基于决策树C4.5模型的数据挖掘技术在学生成绩分析中的应用研究
作者: 田飞 展金梅
摘要:文章采用了决策树C4.5模型的数据挖掘技术对某高校21级软件专业的学生成绩进行深度分析,并生成决策树,同时挖掘出学生的期末考试成绩与课堂表现、考勤和平时实验有着密切的关系,找出影响该门课程考试成绩的关键因素是课堂表现,此结论能够对学生的学习,教师和教学管理者的工作起到指导作用。
关键词:决策树;C4.5模型;数据挖掘;成绩分析
中图分类号:TP274 文献标识码:A
文章编号:1009-3044(2023)30-0022-03
开放科学(资源服务)标识码(OSID) :
0 引言
在这个人工智能快速发展的时代,每所高校都拥有自己的教务管理系统,里面储存了学生在校期间的所学课程信息及考试成绩等数据,而很多高校只是用这些数据评价一个学生是否达到评优的标准、是否达到毕业标准等简单的审核与查询功能。其实,这些数据中还蕴含了许多更重要的信息,比如:影响学生学习的主要因素有哪些?这些因素又反映出什么问题?学校的校领导、教学管理者以及教师迫切希望从这些数据中挖掘出自己所关注的信息,这些信息可以通过决策树C4.5模型的数据挖掘技术来获得。
近年来,国内外许多学者运用数据挖掘技术分析学生的考试成绩方面进行得如火如荼,在中国知网总库中,同时以“数据挖掘”“学习成绩”检索,共检索出中文文献467篇,其中学术期刊184篇,学位论文279篇,会议论文4篇;外文文献42篇。其中,班文静等(2022) 基于多算法的在线学习成绩预测框架,融合神经网络、决策树、K-近邻、随机森林和逻辑回归算法预测学习者在线学习成绩,并进行了预测性能分析[1]。赵磊等(2021) 基于数据挖掘的MOOC学习者学业成绩的行为指标及算法模型、群体学习特征和教学干预策略进行了探究[2];李海洋等(2020) 利用Apriori算法建立关联分析挖掘模型,通过SPSS Clementine软件学生成绩与洗浴时间关联性[3],何普亮、张战胜(2019) 从教育数据挖掘的一般过程、教育数据挖掘的典型方法、常用工具以及目前国内外的相关典型应用等几个方面,对大数据时代的教育数据挖掘进行介绍和分析[4]。
1 数据挖掘技术
数据挖掘技术是人工智能快速发展时代的热点问题,它是利用深度学习、机器学习、神经网络、人工智能等理论及方法,借助Matlab、Python、SPSS等相关软件,从庞大的数据库中,提取有效数据,进行科学的深度分析,为了寻求人们以前没有发现的,但对今后的工作是非常有用的知识的过程[5-6]。
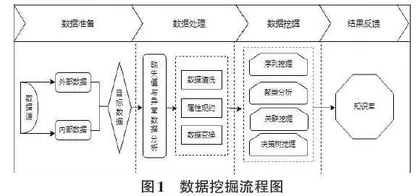
数据挖掘是一个反复进行、不断优化的过程,主要包括数据准备、数据处理、数据挖掘和结果反馈四个阶段,如图1所示。
2 决策树C4.5模型[7]
C4.5算法是对Ross Quinlan开发的ID3算法的改进,是用在机器学习、数据挖掘的分类问题中的算法,由J.Ross Quinlan提出,它与ID3算法一样使用了信息熵的概念,并通过学习数据来建立决策树。
2.1 信息熵
它是信息的数学期望,一般用来表示信息混乱、无序的程度。设数据样本集[T],类别属性具有[m]个不同值[C1,C2,…,Cm],则信息熵的计算公式为:
[E(T)=-i=1mPilog2Pi],(其中,[Pi=Cii=1mCi],[i=1,2,…,m]) (1)
数据样本集[S]的一个属性[A]有[k]个不同取值[a1,a2,…,ak],利用属性[A]将数据样本集[T]划分为[k]个子集[T1,T2,…,Tk],而且对于任意一个子集[Tj]类别属性也具有[m]个不同值[Cj1,Cj2,…,Cjm],则[Tj]的信息熵计算公式为:
[ETj=-i=1mPjilog2Pji],其中,[Pji=Cjii=1mCji],[i=1,2,…,m]) (2)
2.2 条件熵
以属性[A]为根进行分类的信息熵,其计算公式为:
[E(A)=j=1kCj1+Cj2+…+CjmC1+C2+…+CmE(Sj)] (3)
2.3 信息增益
以属性[A]的信息增益定义为:
[Gain(A)=E(T)-E(A)] (4)
2.4 信息增益率
属性[A]的信息增益率定义为:
[GainR(A)=Gain(A)E(T)] (5)
3 实例分析
3.1 数据准备
文中数据采用海南省某高校21级软件专业2个班级90名学生考试信息,主要包括学生的学号、实验成绩、考勤成绩、课堂表现、考试成绩等,如表1所示。
3.2 数据处理
由于学生退学、当兵、休学、缓考、缺考等原因,导致部分学生成绩信息不完整,从学生成绩信息表中剔除这些数据,剩下81条符合条件的数据,从21级软件1班、2班分别选取30名同学的考试成绩信息作为训练集数据,其余21名同学的考试信息作为测试集数据。
为了方便构建决策树C4.5模型,对81条有效数据进行预处理,实验成绩([A≥88],优秀,[82≤A<88],一般,[A<82],差),考勤成绩([B=100],好,[95≤B<100],中,[B<95],差),课堂表现([C≥90],好;[80≤C<90],中;[C<80],差),考试成绩([T≥75],优良,[60≤T<75],及格,[T<60],不及格)。得到学生成绩分析表,如表2所示。
3.3 数据挖掘
借助于matlab软件,对表2进行数据挖掘,分别计算信息熵、条件熵、信息增益与信息增益率。
1) 信息熵
考试成绩([T]) 分为优良、及格和不及格三个等级,其中优良有6人、及格18人、不及格36人。根据公式(1) 计算得到信息熵为
[E(T)=-660log2660-1860log21860-3660log23660=1.2955]
对于实验成绩([A]) 也分为优秀、一般、差三个等级,根据公式(2) 分别计算实验成绩优秀、一般、差的条件下考试成绩的信息熵为:
[E(T1)=-325log2325-725log2725-1525log21525=1.3235]
[E(T2)=-329log2329-929log2929-1729log21729=1.3141]
[E(T3)=-46log246-26log226=0.9183]
2) 条件熵
利用公式(3) 计算以实验成绩([A]) 分类的条件熵:
[E(A)=2560E(T1)+2960E(T2)+660E(T3)=1.2784]
3) 信息增益
利用公式(4) 计算实验成绩([A]) 的信息增益:
[Gain(A)=E(T)-E(A)=1.2955-1.2784=0.0171]
4) 信息增益率
利用公式(5) 计算实验成绩([A]) 的信息增益率为:
[GainR(A)=Gain(A)E(T)=0.0132]
运用同样的办法,分别计算考勤成绩([B]) 、课堂表现([C]) 的信息增益率分别为:
[GainR(B)=0.0199],[GainR(C)=0.1222]
3.4 结果与反馈
由于[GainR(C)>GainR(B)>GainR(A)],所以选择课堂表现([C]) 作为决策树的根节点,然后在每个分支上重复采用3.3的方法递归计算,构建决策树如图2所示。
为了避免决策树C4.5模型对训练集30名同学的考试成绩信息实现较好的预测,而对测试集21名同学的考试信息预测较差,即出现“过渡拟合”现象,需要对图2的决策树进行剪枝操作,决策树的剪枝策略分为预剪枝和后剪枝两种。在此,采用后剪枝的方法对图2决策树进行剪枝,保留课堂表现、考勤成绩对学生成绩影响较大的属性值,剪去影响较小的属性值实验成绩,得到决策树图3。
通过决策树图2、图3可以发现,学生只有课堂表现、考勤成绩、实验成绩同时为优的时候,最终考试成绩才能达到优良水平,有一项为一般水平的情况下考试成绩为及格,两项及以上表现不好,考试成绩就会不及格。实际上,在训练集60名学生的考试信息中,优良的人数仅有6人,不及格的人数却高达36人,学生的考试成绩偏低,导致这一结果的原因可能是由于试卷的难度过大,还需进一步深度地挖掘。
最后采用测试集21名学生的考试信息对该决策树进行检验,准确率达到了85%以上,说明该模型是有效的。
4 结论
文中构建了决策树C4.5模型,对21级软件81名同学的考试信息进行深度挖掘,并验证了该模型的可行性,该模型表明学生的期末考试成绩与课堂表现、考勤和平时实验有着密切的关系,因此,各任课教师应该加强过程管理,首先,课堂上调动学生积极参与到的教学过程中来,主动回答问题;其次,要加强考勤,避免学生出现迟到早退现象,有事要提前请假;最后,要注重平时实验指导,提高学生的动手操作能力。这对提高学生考试成绩有着至关重要的作用。
参考文献:
[1] 班文静,姜强,赵蔚.基于多算法融合的在线学习成绩精准预测研究[J].现代远距离教育,2022(3):37-45.
[2] 赵磊,邓彤,吴卓平.基于数据挖掘的MOOC学习者学业成绩预测与群体特征分析[J].重庆高教研究,2021,9(6):95-105.
[3] 李海洋,李忠,李莹,等.基于Apriori算法的学生成绩与洗浴时间关联性分析[J].中国教育技术装备,2020(4):38-40.
[4] 何普亮,张战胜.大数据时代的教育数据挖掘:方法、工具与应用[J].中国教育技术装备,2019(23):7-10.
[5] 李庆香.数据挖掘技术在高校学生成绩分析中的应用研究[D].重庆:西南大学,2009.
[6] 田飞.数据挖掘在茶叶行业客户关系管理系统的应用研究[J].福建茶叶,2017,39(4):20-21.
[7] 韩丽娜,韩改宁.决策树算法在学生成绩分析中的应用研究[J].电子设计工程,2017,25(2):18-21.
【通联编辑:王力】