一种基于时间帧差的行为识别方法
作者: 张颖 李英杰
摘要:视频中人类行为的跟踪和识别是计算机视觉的重要任务。视频中特征提取和建模是识别行为的关键问题。研究基于时间帧差的特征提取方法和行为识别的方法。首先,对相邻视频帧计算帧差图像,再计算帧差图像的光流,形成帧差序列和光流序列;然后,从帧差序列和光流序列中提取一组特征;最后,利用隐马尔可夫模型进行建模和识别。方法在Weizmann数据库和KTH数据库上分别获得了97.2%和85%的识别精度,验证了提出特征的性能,并验证了时间帧差图像对行为识别的有效性。另外,通过对一些特殊动作视频的测试,验证了提出方法的鲁棒性。
关键词:时间帧差;人类行为;光流;隐马尔可夫模型
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2023)35-0033-05
开放科学(资源服务)标识码(OSID)
0 引言
视频中人类的行为分析是计算机视觉的一个重要领域,有很多潜在应用,例如智能监控、无人驾驶、基于内容的视频检索和智能建筑等[1]。构建一个像人类一样,在复杂场景中具有无与伦比的识别能力,的系统,是人工智能的梦想。
传统的行为识别方法,大多数研究都集中在特征提取和描述上,例如:时空兴趣点、外观特征、光流等。近年来,随着深度学习技术研究的不断深入,其技术在视频中人的行为识别方面的研究层出不穷。包括卷积神经网络、递归神经网络等均可应用在行为的建模中[2-3]。当然,传统的行为识别方法的研究仍在深入进行,并且,传统方法与基于深度学习的方法也有互相补充和融合的趋势。传统的视频中人的行为识别方法通常分为几个过程,包括特征提取、行为建模和行为识别。本文基于传统方法,重点研究在视频中适宜行为识别的特征。
视频是识别的数据来源。当摄像头固定时,通过不同时间帧的差获得的帧差图像可用于表示运动的差,而不是整个身体的运动。帧差图像中许多特征细节(如颜色、纹理和体型)都会丢失[4]。另外,当物体停止移动时,它无法检测到物体。所以,帧差一般与其他特征相结合才可能较全面地描述运动。然而,本文研究表明,只基于帧差图像,能够获得足够的特征,以有效地识别行为。
1 方法与相关工作
1.1 方法
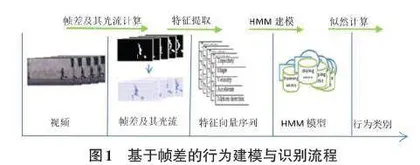
本文的研究结合帧差图像和帧差的光流提取特征,进行视频中行为的建模与识别,其具体的流程如图1所示。
首先,通过连续视频帧相减并设定阈值来获取帧差序列。每个帧差图像都是一个二值图像;之后,计算连续帧差图像的光流;再从帧差图像和光流图像中提取特征向量。提取的特征主要是外观特征和运动特征;之后,从特征向量序列中学习并建立每种行为的HMM模型。对于新的视频片段,通过前面的步骤获取其特征向量序列,并通计算与每类HMM模型的似然来识别其中的行为。
本文方法与已有的研究方法相比,有两个方面不同。首先,方法中所有特征都完全从时间帧差序列中提取;其次,从时间帧差序列及其光流中分别提取的特征进行组合,以提高行为表征的准确性和鲁棒性。
1.2 基于外观表征行为的方法
多年来,基于外观的特征在识别人类行为方面发挥着作用,而区域和轮廓是外观的直观表示[4]。通常,特征是从前景区域或轮廓中提取的,并表示为每个帧的姿势[4]。
Hota 等人在监控视频中测试了有助于区分人与其他物体的特征[5]。其研究表明,许多基于外观的特征有助于识别人的形状,例如:胡不变矩、最小外接矩形(Minimum Bounding Rectangle,MBR)的高度与宽度比、填充率(MBR内前景点面积与MBR面积的比率)以及周长等。当然,基于外观的方法可能会受视点、遮挡、缩放和个体变化的影响[4-5]。
1.3 基于兴趣点的功能
空间兴趣点提供了图像中特殊点的紧凑和抽象表示,并且它们是比例不变的。它们能够在存在遮挡和动态背景的情况下实现检测事件[6-7]。Ivan Laptev等人基于Harris和Forstner的方法提出了新的兴趣点提取方法[7]。
1.4 光流计算
光流表达两个图像之间的像素运动。两个图像通常是视频中两个连续帧。光流以流表示第一张图像中每一个像素映射到第二张图像中对应的像素的位移。Horn和Schunck提出了光流的计算方法,其假设像素灰度值在连续帧之间变化最小,并使用全局平滑[8]。然而,在运动边界、平滑区域或者大位移运动过程的光流计算会出现模糊和残留问题。因此,一些新方法和改进方法被提出。例如,对于人体运动问题,由于人体是多关节体和非刚性的,可能会产生较大的位移。Lu和Liu使用哈里斯点来补偿变分光流场[9]。基于块匹配的方法也是一种可以处理大位移的匹配方法[10]。
1.5 HMM模型
马尔可夫链(Markov chain)是一种随机过程,该过程由有限历史约束的状态组成。这意味下一状态的概率分布只由当前状态决定,在时间序列中,再前面的事件均与下一状态无关。隐马尔可夫模型(Hidden Markov Model, HMM)是一种统计模型,其中假设正在建模的系统是具有隐藏状态的马尔可夫过程。虽然人类行为并不严格符合有限历史状态约束,但许多研究表明,HMM可以正确模拟人类行为[11]。
HMM模型由5元组指定:μ=(S,Q,∏,A,B),其中S和Q分别是状态和观测值的集合[12]。∏是原始状态概率的集合。A 是表示状态之间转移概率的矩阵。B是一个矩阵,表示从状态到观测值的传递概率。当观测序列具有相同的行为标签时,可以通过最大化概率 P(Q|μ)来训练模型μ。不同行为的模型,表示为 {μ1,μ2,...,μi,...},可以使用相应的观测值进行训练。使用不带标签的观测值,可以计算最大似然将其分类。基于从视频中获取的特征向量序列,HMM训练和识别流程如图2所示。
2 时间帧差和帧差的光流计算
2.1 Weizman行为数据库
Weizman行为数据库,是一个经典的人的行为识别的视频数据库[13]。数据库中的视频有十种行为,分别是:bending, jumping jack, jumping, jumping in place (pjump), running, jumping sideways, skipping, walking, one hand waving (wave1), and two hands waving (wave2)。每个行为分别有由10个人表演的视频段。视频帧速度为25帧/秒,每帧144*188像素。视频是用固定摄像机拍摄的。数据库中提供了每个视频的确切背景图像,因此可以方便地使用背景减法来获取完整的前景图像。以下叙述中的实验数据来源于此数据库中的视频。
2.2 时间帧差
通过在包含运动对象的视频中的两个相邻帧之间相减,会在差的图像中获得两组点。一组点值为正,另一组点值为负。经过阈值估计过程后,它们被投影到时差图像中的两条边。如果只使用一组中的点,例如,只保留具有正值的点,则将得到半时差图像。如果使用二组点将获得全差分图像。为了感知前景图像、时间帧差图像和半时差图像之间的差异,图3显示了一些样本。
在图3中,时间帧差图像中检测到动作时刻运动部分的近似轮廓,不动的部分丢失了。半帧差图像保留了大约一半的运动轮廓,丢失了更多的运动信息。但是,后面将验证,在半时间帧差序列中仍然包含识别行为的有效信息,并且可以简化光流的计算。因此,半时间帧差序列将作为本文工作的基础。下文中,为叙述简洁,“半时间帧差”将简称为“时间帧差”,不再强调“半”。
2.3 帧差的光流计算
欲计算时间帧差序列的光流,前述的光流计算方法可能存在局限性,可能的原因如下:
1)时间帧差图像是二值的。任何前景区域点和任何背景区域点之间的灰度值都是相同的。无论是通过变分方法还是基于块的方法,这两个区域都可能引入不正确的匹配。
2)通过全局平滑,即使涉及各向异性惩罚,运动边缘也会严重模糊。
3)时间帧差的前景范围小于序列图像中的前景范围,并且时间帧差序列中没有背景运动问题。
所以,光流计算可以简化。因此,提出了一种新的方法来估计相邻时间帧差图像之间的光流。它描述如下:
1)通过两个质心的位移在前景区域中建立非常原始的流动。
2)将第一个图像和第二个图像划分为大小相同的网格,例如 9×9 网格。计算相应网格质心的前景位移,并通过其位移修改每个网格中的原始流。但是,零位移网格中的原始流被保留。在此过程中忽略所有背景点的流。
3)计算每个图像的哈里斯角,匹配角点,并修改匹配点的流。哈里斯角点由一阶曲率估计,并且对尺度和仿射变换不变[14]。一些在前一个步骤中无法反映的拐角运动预计将通过此步骤进行调整。
4)在前景中平滑。
图4中,第2行显示的是用传统方法计算出的帧差的光流,可以看到其中方向和边缘模糊。第3行显示的是新方法计算得到的光流。可以看到,大多数流向量的方向和速度都正确,边缘没有模糊。
3 特征向量提取
为了减少缩放的影响,即从相机到物体的距离变化,引入了最小正接矩形(Upgrade Minimum Bounding Rectangle,UMBR)。UMBR 是一个包含所有前景点的框,并且与坐标垂直。引入UMBR,是假设拍摄视频的摄像机与地面垂直。
参考人类对行为的感知,从时间帧差和相应的光流场中定义了几个统计特征,用于表征行为。提取出的特征用符号M=(m1, m2, ..., mk)表示。下标 1, 2, ..., k,仅用于特征索引,特征顺序无关紧要。光流场表示为U,其中的矢量表示为(u,v)。
3.1 四个方向的速度特征
光流表征的是前景中每个点的运动方向和速度。人类可以感知运动总量和细节。虽然捕获所有细节可以更准确地表示动作,但计算更复杂,并且可能对噪声点更敏感。因此,本文的方法只计算运动总量。首先将速度方向分为四个,如图5(1)所示。从一个光流场U中,计算四个方向的总速度的和,如公式(1)。再获取光流场中所有前景点的UMBR。之后,将四个方向的总速度除以UMBR的对角线长度以进行标准化。这样,对于一个光流场,产生了前4个特征,就是m1~m4。
V1,2,3,4 =SUM(u+, u-, v+, v-) (1)
3.2 运动方向分布特征
人类身体不同部分的运动方向分布可以表示不同的动作。增加身体每个部位的运动方向分布特征可以增强动作识别的效果。但分割身体部位可能只在特定的场景中才能完成。从时间帧差图像中分割身体部位更加困难。此外,收集所有方向的统计分布很复杂,也会产生高维数据。本文方法中把方向分为八个,如图5(b)所示,每个方向是一个扇区。在一个光流场U中,计算八方向直方图以指示运动方向分布,计算如公式(2)。再计算U的前景面积。之后,用八方向向量的点个数除以前景面积,进行标准化。这样,对于一个光流场,获取了另外8个特征,就是m5~m12。
[dk=count(u,v)∈sectionk(u,v)] (2)
到目前为止,基于一幅帧差的光流场获得了12个特征,是m1~m12。那么,从一段视频中可以获得一组,具有12个特征的矢量序列。这个序列表征的是运动特征。
3.3 基于外观的特征
为了进一步增强行为特征的可区分性,引入了一些外观特征,这些特征将来源于帧差图像的前景。Gupta等提出了一种用于表示闭合形状的描述符如图6(a)所示。其方法中以质心与形状的所有轮廓像素点之间的欧氏距离的序列来表示形状[15]。为了避免数据维数过大,将方向划分了8区间,如图6的(b)所示。其中坐标表示为(col,row),原点设置为前景区域的质心。对每个区间,采集质心与轮廓像素之间的最远距离。之后,将距离除以UMBR的对角线长度进行标准化,得到m13~m20 。利用这些特征,可以粗略地表征身体部位的延伸和缩进。需要说明的是,图9中使用完整的前景图像作为示例图像,以清楚地表达描述符的概念。本文工作中,提取m13~m20时是取之于帧差图像。帧差图像是二值图像,其中前景区块可能有不连续问题。在计算质心、面积和UMBR时,所有前景点将视为一个区域。