252张,测试集3 536张。Fish Dataset[14]发表于ASU 2020,收集了红鲷鱼、鲈鱼、金鲷鱼、红鲻鱼、马鲭鱼、黑海鲱鱼等8种鱼类图片,Fish Dataset原数据集还包含虾类图片,为避免影响细分类效果,实验前期已剔除,实验过程中划分训练集5 600张,测试集2 400张。以上数据集可以用作细粒度分类,满足本文验证需要,如表1所示。
超参数设置。本文在训练过程中,以VGG16作为特征提取器,采用随机读取数据和标准正则化的方法。为便于GPU的并行运算batch_size设置为16,num_workers设置为2,图像尺寸统一为224×224,优化器为随机梯度下降法(Stochastic Gradient Descent,SGD) 和自适应估计法(Adaptive Moment Estimation,Adam) ,二者初始学习率皆设置为0.001,momentum设置为0.9,weight_decay设置为1E-5,损失函数为交叉熵损失函数。卷积过程中,卷积核大小设置为标准3×3,初始步长设置为2,初始填充值设置为1。