基于卷积神经网络的离线笔迹鉴别系统
作者: 季明涛 梁大伟 戴宏康 傅明明
摘要:笔迹鉴别方法,主要通过对比分析手写字符的统计学特征、纹理特征、结构特征等来辨别书写者的身份。传统的笔迹鉴别对专家经验、从业年限等有较高要求,效率较差。现在计算机人工智能技术的发展,为笔迹鉴别提供了一个新的方向。设计的系统使用web技术构建系统前端,利用多层卷积神经网络和全局平均池化构建后端笔迹鉴别模型,在CASIA-HWDB标准中文数据集上进行训练、验证和测试。测试结果表明,在10人的笔迹样本模型中,识别准确率达100%。
关键词:卷积神经网络;笔迹鉴别;准确率;预处理;软件开发
中图分类号:TP391.52 文献标识码:A
文章编号:1009-3044(2022)15-0075-04
1 引言
随着我国法治建设不断深入,笔迹鉴别作为一种重要的刑事科学技术在司法鉴定领域的重要性日益突出。传统的笔迹鉴别完全依靠人工眼力识别,存在困难程度高、准确率低、时效性差等缺点。21世纪初期,国内外的L. Schomaker[1]、何震宇、尤新革[2]、Fiel[3]等人先后利用计算机视觉技术、图像处理技术、深度学习等提高笔迹鉴别的准确率。尤其是Fiel等人利用卷积神经网络(Convolutional Neural Network, CNN)提高了笔迹鉴别的准确率,证明了CNN在笔迹鉴别上的优势。本文将着眼于利用CNN对汉字笔迹的纹理、字形和笔画等特征准确识别并提取,构建CNN离线笔迹鉴别模型,通过广泛收集笔迹数据进行CNN网络训练和测试,验证模型用于离线笔迹鉴别的有效性。此外,利用web网页作为模型载体,设计UI界面,便于用户操作,实现不依赖于文本内容的自动化笔迹鉴别。该系统可用于司法、考古等领域。
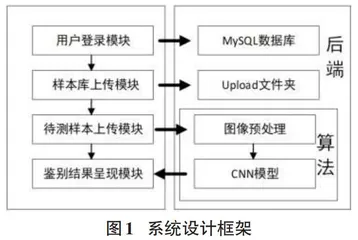
2 系统设计框架
如图1,本系统主要分为前后两端,前端主要用于上传样本和呈现结果,后端用于存储数据和算法。其中算法是整个系统的核心,分为图像预处理和CNN模型两部分。
3 图像预处理
图像预处理的目的是使模型更准确地识别笔迹特征,提高笔迹鉴别准确率。该工作主要包括两方面,一方面是消除影响鉴别准确率的因素,如纸张固有背景线、残余墨迹等;另一方面是为提高鉴别准确率创造条件,如字符切割。以图2为例,分析图像预处理过程。
3.1 消除影响鉴别准确率的因素
消除影响鉴别准确率的因素的操作主要有去背景线、灰度化和二值化。去背景线是利用计算机的取色器提取纸张背景线的信息,再通过调色板将背景线去除[4]。图像灰度化是对去除背景线的图像使用加权平均法,得到最合理的灰度图像[5]。最后,根据图像的灰度直方图求出最佳阈值,将大于阈值的像素点的值设置为255,作为背景像素,小于最佳阈值的像素点的值设置为0,作为字体像素。对图2进行操作,图3为经过消除影响图片鉴别准确率的因素的结果,图片尺寸为769×1019。
3.2 字符分割
该文章提出的笔迹鉴别方法不是依赖于文本内容,而是依靠笔迹特征鉴别样本的书写者。并且经实验表明,单个字符比整个笔迹页面图像输入模型更有利于提取笔迹特征,所以本文的图像预处理包括字符切割。本文的字符切割共分为两步:行切割和块切割。
1)行分割
行分割采取等距滑动窗口的方法,首先设定分割后最小方块的边长,即分割后每行的高度。以图3的图像高度除以边长得到不重复分割的结果行数。但是从图2中看出,并不是每行字都在一条直线上,所以为了充分提取笔迹特征,将不重复分割的行数,但多分割的行是与原来的行有重叠内容,如图4,每行高80。
2)块分割
块分割采用随机滑动窗口法。首先设置自变量[factor]值,设[factor=0.1],将行宽[×factor]取整得到分割数量101,而每个方块的边长为80,只需13个方块即可分割完所有内容。设置自定义因子[factor]扩大分割数量可重复提取每个汉字的每一个特征,采用随机滑动窗口法还可提高每行两端特征被提取次数,提高识别准确率。图5为块分割后整幅图像的部分情况。
4 模型构建
CNN主要由卷积层、池化层、全连接层这三个部分组成。由这三部分搭建的体系结构决定其适合高维问题[6],尤其是在图像分类、图像语义分割、图像目标检测等方面具有优势[7]。这正好满足笔迹鉴别对样本图像处理、提取笔迹特征的需要。图6是本文构建的CNN模型的结构。
4.1 卷积层
卷积层的主要功能是通过卷积核采用滑动窗口机制逐步扫描输入的图像,从而提取图像特征。从图像的第一列第一行像素点开始,将卷积核的权重值与图像上对应的像素值点乘后累加,并将结果作为输出特征图相应位置的值,然后按照从左到右从上到下的顺序完成整个图像的卷积操作得到卷积层(如图7[8])。
4.2池化层
池化层也被称为下采样层,卷积层是其输入层,在对图像进行特征降维和特征提取起到重要作用。常见的池化方法有两种,分别是最大池化和均值池化(如图8)。最大池化就是选取窗口中的最大值作为该区域池化后的值,均值池化是计算窗口内数值的平均值作为该区域池化后的值。该模型采用平均池化法。
4.3全连接层
CNN的结构中多个卷积层和池化层之后,连接着一个以上的全连接层,为了整合卷积层或者池化层中具有类别区分性的局部信息,将经过多轮卷积和池化后的二维特征图转化为一维特征向量,再采用softmax函数表示每个类别的概率值,起到分类作用。
4.4模型训练
基本模型框架已经搭建,为进一步完善模型,需要数据集对模型训练,以确定卷积核大小等参数。模型训练采用CASIA-HWDB标准中文数据集,在该数据集中取每位书写者的五份材料,三份作为训练集,一份作为验证集,一份作为测试集。
5 实验验证
为验证构建的CNN模型的有效性,实验选取10位书写者的笔迹作为测试集。将这10位书写者从0开始标号。
根据本文采取的字符切割方式,样本在切割前后共有三种形式,分别为页、行、块,页和行的预测结果都是以字符块的预测结果为基础。字符块的预测结果是通过模型提取特征比对得到与每位书写者笔迹的相似度,相似度高者判定为笔迹书写者。页和行的预测结果是统计其切割后字符块的预测结果,将每种结果出现的概率作为相似度,相似度高者为预测页和行的预测结果。
5.1块预测
字符块1(如图9)和字符块2(如图10)分别为书写者0和书写者3的笔迹,字符块1包含完整文字,字符块2包含每个字符的残余笔画。图11为字符块1和2的实验情况对比图,字符块1预测与书写者0的相似度最高,几乎为100%,判定为书写者0的笔迹,预测正确;字符块2预测与书写者7的相似度最高,认定字符块2为书写者7的笔迹,预测错误。综合分析所有字符块的预测结果得出块预测准确率约为68.63%。
5.2行预测
字符行1(如图12)和字符行2(如图13)分别为书写者6和书写者9的笔迹,字符行1完整切割一段文字,字符行2切割的是两行文字的间隔区域,每个字符都不完整。图14为字符行1和2的实验情况对比图,字符行1预测与书写者6的相似度最高为75.44%,判定为书写者6的笔迹,预测正确;字符行2预测与书写者3的相似度最高为33.85%,虽然与书写者7的相似度相差不大,但仍然判定为书写者3的笔迹,预测错误。综合分析所有字符行的预测结果得出行预测准确率约为90.65%。
5.3页预测
图15是书写者9的笔迹样本,对整个页面内容切割后的5208个字符块进行预测,预测情况如图16。
从图16的预测情况得出,5208个字符块中判定为书写者9的笔迹块数有1562块,与书写者9的相似度为30%,在所有书写者中相似度最高,可以判定该笔迹属于书写者9,实验结果正确。其余9位书写者的样本测试都正确,页预测准确率高达100%。
5.4结果分析
对于字符内容完整的字符块,模型能够正确预测,但由于块分割采用随机分割法,有些字符块字符内容不完整,包含笔迹特征较少,甚至没有笔迹特征,导致预测错误,但是实验结果表明字符块的预测准确率约为68.63%。结合行预测的准确率约为90.65%,页预测准确率高达100%的实验结果,可见68.63%的字符块预测准确率对整体页预测的结果影响不大,可以用于笔迹鉴别。
6系统设计与实现
6.1 功能介绍
系统基于web技术搭建,基于html、css、javascript设计出简易清晰的UI界面,将使用算法代码输入笔迹数据集的过程省去,为用户提供简洁明了的一站式窗口,使得非专业领域的用户也可根据网页指示操作,上传相应样本文件,从而向后端发送指令,使用笔迹鉴别算法处理数据并获得鉴别结果。系统共设计五个界面,分别为欢迎界面、登录界面、注册界面、样本库上传界面(如图17)、待测样本上传及结果呈现界面(如图18)。
6.2 模块设计
整个系统共有四个模块,分别为用户登录模块、样本库上传模块、待测样本上传模块和鉴别结果呈现模块。在用户登录模块,基于PHP使用ajax技术将用户信息记录到与MySQL数据库;在样本库上传模块,基于jQuery将输入压缩包文件上传到网站目录下的uploads文件夹;在待测样本上传模块,支持多种格式图片,并用Ajax技术对用户上传的文件进行判断是否符合要求;在鉴别结果呈现模块,与用Python编写的CNN模型算法相连,按照“样本名:准确率”的格式显示算法运行结果。
6.3 Web服务实现与模块测试
Web服务端选用本地主机,使用软件phpstudy启用Apache和MySQL服务,在浏览器网址中键入“localhost+文件根目录”即可访问网站。经测试,网站各模块功能均达到预期结果,笔迹鉴别网站可成功运行。
7 结束语
本文运用CNN构建笔迹鉴别模型,通过图像预处理和CASIA-HWDB中文数据集训练,提高模型的鉴别准确率。实验证明,该模型的样本预测准确率达100%,满足需求。此外,利用Web技术设计操作界面,搭建完整的笔迹鉴别系统,实现笔迹鉴别的自动化。
参考文献:
[1] Schomaker L,Bulacu M.Automatic writer identification using connected-component contours and edge-based features of uppercase Western script[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2004,26(6):787-798.
[2] He Z Y,You X G,Tang Y Y.Writer identification of Chinese handwriting documents using hidden Markov tree model[J].Pattern Recognition,2008,41(4):1295-1307.
[3] Fiel S,Sablatnig R.Writer identification and retrieval using a convolutional neural network[C]//Computer Analysis of Images and Patterns,2015:26-37.
[4] 何斌.Visual C++数字图像处理[M].2版.北京:人民邮电出版社,2002.
[5] 师宝山,张贵州.笔迹鉴别预处理算法的设计与实现[J].电子器件,2008,31(4):1357-1360.
[6] Altwaijry N,Al-Turaiki I.Arabic handwriting recognition system using convolutional neural network[J].Neural Computing and Applications,2021,33(7):2249-2261.
[7] Wu J.Introduction to convolutional neural networks[D].Nanjing:National Key Lab for Novel Software Technology,Nanjing University,2017.
[8] 王豪爽.基于深度学习的离线签名鉴定[D].成都:电子科技大学,2020.
【通联编辑:谢媛媛】