基于冬奥会新闻的命名实体识别及可视化
作者: 王子豪
摘要:随着2022年冬奥会的到来,冬奥会新闻数据急剧增加。从冬奥会新闻数据中提取实体并进行可视化,对研究冬奥会进度具有重要作用。针对冬奥会新闻数据实体识别问题,提出基于BERT-BiLSTM-CRF命名实体识别模型。根据实体识别结果,从时间和空间两方面分析冬奥会新闻文本数据,可视化地展示此次冬奥会的相关信息。在时间维度,通过在新闻中提取的时间日期制作日历图,以时间作为支撑了解不同时间节点的事件频率。在空间维度,通过对新闻文本中地点的提取进行地理统计分析,直观地了解新闻事件的空间分布。
关键词:冬奥会新闻;网络爬虫;命名实体识别;可视化;地理统计分析
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2022)07-0085-04
1 概述
北京冬奥会作为中国第一次举办的冬奥会,一直深受社会广泛关注。冬奥会新闻持续时间长,可获取的新闻文本多。新闻的写作特点是描述事件,其中会包含大量时间、地点等描述时间特征以及空间特征的要素[1],因此识别新闻数据中的关键因素对研究2022年冬奥会发展过程具有重要意义。
命名实体识别通常认为是从一段非结构化文本中识别出实体信息。识别实体的过程中,首先人为划分边界确定实体的范围,再将实体分配到空间类型或时间类型中[2]。近年来,深度学习在命名实体识别领域的应用越来越广泛,使用预训练词向量技术替代人工提取特征,可以提高工作效率。王传涛等人[3]通过BERT对简历信息进行字符集编码,得到基于上下文信息的字向量,通过双向长短时记忆网络对生成的字向量进行特征提取,将所有可能的标签序列打分输出给条件随机场,最后通过CRF进行解码生成实体标签。文献[4]根据生物领域文本的实体数量种类多、边界划分难、实体表述方法多和存在缩写、特殊字符等文本特性,提出了基于CNN-BiLSTM-CRF命名实体识别模型,准确率得到了提升。Word2Vec、GloVe模型受限于特征表示方法,不能解决一词多义问题,文献[5]提出基于Transformer的双向编码器表示方法,该方法通过使用深度双向表示预训练模型,进而获取深层次的文本语义信息,在命名实体识别领域中取得了良好的效果。文献[6]针对传统预训练模型特征提取能力不足且不充分的问题,提出基于BERT的中文命名实体识别方法,通过BERT提取文本特征,结合BiLSTM提取文本全局和局部特征,该方法提高了命名实体识别的整体效果。文献[7]根据军事文本领域文本中实体集中,边界明显等特征,提出了一种多级神经网络协作的军事领域实体识别模型,该模型使用BERT模型对字级别进行特征表示,使用BiLSTM层获取文本的上下文特征,最后CRF层根据相邻标签关系得到最优标记序列,该模型相较于其他模型,性能得到了明显提升。
以冬奥会数据作为采集与分析的实验背景,将新闻文本中的时间要素与空间要素进行命名实体识别,根据标注结果形成可视化分析,分析新闻事件的发展脉络。丁杰等人[8]通过关键词搜索网络新闻将新闻事件聚类,整理出事件的发生过程的“时间线”,并且能对事件后续的发展进行跟踪,让管理者通过阅读“时间”更快且完整地掌握事件全貌。刘海砚等人[9]利用自然语言处理技术对新闻文本数据进行分词和主题建模,提取事件时空和语义信息,采用日历图和流地图的可视化方法,形成多维事件可视化系统,帮助人们快速获取海量新闻文本中感兴趣的信息。
本文根据以上研究,提出BERT-BiLSTM-CRF命名实体识别模型,将命名实体识别模型与可视化进行结合,通过命名实体识别模型提取冬奥会新闻中的时间实体和空间实体,并将识别结果进行可视化。以此研究冬奥会进展情况。
2 研究方法与手段
2.1 方法流程
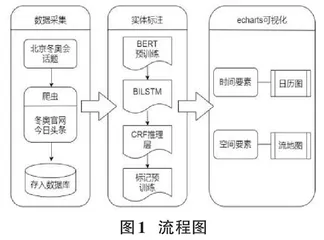
本文围绕“2022年冬奥会”话题对今日头条和冬奥会官网新闻进行抓取并保存,使用人民日报语料库训练BERT-BiLSTM-CRF的模型,使用该模型对2022年冬奥会的新闻数据进行命名实体识别,对识别的信息进行规范化处理。最后借助ECharts可视化工具将最终结果以图表的形式进行展示。通过时间和空间的分布数据与新闻报道相结合,了解冬奥会在不同时间和空间的进展情况。本文方法流程如图1所示。
2.2 数据采集
2.2.1 数据获取
数据来源主要是冬奥会官网和今日头条。冬奥会官网作为官方平台,在第一时间发布冬奥会的相关消息,而今日头条已经成为人们生活中重要的信息来源,也是一个使得人与信息得以连接的平台,该平台让有用的信息得到高效精准的分发,促使信息创造价值,并且数据开放程度较高,信息发布较为丰富,其中包含着大量的冬奥会新闻信息。使用Python搭建冬奥会新闻爬虫框架进行数据抓取。由于今日头条通过AJAX加载数据,因此需要浏览器审查元素解析真实地址,然后将数据存储到MongoDB数据库。
2.2.2 数据存储
Redis支持多种数据结构,但是Redis在string类型上会消耗较多内存。研究采用MongoDB进行数据存储,MongoDB不仅是一种分布式数据库,也是一种持久化的数据库。
2.3 基本框架
采用BERT-BiLSTM-CRF命名实体识别模型对冬奥会新闻中的时间、空间等进行命名实体识别。BERT层负责进行字级别的特征表示,BilSTM层负责获取文本的全局和局部特征,CRF层根据文本特征获取全局最优标注结果,框架结构如图2所示。
2.3.1 BERT层
BERT预训练语言模型与Word2vec[10]模型相比,在处理歧义词上的识别效果有了很大提升。例如为了纪念孙中山先生,将香山县改为中山市,会产生人名与地名的歧义。“白云”一词,可以作为广州的白云区表示地名,也可以被理解为天上的“白云”,由于word2vec静态进行词向量表示,在该模型中这类词被作为同一个向量进行表示。BERT是一种新的词向量表示方法,使用预训练语言加入Transformers[11]双向训练注意力机制,应用到语言模型当中,能够根据上下文文本特征动态进行词向量表示,进而解决了一词多义的问题。
2.3.2 BiLSTM层
BiLSTM是由向前的LSTM和向后的LSTM组合而成。LSTM一种长短期记忆门控RNN,是当下最流行的RNN形式之一。为了解决RNN梯度爆炸的问题,LSTM多了输入门、输出门和遗忘门三个控制器。遗忘门作用在线性自环的位置,而普通的RNN是没有线性自环的。
LSTM[12]以当前的输入和前一状态的传递为输入,遗忘门[ft]确定上一阶段单元状态是否被保留,[ft]值越大,则上一单元状态被保留得越多,当[ft]值为1时,则上一阶段单元状态被全部保留下来,当[ft]值为0 时,则上一阶段单元状态被全部舍弃;输入门[it]确定当前信息是否被更新到单元状态中;输出门[ot]确定用于控制细胞状态值的输出,三个门的结构如下:
其中:[ft]、[it]、[ot]分别为遗忘门、输入门、输出门;W代表权重矩阵,[b]代表偏置变量,[ct]代表当前细胞状态。
单向LSTM对比双向LSTM存在很大的局限性。单向LSTM无法联系上下文语义,如“中国”一词,输入“国”字时,可能“中”和“国”会被拆分开。双向LSTM通过正向和反向两个方式对文本序列进行语义捕捉,能够更好地获取上下文关系信息。
2.3.3 CRF层
CRF[13]是一种基于统计的数据分割和序列标注过程。CRF层能够考虑相邻标签序列的关系,进而获取全局信息,以此得到全局最优的标记序列。设[Xn](n=1、2…)和[Ym](m=1、2…)是联合随机变量,若随机变量Y构成马尔可夫网络表示为[G=(V,E)],则[P=(Y|X)]为条件概率分布,称为CRF(条件随机场),即:
式中:[ω~v]表示无向图[G=(V,E)]中所有与节点[v]存在边连接的所有节点,[ω≠v]表示除节点[v]以外的其他节点。CRF由转移函数和状态函数构成。在标注序列中,转移函数需要当前位置[i]和前一个位置[i-1]的标记,表示将标记[yi-1]转移到标记[yi]的概率。CRF的参数化形式为:
式中:[T(yi-1,yi,i)]和[S(yi,x,i)]为转移函数,[λi]和[uj]为对应权值,[Z(x)]为规范化因子。CRF在实体识别中的应用是为求出[argymaxp(x|y)]。
2.3.4 训练数据标注
新闻文本中会出现时空信息表达不规范的情况,如将“8月10日”表示为“8.10”,也可能会出现“地名脱落现象”,这些情况不利于时空信息的识别,需要对识别的信息进行规范化处理。
采用BIO的标注方法对训练数据进行标注,对新闻数据中的时间和空间进行标注。在空间的首字后面标注B-LOC,地名的非首字后面标注I-LOC,对时间等同样进行标注,其他字后面标注O。
3 研究结果
3.1 模型训练
本文使用Tensorflow搭建命名实体识别模型。实验参数设置如下:输入维度为128,训练集的批次为64,训练学习率为[2×10-5],为了出现梯度爆炸,使用dropout来防止过拟合,值设置为0.5。
本文使用人民日报语料库进行训练BERT-BiLSTM-CRF命名实体识别模型。人民日报语料库已经放好词,标注了人名、地名等信息,使用了BIO标记方式标注语料。经过人民日报语料库的训练,该模型的分类准确率达到了95.2%,其中TIME,LOC标注的准确率分别达到了95.5%、95.2%。
3.2 时序关系可视化
本文将实体识别模型标注的时间进行提取,并将提取的时间实体规范化处理。使用ECharts可视化工具绘制日历图。日历图中点颜色的深浅表示频率的大小,颜色越深意味着这个日期在新闻文本中出现的频率越高。频率越高表明该日期在冬奥会进展中越重要。
如图4所示,2019年5月10日和2021年2月4日,这两个时间节点被提到的频率很高。2019年5月10日是北京冬奥会倒计时1000天,2021年2月4日是北京冬奥会倒计时一周年。2022年2月4日和3月4日这两天出现的频率也很高,这两天分别是冬奥会和冬季残奥会的开幕时间。这些日期在冬奥会进展中具有比较重要的纪念价值,表明社会对冬奥会的关键节点最关注。
通过日历图,可以非常直观地看到,在冬奥会的筹办过程中具有重要意义的时间节点。
3.3 空间关系可视化
3.3.1 国内地理统计分析
通过绘制流地图描述事件的空间位置和空间关系,以点来表示新闻文本中提及的地区位置,以线来表示两地区之间有着联系。
如图5所示,国内的省份地区与冬奥会三大赛区的关系较为紧密。例如河北省科技冬奥专项“冬奥会张家口赛区赛事专项气象预报关键技术”,通过实体识别标注出的地名“河北省”“张家口”,然后将两个地区通过线进行连接。由于国内资源分配不均匀,因此在建设冬奥会场馆时,需要多个地区的支持。为了更好地宣传冬奥会,需要面向全社会举办相应的活动。
3.3.2 国外地理统计分析
通过实体识别模型将新闻文本中提到的国家进行标注,将标注的地点与中国进行连接。
如图6所示,国际上其他国家与冬奥会联系密切。由此可知,国际上的其他国家对北京冬奥会也较为关注,其中欧洲国家较多。例如在冬奥会倒计时一周年时,新闻中报道了希腊、日本、法国、意大利、美国、澳大利亚、尼日利亚等国家通过视频接受参加北京冬奥会的邀请。
4 结论
本研究使用网络爬虫对冬奥官网以及今日头条的冬奥会相关新闻进行抓取,将数据存储到分布式数据库MongoDB中,使用BERT-BiLSTM-CRF将新闻文本中的时间、空间实体进行标注,绘制出图标与社会状况相印证。运用日历图和流地图对新闻文本的时间要素和空间要素进行可视化展示,从宏观上掌握了2022年北京冬奥会的时序发展演变情况。直观地展示冬奥会的发展情况、国内外的地理统计分析等信息,能够帮助相关工作人员更好地阅读以及理解2022年冬奥会新闻文本,并对冬奥会发展过程或其他新闻事件发展过程的研究与分析起到辅助作用。