基于TMM-LSTM的出租车目的地预测
作者: 宋传东 李亚东 徐丽
摘要:近年来,随着城市化进程的加快,城市中的出租车数量越来越多,并且由于出租车的特殊性,一直活跃在城市路网中,在城市交通流中占比较大。准确地预测出租车目的地,并合理地调度出租车,对城市交通管理、合理利用交通资源有重要的意义。出租车目的地预测中一直存在着长期依赖问题,即轨迹序列的预测结果与依赖前面点的距离较长,较长的距离使得在反向传播的过程中,容易产生梯度消失或梯度爆炸,使得误差较大。为了更有效地解决长期依赖问题,文章采用树形存储模块(Tree Memory Module) 来增强LSTM,并将增强的LSTM应用于出租车出行目的地预测。通过实验证明,TMM-LSTM相比较LSTM,预测精度能提升约6%。
关键词:GPS轨迹;目的地预测;树形存储模块;LSTM
中图分类号:TP389.1 文献标识码:A
文章编号:1009-3044(2022)25-0033-04
开放科学(资源服务) 标识码(OSID) :
随着移动设备的普及和全球定位系统(Global Positioning System) GPS的成熟,城市中许多出租车都搭载了GPS,出租车在运行过程中产生了大量的GPS轨迹数据。轨迹数据包含的轨迹点按照时间顺序进行排列,近似表示出租车的运行轨迹,这也使预测出租车轨迹目的地成为可能。已知出租车运行的部分轨迹来预测出租车此次行驶的终点,即目的地预测。准确预测出租车轨迹目的地对于城市交通合理规划起着至关重要的作用[1-3]。
出租车目的地预测方法多种多样,并且该研究广受关注。2015年ECML/PKDD会议举办了出租车目的地预测挑战。在这次竞赛中,de Brébisson A等人[4]采用MLP(multi-layer perception) 模型进行出租车轨迹目的地预测,该方法将轨迹数据与出租车运行时产生的元数据融合,按时间顺序输入模型中,加强了轨迹点之间的联系,通过聚类和分类来挖掘轨迹点之间隐藏的特征,进而利用这种隐藏特征实现对应轨迹的目的地预测;Endo Y[5]等将轨迹数据表示为网格空间中的离散特征,并将网格序列传入RNN(循环神经网络) 中,预测下一个时间点的转换概率,以此来进行目的地预测;Yu等人[6]采用DCNN(深层卷积神经网络) 和LSTM(长短期记性模型) 进行出租车目的地预测,文中同样将出租车运行时产生的元数据作为轨迹数据的补充,并使用DCNN来捕捉交通数据间的空间属性特征;张国兴等人[7]将Surprisal-Driven Zoneout[8]用于改进LSTM单元,从而改进了RNN模型,概率化舍弃或保留神经元状态在隐藏层的传输,以此保证正确状态的传输;Li等人[9]基于LSTM,将提取的深度时空特征和原始轨迹结合,预测出行目的地;Jun Xu等人[10]使用LSTM预测纽约市不同区域的出租车需求,因为LSTM能够通过一个单元(cell) 保存轨迹之间的长期依赖状态,并通过门(gate) 控制,以此解决长期依赖问题,该方法的预测误差较小。
虽然上述方法能够取得较好的预测准确率,但是仅适用于较短的轨迹序列,对于较长的轨迹序列间的深层关联并没有很好的处理能力,无法解决轨迹序列建模中存在的长期依赖问题,即轨迹序列的预测结果与依赖前面点的距离较长,较长的距离使得在反向传播的过程中,容易产生梯度消失或梯度爆炸,使得误差较大。准确合理地解决出租车轨迹建模中的长期依赖问题,对预测的结果准确率提升有重要影响。而LSTM虽然可以在一定程度上解决轨迹序列中的长期依赖,但是如果序列很长,反向传播过程中也会因为距离过长产生较大的偏差。为了更有效地解决长期依赖问题,本文采用树形存储模块(Tree Memory Module) 来增强LSTM,并将增强的LSTM应用于出租车出行目的地的预测。
1 相关工作
1.1 树形存储模块
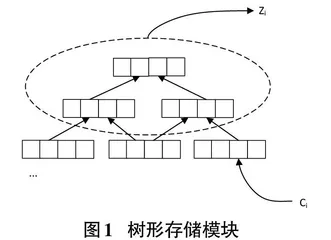
树形存储模块结构如图1所示,从图1中可以看到,父结点有两个子结点,并且可以通过子结点获取下一层的信息,因为是树形结构,使当前结点和历史结点的相隔层数变得更少,所以父结点可以更好地映射历史信息。从图中可以看到,存储模块可以根据输入[ci]生成对应的[zi],[zi]为存储模块中与[ci]最相关的记忆单元。存储模块由S-LSTM构成,它将LSTM中的一般顺序结构拓展成自上而下的树形结构,如图1中,本文将S-LSTM结构表示为二叉树,即每个父结点最多有两个子结点,实现了轨迹序列输入之间长距离交互的办法,优化了LSTM模型处理长序列的问题。
一个S-LSTM的结构如图2所示,[fLn,fRn,in,on]各自表示左遗忘门、右遗忘门、输入门和输出门,[⊗]表示乘法。
在训练的过程中,存储结构的记忆更新是非常重要的。由图2可以看出,隐藏的两个子结点,[hLt-1、hRt-1]为左结点和右结点的输出,这两个子结点会作为当前结点的输入。输入门[it]的输入有四个:隐藏的向量([hLt-1,hRt-1]) 和两个子结点的单元向量([cLt-1,cRt-1]) 。这四个参数同样是左遗忘门[fLt-1]和右遗忘门[fRt-1]的输入,用于产生门信号。左侧和右侧的遗忘门可以分别控制,允许从子结点向上传递信息。输出门[ot]需要考虑隐藏层的子结点向量和当前的记忆单元向量。通过这种方法,记忆单元通过遗忘门合并子结点可以直接和间接地影响多个子单元。因此,可以提取到结构上的远距离的相互关系。在时间序列t时,存储结构中每个结点中的单元信息和门控信息的更新方式按照公式(1) 至公式(7):
[it=σ(WLhihLt-1+WRhihRt-1+WLcicLt-1+WRcicRt-1)] (1)
[fLt=σ(WLhflhLt-1+WRhflhRt-1+WLcflcLt-1+WRcflcRt-1)] (2)
[fRt=σ(WLhfrhLt-1+WRhfrhRt-1+WLcfrcLt-1+WRcfrcRt-1),] (3)
[xt=WLhchLt-1+WRhchRt-1] (4)
[ct=fLi⊗cLt-1+fRi⊗cRt-1+it⊗tanhxt,] (5)
[ot=σWLhohLt-1+WRhohRt-1+WPcoct,] (6)
[ht=ot⊗tanh (ct)]。 (7)
其中[σ]是sigmoid函数,用于将门信号限制在[0,1]之间;[fL]与[fR]分别代表左遗忘门和右遗忘门;W是网络权重矩阵;U表示一个Hadamard积。权重矩阵[W]的下标表示他们用于映射哪个向量到哪个门,比如,[Who]是一个映射隐藏向量到输出门的矩阵。
在LSTM的重复模型中,当序列变得太长时,输出会偏向于最近的历史状态,而不是同等地考虑整个历史状态[11]。上述结构中,用树状结构表示内存,使不同抽象级别的相邻内存单元之间保持了逻辑一致性,并成功地将相邻区域的重要特征传递给上一层。
1.2 问题定义
出租车目的地预测就是基于采集到的出租车轨迹数据和其他数据,预测出租车行驶的目的地,本文中进行如下定义:
预测目的地[Df]:预测目的地是模型通过输入的轨迹序列对应得出的预测结果,预测结果也是一个GPS点,即[Df=lon,lat]。
半正矢距离[DH]:半正矢距离是地球上的两个坐标点之间的实际距离,这两个点都是由经纬度的坐标来表示。半正矢距离可以表示预测目的地[Df]和真实目的地[Dt]之间的距离,计算方法定义如公式(8) 所示:
[DHDf,Dt=2Rarctan(a(Df,Dt)aDf,Dt-1)] (8)
其中[a(Df,Dt)]定义如公式(9) 所示:
[a(Df,Dt)=sin2lat2-lat12+coslat1cos (lat2)sin2(lon2-lon12)] (9)
其中[lat1,lon1,lat2,lon2]分别是[Df]和[Dt]的经纬度坐标,R为地球半径,值为6371km,计算得出半正矢距离[DH],单位为km。
平均距离误差[Qprepp]:计算测试集中对应各条轨迹的预测目的地[Df]和实际目的地[Dt]之间的半正矢距离,并取平均值。计算过程如公式(10) 所示。
[Qprepp=∑X∈YDH(Df,Dt)γ] (10)
其中,X代表测试集中的某条轨迹,Y代表整个测试集,[DH]为预测目的地和真实目的地间的半正矢距离,[γ]代表测试集中轨迹的数量。
预测准确率[Pac]。本文设定当预测目的地[Df]和真实目的地[Dt]之间的距离[DH]小于1km时则为预测正确,否则为预测失败。计算公式定义如(11) 所示:
[Pac=∑X∈Y(Dh<1)γ×100%] (11)
其中[γ]为测试数据集中轨迹的数量。
2 基于TMM-LSTM目的地预测方法
为了更好地捕捉轨迹点间的长期关系,从而解决出租车轨迹间的长期依赖问题,本文采用了具有树形存储模块的LSTM模型(TMM-LSTM) 来进行出租车目的地的预测,通过增加一个外部的树形存储模块,可以更好地捕捉并处理轨迹间的长期关系,以提升模型的预测准确率。
在图3中,第一步:轨迹序列[Xi]和轨迹相关的元数据信息结合作为输入数据[Ai],如公式(12) 所示。元数据是波尔图出租车数据集在采集行驶数据时采集到的其他和驾驶相关的数据,包括出租车编号、用户编号,上车的时间点等信息。本文选取出租车轨迹序列中的前[k]个点 {[x1,x2,…,x5, xk]}和后[k]个点{[xT-k,xT-k+1,…,xT-1,xT]},每个点包含经纬度,即[xt=(lon,lat)],这样共得到2k个点,也就是有4k个数值。在此次实验中,本文设定k=6,所以输入模块的维度为30(6*2*2+6) ,其中前后各6个点,加上6个轨迹相关的元数据,其中前24个为经纬度坐标(前12个点为纬度坐标,后12个点为经度坐标) 。
[Ai={Xi,ClientId,TaxiId,StandId…}] (12)
第二步:通过一个LSTM层,将当前的输入生成一个可以表示当前输入的中间变量[ci],如公式(13) :
[ci=fLSTM(Ai)] (13)
第三步:将[ci]作为存储结构的输入,通过[fscore]注意力得分函数, 计算出当前输入和存储结构的相关性得分[mi],其中[Mt-1∈Rk×(2l-1)],是从根结点到叶结点的邻接矩阵,可以表示当前存储结构的状态,其中k表示隐藏层嵌入维度,[l]为树形记忆结构的深度(二叉树的树高) 。得分函数定义为公式(14) 、公式(15) :