基于Selenium的网站自动登录技术
作者: 卢守东 卢明俊
摘要:网络爬虫的应用十分广泛,其所要完成的任务与所要处理的网站往往差异巨大。针对某些网络爬虫所需要的自动登录功能,介绍一种基于Selenium的解决方案,并通过具体的实例说明有关的编程技术。
关键词:网络爬虫;自动登录;Selenium;Python
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2023)34-0048-04
开放科学(资源服务)标识码(OSID)
0 引言
目前,网络爬虫方兴未艾,其主要用途就是按照一定的规则从万维网中自动地抓取所需要的有关数据或信息[1]。然后,有些网站出于安全方面或其他因素的考虑,要求登录成功后方可执行相应的功能或访问相应的页面。显然,对于此类网站,作为网络爬虫,就必须具备相应的自动登录功能。在此,将以Windows为系统平台,以Python为编程语言,介绍基于Selenium的网站自动登录技术,供大家参考。
1 Selenium简介
Selenium是一个完全开源的Web自动化工具,主要用于Web应用程序的自动化测试[2]。Selenium测试直接运行在浏览器中,可完全模拟用户的实际操作。与其他测试工具相比,Selenium具有优异的跨平台性与兼容性,可运行于Windows、Linux、Macintosh等系统平台,并支持IE、Chrome、Firefox、Safari、Opera、Edge等浏览器。
在Python中,可借助Selenium库与相应的浏览器驱动,模拟用户在浏览器中的操作,从而实现自动登录功能。在此基础上,可进一步获取有关网页的源代码,并实现网络爬虫的具体功能。
2 关键技术
2.1 Selenium与浏览器驱动的安装
在Python中,Selenium是一个第三方库,必须另行安装,方法之一就是执行命令“pip install selenium -i https://pypi.tuna.tsinghua.edu.cn/simple”[3]。作为应用实例的开发环境,在此为Python 3.8.18安装了Selenium 4.13.0。
Selenium库安装成功后,还要安装相应的浏览器驱动。各浏览器的驱动是互不相同的,须从各自的地址分别下载。以Chrome浏览器为例,可从地址“https://chromedriver.storage.googleapis.com/index.html”下载与其版本相对应的驱动chromedriver.exe,然后并将其复制到Python的安装目录中[4]。
2.2 浏览器的启动与网页的访问
先从Selenium库导入webdriver模块,再调用该模块的Chrome()函数即可启动Chrome浏览器,并返回相应的浏览器对象。接着,通过浏览器对象调用get()方法,即可根据指定的网址访问相应的网页。为获取当前页面的源代码,可访问浏览器对象的page_source属性。若调用浏览器对象的refresh()或save_screenshot()方法,可刷新当前页面或为当前页面拍照(保存为指定的.png图片)。若调用浏览器对象的maximize_window()或minimize_window()方法,可最大化或最小化浏览器窗口。若调用浏览器对象的close()或quit()方法,则可关闭当前页面或退出浏览器。例如:
from selenium import webdriver
browser=webdriver.Chrome() #启动Chrome浏览器
browser.maximize_window() #最大化浏览器窗口
browser.get('https://www.cctv.com') #访问央视网主页
browser.save_screenshot('cctv.png') #为页面拍照
print(browser.page_source) #打印页面源代码
browser.quit() #退出浏览器
2.3 页面元素的查找与获取
在selenium.webdriver.common.by模块的支持下,通过调用浏览器对象的find_element()或find_elements()方法,可根据元素的ID、Name、CSS类名、Xpath路径、标签名、链接文本等在页面中查找元素,并返回相应的元素对象或元素对象列表。
2.4 页面元素的交互操作
对于所获取到的页面元素对象,可进一步调用其交互方法,执行相应的交互操作。例如,对于文本框对象,可调用send_keys()方法模拟从键盘向其输入指定的内容,或在elenium.webdriver.common.keys模块的支持下模拟输入指定的键盘按键;对于按钮、超链接等对象,可调用click()方法模拟在其上的执行单击操作。
例如,若页面的表单中有一个文本框与一个提交按钮,其id分别为cxtj与ok,为自动在文件框中输入selenium并单击提交按钮,则关键代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
browser=webdriver.Chrome()
……
cxtj=browser.find_element(By.ID,'cxtj')
cxtj.send_keys('selenium')
ok=browser.find_element(By.ID,'ok')
ok.click()
……
2.5 等待的设置
页面中某些元素的加载可能需要较长的时间,因此适当的等待有时候是必要的。Selenium支持两种等待方式,即隐式等待与显式等待[5]。隐式等待可设定一个最长的等待时间,在此时间内,会以轮询的方式不断地查找指定的元素,直至找到为止。若超过设定的等待时间依然未能找到指定的元素,则会抛出NoSuchElementException异常。显式等待同样可以设定一个最长的等待时间,但同时要指定相应的检测条件(如指定元素是否出现或可见等)。在此时间内,会以一定的时间间隔进行检测,直至符合条件为止。若超过设定的等待时间依然未能满足指定的条件,则会抛出TimeoutException异常。
隐式等待是全局性的,且用法较为简单,只需调用浏览器对象的implicitly_wait()方法直接设置等待时间(以秒为单位)即可。显式等待则较为灵活,但用法较为复杂,须先调用selenium.webdriver.support.ui模块的WebDriverWait()函数根据指定的浏览器对象与等待时间(以秒为单位)等参数创建一个等待对象,然后再调用等待对象的until()或 until_not()方法设置相应检测条件。至于具体的检测条件,可通过调用selenium.webdriver.support.expected_conditions模块的有关函数加以指定。例如,调用presence_of_element_located()函数可判断指定的元素是否已加载到页面的DOM树中,而调用element_to_be_clickable()函数则可判断指定的元素是否可点击。
例如,为确保id为cxtj元素已被成功加载,可采用显式等待,关键代码如下(最长等待时间为10秒):
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_ conditions as EC
browser=webdriver.Chrome()
……
wait=WebDriverWait(browser,10)
wait.until(EC.presence_of_element_located((By.ID,'cxtj')))
……
2.6 框架的切换
有些页面中会包含有一些框架(Frame/IFrame) ,从而嵌入了另外的页面。由于Selenium每次只能操作一个页面中的元素,因此要访问框架中嵌入页面的元素,就必须先切换至相应的框架。为此,只需调用浏览器对象switch_to属性的frame()方法即可。例如,为切换至name属性值为login的iframe框架,代码如下:
login=browser.find_element(By.NAME,'login')
browser.switch_to.frame(login)
切换至框架后,便无法继续操作主文档中的元素。此时,若要返回到主文档,可调用浏览器对象switch_to属性的default_content()方法。
2.7 Cookies的处理
Selenium为Cookies的处理提供了全面的支持,通过调用浏览器对象的add_cookie()方法,即可根据名称与值添加指定的Cookie。此外,调用get_cookie()或delete_cookie()方法可根据名称获取或删除指定的Cookie,调用get_cookies()或delete_all_cookies()方法可获取或删除所有的Cookie。例如:
browser.add_cookie({'name':'username','value':'admin'})
browser.add_cookie({'name':'password','value':'12345'})
在此,添加了两个Cookie,其名称分别为username与password,值则分别为admin与12345。
3 应用实例
3.1 自动登录豆瓣网站并进行查询
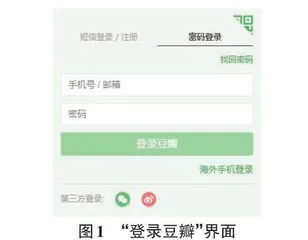
豆瓣网站的网址为https://www.douban.com。在浏览器中打开豆瓣网站的主页,并借助开发者工具进行分析,可知其中的登录界面(如图1所示)其实是嵌入到Iframe框架的一个页面,相应的Iframe元素为:
<iframe style="height: 300px; width: 300px;" frameborder="0" ></iframe>
其Xpath路径为“//*[@id="anony-reg-new"]/div/div[1]/iframe”。
登录界面中有“短信登录/注册”与“密码登录”两个标签,后者所对应的元素为:
<li class="account-tab-account on">密码登录</li>