企业级异构数据集成平台的设计与实现
作者: 吕悦
摘要:数据已成为一种关键新型生产要素,战略价值越来越重要。然而,企业内部存在数据源繁杂、数据集成流程复杂、数据开发效率低下等问题。为了充分释放数据价值,文章基于SpringBoot框架和微服务架构,集成Kafka和DataX等开源工具,设计并实现了一套异构数据源、灵活任务设计、双重调度的企业级数据集成平台,包括数据源管理、集成任务设计、任务调度、告警管理、用户管理和数据大屏等六大模块,满足不同场景下的数据需求,降低数据应用成本,提升企业的数据开发效率。
关键词:数据集成;企业级;异构数据源;DataX;Kafka
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2023)30-0044-04
开放科学(资源服务)标识码(OSID)
1 背景
随着中共中央、国务院印发了《数字中国建设整体布局规划》[1],以及国家数据局的成立,我国对数据治理和利用越来越重视。现阶段,数据已经成为除土地、劳动力、资本、技术以外的又一项关键生产要素,数据的战略价值越来越重要。当前各类企业中,随着互联网技术的发展,各信息系统中数据量呈现指数级增长。如何充分释放海量数据的价值,进行数据资源的整合利用,逐渐成为各数据拥有者关注的重点。
在传统企业中,各类业务需求冗杂,内部信息系统独立而分散,缺失统一的异构数据集成平台。传统数据开发模式存在开发效率低下、相同开发流程重复建设、各流程需要不同的人工干预等问题[2],须建立一套具备支持异构系统、不同数据开发流程的企业级数据集成平台。本文基于消息队列Kafka和开源数据同步工具DataX,设计并实现了异构数据源之间、可配置开发流程的企业级异构数据集成平台。
2 需求分析
传统的数据开发存在以下问题:
1) 各信息系统数据源复杂。数据类型可分为结构化和非结构化。结构化的数据包括MySQL、Oracle等关系型数据库、Excel文件、xml文件、JSON文件等。非结构化数据包括视频、音频、图片等。
2) 各项业务数据的集成过程中,存在不同的开发流程,需单独配置。由于不同的数据存在不同的网络结构中,如各业务专网、内外网、DMZ区等。在数据的传输过程中,需要额外的配置。同时,不同数据的清洗逻辑存在业务耦合性,需要专业人员进行逻辑处理。
3) 由于企业内部各项数据种类繁杂,数据集成任务多样,需建立任务监控告警流程,对异常任务信息及时告知相关数据开发人员和业务负责人员。同时,对异常任务记录并分析出错原因,建立常见问题库。
因此,急需建立异构数据源、数据开发流程可配置、数据任务可监控的异构数据集成平台。该平台应设置备份机制,提供稳定的数据集成服务,同时采取访问控制、传输加密等安全方案,保障安全性,并支持动态功能扩展,满足各类企业级业务需求。
3 技术调研
通过对现有数据集成工具进行调研,发现常用开源工具包括DataX[3]、Kettle、Apache Sqoop[4]等。
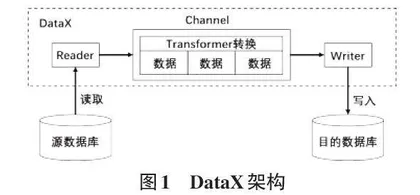
DataX是阿里巴巴开源的数据同步工具,可实现多种数据源之间的数据同步,如MySQL、Oracle、HDFS、HBase、Hive、Kafka、ES等各种不同类型的数据源。DataX采用了Framework+Plugin的架构设计,是一种可插拔式的架构设计方式。针对每种类型的数据源,DataX实现读插件Reader和写插件Writer。在数据同步时,对各种数据源读写插件的两两组合就可以实现相互同步,架构设计如图1所示[5]。按照DataX的规范,将Reader与Writer的配置编写成JSON脚本文件,然后利用DataX命令就可以实现数据同步操作。在进行数据同步时,Reader负责将源数据表中的数据按照用户的配置以规定的格式读取到内存中,然后Writer将内存中的数据按照用户的配置写入到目的数据表中,并可设置Transformer转换自定义业务逻辑。此外,DataX可单独部署,只需提供JDK与Python环境即可,并不依赖于其他环境。
Kettle是一款纯Java编写的开源ETL工具,可实现对不同数据源之间的读取、转换以及写入等操作。Kettle可对不同数据源之间进行数据读取、转换和写入,如关系型数据库、非关系型数据库HDFS、HTTP接口、中间件Kafka等。Kettle提供可视化的界面,通过对已封装组件拖拉拽的方式,编排数据各个处理流程,实现复杂业务逻辑的数据操作[6]。但是,Kettle工具本身相比其他工具不够轻量级,并且编排任务的操作相对复杂,学习成本较高。
Sqoop是Apache软件基金会下的一款开源数据同步工具,是命令行界面的应用程序,支持在各种关系型数据库与大数据集群之间完成数据同步操作,如MySQL和Hive之间进行数据同步。Sqoop的实现原理是将用户输入的命令转换成MapReduce任务,然后执行该MapReduce任务即可完成数据同步操作。因此,Sqoop需要依赖Hadoop环境才能正常运行。而一套大数据hadoop环境的搭建、运维、性能调优等工作成本较高。
由于Sqoop依赖于大数据环境和Kettle的学习,成本较高、不够轻量级,本文选择DataX作为底层数据集成工具。虽然Datax每次执行数据集成任务只能完成单次数据同步,然而将其纳入Quartz[7]定时管理,不但实现了数据同步的自主进行,还解决了数据增量时的同步问题。
另外,为了弥补DataX的延时性,可通过消息队列实时接收各种数据集成通知,并根据通知内容,触发对应数据集成任务。消息队列是一种应用程序之间的通信方案。应用程序通过读写出入队列的消息来通信,而无须专用连接。其中,Kafka是基于发布/订阅模式的分布式消息队列,是应用最广泛的消息中间件之一[8]。由于其分布式、易于扩展的特点,相比于传统的消息系统有着巨大优势。其内部支持多订阅模式,自动平衡消费者与生产者,为发布和订阅提供高吞吐量,同时提供消息的持久化选项。另外,在接收数据集成通知的数据量较多时,Kafka还可对数据进行流量削峰,降低服务器压力。
因此,结合以上需求分析和技术调研,为了向用户提供便捷统一数据集成服务,采用微服务Spring Boot框架[9]和Spring Cloud[10]框架,应用开源数据开发工具DataX和消息队列Kafka,实现具备高性能、大吞吐量、高可扩展、动态发布等特性的异构数据集成平台。
4 系统设计
如图2所示,异构数据集成平台的功能,共分为六大模块,分别是数据源管理、集成任务设计、任务调度、告警管理、用户管理和数据大屏。
数据源管理,主要用于对不同数据源信息的录入、更新、查询、删除等管理功能。根据数据类型,将数据源分为结构化和非结构化。其中,对于结构化数据,常见的数据源包括传统关系型数据库,如,MySQL、Oracle、SQL Server等。同时,HTTP接口的形式更是数据共享的常用手段。对于非结构化数据,常见的数据源为大数据集群、各种小众数据库、图片、视频、音频等。在用户录入数据源时,针对关系型数据库、大数据集群、HTTP接口等方式,通过JDBC连接、发送HTTP请求等方式,增加测试数据源联通功能,对用户填写的url连接进行验证,保证数据源的准确性。
集成任务设计,主要用于对不同的集成任务流程进行设计。通过对数据流转过程的研究,数据集成任务设计为四大阶段,即,数据抽取、数据清洗、数据转换、数据加载。在数据抽取阶段中,可选择所需数据源中对应数据。对于关系型数据库和大数据集群,可选择所需数据表和对应字段内容。对于HTTP接口,可增加不同查询参数,获取模板JSON数据内容,并对模板JSON数据进行解析,选择所需字段内容。在数据清洗阶段中,主要对抽取的数据进行简单的逻辑清洗,如,增加数值范围判断、规范数据内容、补全缺失值等。在数据转换阶段中,主要对规范的数据进行复杂业务逻辑处理,增加了数据集成任务的灵活性。在数据加载阶段中,主要对已完成业务逻辑处理的数据加载到目标数据源中,须确认处理完成的数据内容,并选择目标数据源中对应表信息、字段信息。经过以上四个阶段后,标准的数据集成任务已被建立,可满足大多数据集成任务需求。
任务调度,主要用于对各种数据集成任务设定调度计划。数据集成任务的调度可分为定时任务和实时任务。对于定时的数据集成任务,通常根据用户的业务需要,设定为每天、每小时、每时、每分等,编排对任务的调度计划。对于有实时需求的数据集成任务,采用对消息队列Kafka的集成,接收实时数据通知,选择数据集成任务进行调度。
告警管理,主要用于对任务执行情况进行监控,并对异常任务发送告警内容。每次数据集成任务的执行日志都可通过此模块查看。用户可对已开启调度的数据集成任务设定告警配置,包括告警人、联系方式、告警方式、异常任务信息、异常原因等。由于企业内部的网络结构复杂,因此,告警方式包括邮箱通知、WebHook告警、自定义告警等。自定义告警可根据企业网络结构的设置,定制化集成告警功能包,解决网络隔离的问题,进行告警内容的传送。
用户管理,主要用于对各类用户的账号、密码、权限等进行配置。用户包括管理员、平台运维和普通用户三种。普通用户可使用数据源管理、集成任务设计、任务调度、任务告警等功能,进行各类数据的集成。由于不同的用户属于不同部门,各个部门下的各类数据源、数据集成任务、告警配置等信息,应只被当前部门下员工获取和操作,所以,应对不同种类数据增加权限控制功能,防止不同部门下的用户越权访问和越权操作的行为。针对平台运维,可检查各类任务调度计划和告警配置,修正不合理任务配置并通过平台的告警配置通知到对应任务负责人。平台运维还需定期清除各个模块的无用数据,保证平台运行的准确性和稳定性。
数据大屏,主要用于对异构数据集成平台的整体展示,包括集成任务的执行情况、任务告警情况、任务执行成功率、任务集成配置、任务告警配置等信息。对于集成任务的执行情况,采用条形图,展示最近一周任务执行成功和失败的数量。对于任务告警情况,采用折线图,展示最近一周内任务的告警总数。对于任务执行成功率,采用仪表盘的形式展示。对于任务集成配置和告警配置,采用表格形式展示,并增加自动向上滚动的效果,展示多条数据信息。
5 系统实现
在系统的实现上,采用SpringBoot框架和微服务架构作为后端开发框架,采用vue作为前端开发框架,采用MySQL数据库,对数据源管理、集成任务设计、任务调度、告警管理、用户管理和数据大屏模块,设计数据库表,基于MySQL保存各模块数据,采用Kafka消息队列,用于实时消息推送和订阅。平台部署采用Nginx负载均衡,将用户请求转发到多台应用服务器上,各台服务器的运行环境为Tomcat8和JDK1.8。整体架构如图3所示。
对于数据源管理模块,需要完成数据源录入和检测联通的功能。通过JDBC连接的方式,探测连接情况。JDBC连接是在Java程序与数据库系统之间建立了一条通信的渠道,并为各种数据库提供了连接数据库的规范。JDBC应用步骤如图4所示。平台中实现JDBC连接基类,提供JDBC驱动、数据库连接等抽象方法,对MySQL、Oracle、SQL Server等常用数据库实现连接子类,可直接通过url、账户名、密码等配置获取数据库内容,读取对应数据表结构和存储内容。当存在小众数据库连接需求时,可实现基类,自定义数据库连接、数据库驱动和读取数据方式等。
对于集成任务设计模块,用户可自定义编排数据集成任务,步骤包括选择数据源、选择源数据表和字段、选择目的数据源、选择目的数据表和字段、增加转换逻辑等,自动生成调用datax任务所需的JSON文件,并存至数据库。平台以依赖的形式引入data-common和data-core包,集成DataX执行器,用于执行DataX任务。并在需要调用数据集成任务时,执行Engine.entry(params),其中params用于配置必要参数,包括,任务job、任务模式mode、任务编号jobID等。另外,也可以增加动态参数,设定任务执行中用户自定义的参数内容和转换逻辑;通过Communication类,收集每次job运行之后的日志信息,并存储到日志表中,另外,对于异常运行的任务,应立即执行对应告警配置,通知到运维人员和任务开发人员。整体实现如图5所示。