基于GAN的人体姿态生成研究综述
作者: 金海峰 武昭盟
摘要:人体姿态生成是指不改变源人体外观,生成参考人体姿态的技术。由于姿势转移过程中的身体变形和不同视角带来的不同外观, 其生成过程较为复杂。该技术可归纳为基于图像和基于视频两种途径,对于前者以人体建模的方式为依据,将其分为基于姿态关键点的人体姿态生成、基于外观流的人体姿态生成以及基于网格的人体姿态生成,并介绍了其中的典型模型,最后指出人体姿态生成中的问题,未来在模型优化、数据集构建等方面还需要更深入的研究。
关键词:人体姿态生成;关键点提取; 外观流; 图像生成; 视频生成
中图分类号:TP391.41 文献标识码:A
文章编号:1009-3044(2022)25-0001-04
开放科学(资源服务)标识码(OSID):
1 引言
给定一个源人体图像和一个参考人体图像,人体姿态生成是指利用给定的参考人体的姿态图来生成具有参考人体姿态、但保持源人体外观的技术。它属于计算机视觉生成领域,但因其姿态生成空间变换的复杂性,比一般的生成任务更具有挑战性。
人体姿态生成的研究比较新颖,Ma等人[1]在2017年提出了最早的人体姿态生成网络PG2,能够由源人物图像和参考姿势来生成具有参考姿势的源人物图像。人体姿态生成任务生成图像时需要推断出未观察到的身体部位,以便生成目标姿势。具有挑战性的是不同姿势的图像在不同视角下可能有很大的不同,这就不可避免地要求生成器捕捉图像分布所具有的巨大变化。这项任务对计算机视觉来说具有广泛的应用价值,比如视频合成和视频编辑,以及在没有足够的同人图像的情况下,对人的重识别[2]等问题进行数据扩充。
目前,人体姿态生成任务可以归纳为基于图像的姿态生成和基于视频的姿态生成。从这两方面出发,分析和总结了其中典型的算法和模型,按照不同的人体建模方式,将各类模型归类到基于姿态关键点的人体姿态生成、基于外观流的人体姿态生成和基于网格的人体姿态生成。在每个类别中,首先对模型进行了基本描述和概括,然后对该方法做了总结。此外,还介绍了人体姿态生成任务的常用数据集和评价指标,列举了部分典型模型的性能表现,最后对人体姿态生成面临的问题进行了说明以及对未来的研究方向做了展望。
2 基于图像的人体姿态生成
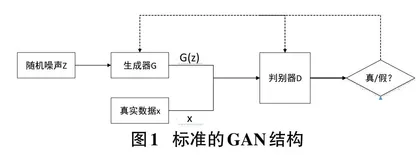
图像生成的目标是找到与真实图像最相似的分布,目前主流的生成模型是基于深度学习的变分自动编码器(Variational Autoencoder,VAE)[3]和生成式对抗网络(Generative Adversarial Network,GAN)[4]。由于GAN 网络在图像生成方面的优秀表现,近几年基于GAN模型的生成任务更为流行。最早的对抗生成网络由Goodfellow [3]提出,该网络由一个生成器G和一个判别器D组成,生成器负责让生成的图像更加真实,判别器负责判断出图像的真假,生成器和判别器进行对抗训练,并最终期望达到一个纳什均衡:生成器生成的图像越来越真实,而判别器越来越难判断出图像的真假,GAN的原理如图1所示。
此后各种优化的GAN 模型不断涌现,生成图像的质量也越来越高,但简单GAN模型训练不稳定,多样化受限。为此,Mirza提出了条件GAN[5],在生成器和判别器中引入条件变量,以指导符合特定要求的数据生成。在人体姿态生成任务中,参考人体姿态作为条件变量或语义标签,指引人体姿态的生成,而人体姿态使用人体姿态估计的方法获取。一般来说,人体姿态估计将人体模型分为三种[6]:基于骨骼的模型,基于轮廓的模型和基于体积的模型。(1)基于骨骼的模型:将人体拓扑表示为一组关键点位置及对应的肢体方向。这种模型由于操作简单,被大量用于2D和3D人体姿态估计中;(2)基于轮廓的模型:将肢体和躯干用矩形或轮廓边界表示;(3)基于体积的模型:一般以3D扫描的网格形式表示。
对于现有的人体姿态生成任务,以人体建模的方式为依据,可将人体姿态生成分为三种类型:①基于姿态关键点的人体姿态生成;②基于外观流的人体姿态生成;③基于网格的人体姿态生成。
2.1 基于姿态关键点的人体姿态生成
基于姿态关键点的人体姿态生成是最典型的姿态生成网络。一般来说,首先使用姿态估计方法来获得人体姿势,然后使用生成对抗网络来完善和细化结果。
如图2中的PG2框架,第一阶段,生成器是类似U-Net[7]的结构,输入是原始条件图像和目标姿势,使用了18个热图来编码姿势,输出是一个具有目标姿势但粗糙的生成结果。第二阶段,生成器采用DCGAN[8]的变体进行对抗性训练来完善第一阶段的结果,补充细节信息。对于判别器,PG2将第二阶段的输出与原始条件图像进行配对,让判别器学习判断真实的配对和虚假的配对。之后,Ma等人[9]进一步改进了他们以前的工作,将输入图像的前景、背景和姿态分解并编码为嵌入特征,然后解码为图像。虽然生成更加可控,但是降低了生成图像的质量。
面对姿态生成中存在的几何可变性和空间位移,Dong等人提出了Soft-Gated Warping-GAN[10],利用一系列的仿射变换来解决原始条件图像和目标图像之间的错位问题,并采用了层次结构的两阶段判别器来提高合成图像的质量。虽然Soft-Gated Warping-GAN能够产生比较真实的外观,生成不同姿势的高质量人物图像。但在处理不同姿势之间的错位时,必须有效地计算仿射变换,这使得该模型比较脆弱,应用于不常见的姿势时表现不佳。
Men等人提出了属性分解GAN[11],将人的属性作为独立编码嵌入到隐空间中,并通过显式风格表示中的混合和插值操作,实现对属性的灵活和连续控制,实现了可控的人体姿态生成。Zhu等人[12]提出了一种级联的姿态-注意力转换模块PATN,生成器的核心是一连串的姿势-注意力转移块,每个姿势-注意力转移块结构相同,输入为图像和姿势的表示,通过模块当中的注意力机制,能够推断出人体姿态中的感兴趣区域,将姿势的变化限制在局部的小范围,形成渐进式的姿势转移方案,减少了计算量。
2.2 基于外观流的人体姿态生成
光流[13]能够提供图像像素间的对应关系,常用于动作识别[14]。外观流[15]则能提供不同视角的图像间的对应关系,鉴于此,Li等人[16]提出了基于外观流的任意姿势转换模型。
如图3所示,该网络首先编码源人物图像和目标姿势,然后训练一个外观流生成模块,该模块直接从一对二维姿势回归到相应的外观流,进一步生成一个可见性图,可见性图可以在正确位置合成像素,以指导编码后的图像特征,最后这些图像特征联合生成目标图像。这是一种新的人体姿势转移的方法,整合了来自二维表征的关于三维几何的隐性推理。通过估计密集的三维外观流,能更好地指导姿势之间的像素转移,但也增加了估计流场的难度。
Ren等人[17]提出了一个全局流动的局部注意框架。首先提取全局相关性并生成流场,之后根据获得的流场,使用局部注意对目标人物进行源纹理采样。该方法使模型的每个输出位置只与源图像的局部特征有关,降低了流场估计任务的难度。
2.3 基于网格的人体姿态生成
针对人体姿态合成方法只能表达位置信息,不能描述个人的个性化形状和建立肢体旋转模型的问题。Liu等人[18]提出了Liquid Warping GAN,将人体分解为姿势和形状。它输出三维网格,而不再是关节或身体布局。
如图4所示,Warping Block(LWB)的第一个身体网格恢复模块使用HMR[19]作为三维姿势和形状估计器,估计源图像和参考图像的三维网格,并呈现它们的对应图。第二个流组成模块根据两个对应图和它们在图像空间中的投影网格计算出变换流,将源图像分解为正面图像和被遮蔽的背景,接着流组成模块根据变换流进行翘曲,产生翘曲的图像。最后一个GAN模块中,生成器由三个流组成,用来生成背景图像,重建源图像,以及合成参考条件下的目标图像。该方法处理不同视角的人物比较灵活,错位较少,但变换过程更复杂。
3 基于视频的人体姿态生成
基于视频的人体姿态生成是指给定源主体一系列动作的视频,所对应的目标主体能够执行与原主体完全相同的动作。2018 年,Nvidia[20 ]基于pix2pixHD[21],提出了高分辨率视频生成模型vid2vid。vid2vid可以用于合成高分辨率的舞蹈视频,将舞蹈动作迁移到新的舞者身上。
如图5所示,vid2vid使用了两阶段的生成器,第一阶段的生成器用来生成全局的低分辨率视频,输入是前L帧和当前帧的语义映射序列以及前L帧的生成图像序列,输出是原始图像、光流和权重掩码;为了处理视频中的冗余信息,vid2vid还引入了光流来约束相邻两帧之间的运动像素信息,并得到当前帧的预测值。第二阶段的生成器输入是原分辨率的语义映射序列及生成图像,进行卷积之后,将提取的特征图与第一阶段的输出相加,送入第二阶段生成器的后半部分,生成局部的高分辨率视频。vid2vid的判别器则用来计算图像是否真实的得分。
vid2vid模型泛化能力比较差,不能将姿势推广到非训练集中的人。于是Nvidia又提出了Few-shot vid2vid[22],Few-shot vid2vid新增了一个权重生成网络,用来提取若干实例图的特征并映射成一维权重,之后将该权重加入训练好的生成模型中,解决了模型泛化的问题,但对于姿态生成质量并未提升。
2019 年,Chan 等人[23]提出的EDN模型。EDN模型使用预训练好的姿态估计器来创建姿势图,并将获得的姿势作为帧与帧之间转换的中间表示。之后考虑到源人体和目标人体帧内位置和大小的差异,在姿势图和目标人物图之间计算相应的比例和平移关系。最后进行对抗性训练,学习从姿态图到目标人物图像的映射。2020 年Yang 等人[24]提出视频运动重定位模型TransMoMo,能够将源视频中人的运动真实地转移到另一个目标人的视频中。TransMoMo主要利用运动、结构和视角三个正交因素的不变性进行训练。虽然该网络能够生成实际生活中的某些复杂动作,但是网络的损失函数近乎十项,使得网络整体比较难训练。
4 相关数据集及评价方法
人体姿态生成的评价指标需要对生成的质量进行评价,在验证数据集的构建方面,不仅要考虑图像和视频的类型,而且要兼顾图像与视频的复杂度。目前,针对基于图像的人体姿态生成任务,主要使用的是DeepFashion[25]和Market-1501数据集[26],针对基于视频的人体姿态生成任务,EDN和Vid2vid使用的是网上收集的视频,TransMoMo在合成的Mixamo数据集[27]上进行训练。
一般来说,人体姿态生成使用结构相似度(SSIM)[28]、初始得分(IS)[29]和Fréchet Inception Distance(FID)[30]方法,对生成的图像和视频进行考量,在基于视频的人体姿态生成任务中,还使用了人类主观测试来评价生成视频的效果。本节主要介绍目前常用的数据集、相关评价方法,总结了部分模型性能。
4.1 人体姿态生成常用评价方法及指标
由于人体姿态生成与图像生成流程类似,其评价也多是使用图像生成的方法,目前使用最多的是结构相似度(SSIM)和初始得分(IS)。SSIM方法是一种衡量两幅图像相似度的指标,主要比较亮度、对比度和结构这三个方面。用[a]和[b]分别表示两幅图像,SSIM 的计算方法为:
[SSIM(a,b)=[l(a,b)]α[c(a,b)]β[s(a,b)]γ] (1)
α>0,β>0,γ>0,其中,[l(a,b)]表示亮度比较,[c(a,b)]表示对比度比较,[s(a,b)]表示结构比较,SSIM值的范围在[0,1]之间,值越大表示图像越相似。