基于YOLOv4的多形态火焰目标检测模型训练方法研究
作者: 姜国龙, 褚云飞,陈业红,吴朝军
摘要:火灾是一种多发的破坏性灾难,通常会导致生命和财产巨大损失,利用图像监控系统,研究自动化火焰目标检测模型意义重大。文章采用基于深度学习的目标检测系统YOLOv4算法训练模型。自建了一个没有重复数据,包含1566张火焰图像的数据集Multifire,它是一个小规模的混合数据集,进行了精心的数据标注和清洗,旨在训练通用性好的多形态火焰检测模型。通过在不同分布的火焰数据子集上实施交叉验证,筛选出3个性能良好的火焰检测模型,模型针对规则火、森林野火和混合火进行检测,综合性能指标F1,分别达到了0.87、0.88和0.78。对于一般性的多形态火焰检测任务,笔者提出一种集成检测的策略,有效降低火焰目标检测的漏检率,提高火焰检测系统的可用性和安全性。
关键词:YOLOv4 ;火焰目标检测;迁移训练;交叉验证
中图分类号:TP183 文献标识码:A
文章编号:1009-3044(2021)32-0001-05
众所周知,消防安全是保障人民生命财产的重要工作,火灾自动检测与预警意义重大。有很多基于计算机视觉的火焰目标检测应用系统出现,然而,面对复杂环境和多形态火焰目标时, 火焰检测模型存在着很大的误检和漏检的风险。近年来,因其具有强大的特征自动学习的潜力,深度学习在图像识别与目标检测领域取得了快速的发展和巨大的成功。本文旨在探讨提高火焰检测模型通用性和实用性的途径。目标是解决目前各种火焰检测算法普遍存在的火情误报和漏报严重的情况。笔者采用的主要研究方法包括:采用深度学习目标检测算法,建立有效的数据集,进行数据整理和清洗,模型训练采取迁移方式,模型评估实施交叉验证。
1引言
物体检测建模算法一般可以分为一阶段和两阶段两大类。一阶段方法的代表如YOLO,模型训练和检测的速度很快,被证实可以达到实时视频处理的要求[1-2]。笔者的实验发现,YOLO训练的模型普遍能达到很高的检测精度,很少误报,但是存在漏报的情况,提高检测模型的召回率ReCall或者综合指标F1是YOLO算法训练的主要方向。另外,一阶段算法对于小目标检测普遍困难,有可能延迟发现隐患的时间,降低预警系统的应用价值。文献表明,使用残差卷积网络层做主干网,通过配置金字塔特征映射结构,可以有效地减轻小目标难检测的问题[3]。同时,很多最新的网络配置也被用于提高火焰检测性能的努力,例如,采用空洞卷积网络层(又称可变形卷积网络层)来提高火焰目标的模糊学习能力;采用注意力机制,显著地帮助检测网络获得更好的性能[4]。在YOLO之外,一些检测网络,例如SSD、RefineDet、RetinaNet,都针对小目标和检测速度的问题进行了改进,在同样数据集上对上述算法进行对比将是非常有益的工作。
深度学习算法高度依赖数据集的质量和数量。数据集的建设包括数据收集、清洗和标注。火焰图像数据来源广泛,例如来自监控视频、无人机航拍以及网上图像搜索等。采用监督方式训练模型,扩大图像数据集的规模必然需要提供更多的准确标注,然而火焰目标标注的不确定性大,存在着一定挑战。
火焰检测的训练一般都会涉及性能和模型大小之间的权衡。如果笔者采用更深更复杂的深度网络结构,能提高模型性能,但是也会增加模型存储空间并延迟反应时间,有时这些会限制模型在嵌入式设备中的灵活布设[5-8]。本文设计的实验方案,尝试平衡算法处理性能和模型尺寸问题。笔者采用YOLOv4深度目标检测算法进行建模实验,通过交叉验证评估模型的泛化能力,最终筛选出了性能良好的通用火焰预警模型。具体设计路线如下:首先,建立包含各种应用场景、多种火焰形态的无重复的训练数据集。根据火焰目标学习的难度,将火焰图像数据分为规则火焰和不规则火焰两大类。其次,采用迁移训练的方法缓解深度学习对于大规模数据的依赖,在规模有限的火焰检测数据集上对预训练一般性的目标检测模型进行迁移[9-10]。实验表明,笔者训练的模型在规则火目标检测方面性能优异,同时基于建立的多形态火焰混合数据集,训练的模型具有良好的泛化能力。
2 数据集建设
2.1 数据收集和划分
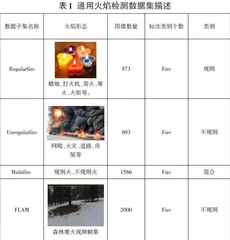
为了训练健壮的通用火焰检测模型,需要建立一个多样化的火灾训练数据集。笔者收集了不同来源的火焰图像数据,去除重复数据并重新标注,构造了一个无重复图像的综合数据集。此数据集内又划分为两个独立数据子集,保证子集之间都没有重叠。数据子集按照形态特点分为规则火焰和不规则火焰子集。其中,规则火焰子集包含873张无重复图像的火焰检测数据;不规则火焰子集包含693张图像。所谓的规则火焰,一般图像质量较好,图像中的火焰目标有清晰的外部轮廓并且形状相近,如蜡烛、火柴、打火机等;或者能很好地分割出独立的火焰目标,如火炬、堆火、营火等。不规则火焰主要来自火灾现场,包括社区房屋,道路交通以及室内室外等,一般出现大量的遮挡、连绵燃烧物以及浓烟,不容易分割出独立火焰目标。规则数据集和不规则数据集之间是没有重叠数据的。Multifire是一个混合火焰数据集,它是上面两类数据集的合集,包含1566张图像。可以训练通用的火焰检测模型。笔者的数据集中还包括了一个公开的数据集FLAM,它是来自北亚利桑那大学等单位学者公开的一个基于航拍图像的森林火情检测数据集。这些数据子集组成了笔者发布的火焰数据集QLFLAM。表1记录了笔者建立的火焰检测训练数据集中子集的划分以及数据描述。
2.2 数据标注
数据标注也是数据集建设中工作量最大的部分。笔者使用Imagelabel软件(https://gitcode.net/mirrors/tzutalin/labelimg)建立了数据标注或对原有标注进行校验。实践证实,数据标注的质量直接会影响到模型训练的效果。标注工作应该尽量减少不一致。独立分布的火焰以及轮廓规则的火焰更容易标注,应该尽量按照独立和规则的原则标注。被遮挡物割裂的零散火焰,应该忽略遮挡物,把火焰各部尽量分放在一个标注边框里。对于小火簇,如灰烬中的火焰群,如果位置上接近,也尽量放在一个边框里标注。特别地,对于FLAM数据集中的数据,笔者还利用了数据集提供的图像分割标注数据辅助,更准确地发现和定位火焰目标。
3 主要算法和性能评估
3.1 深度目标检测算法
2014年,Ross Girshick提出R-CNN算法,首次将卷积神经网络用于目标检测领域,继之以Fast R-CNN、Faster R-CNN,基于深度学习的目标检测算法不断改进。由于R-CNN的网络是两阶段结构,也就是将候选区域的检测和分类识别分成两个阶段执行,算法目标检测精度高,但是检测速度慢,无法满足实时性。2016年,Joseph Redmon提出YOLO算法,将候选区域检测和分类识别合为一个,成为单阶段结构的开山之作,大大提高了目标检测的速度。在YOLO算法框架中,可以很好地结合上下文的图像信息特征,检测到的火焰目标,准确率(Precision, P )都很高,这是YOLO误检率低的主要原因。然而,比起采用候选区域的Faster RCNN,YOLO检测边框的定位偏差比较大,召回率(Recall, RC)还有一定差距。采用YOLOv4算法训练的火焰检测模型,整体性能强于YOLOv3和Faster RCNN,进一步提高召回率是YOLOv4努力的方向。
3.2 迁移训练
YOLO模型的训练可以有两种方式,即从头训练方式,或是从预训练的主干网络上进行参数微调迁移。因为数据量的缺乏,从头训练火焰检测模型的效果是很差的,需要采用预训练的模型进行迁移训练。YOLO目标检测算法支持迁移训练,负责特征抽取任务的主干网络一般采用在ImageNet上训练的一般图像特征抽取模型进行初始化。还需要在一些大型数据集预训练一般化的目标检测模型,例如在VOC或COCO上进行预训练的初始目标检测网络,分别能检测20或80种常见目标。训练火焰目标检测模型需要在火焰检测数据集上,对于初始目标检测网络进行迁移训练。在第一阶段,将预学习的主干网的参数冻结,这是为了保持一般化的图像特征的抽取,专门训练深度网络中的其他参数,为了提高对火焰目标的识别能力;第二阶段,将所有参数冻结解除,继续训练,这时可以学习到与火焰目标相关的特征,并达到最终训练的模型。
3.3 火焰检测模型训练和检测整体路线
本文采取YOLOv4算法,通过迁移训练来突破深度学习模型训练对火焰标注数据量的限制,在较小规模的数据集上训练出性能良好的目标检测模型。
图2包括迁移训练、目标检测和性能评估几个部分。火焰训练和火焰测试如果来自不同分布的数据子集,形成交叉验证,可以测试训练模型的通用性。其中椭圆标注交叉验证实施时训练数据和测试数据的载入位置。
3.4主要性能评估指标
目前,基于深度学习的火焰目标检测方法主要的挑战来自检测速度,模型存储大小和检测性能。这些方面的差距都影响了火焰检测模型的训练和实际应用的价值。YOLO算法的检测速度公认是最好的,本次研究主要关注平均准确率AP,综合评估F1,召回率Recall和精度Precession。特别的,F1更适合作为火焰检测模型的评估标准。
3.4.1 IOU
计算两个矩形框之间的重叠面积与重合面积之比得到IOU,如图3所示。
通过设定IOU阈值可以定义目标检测是否成功,以及偏差的程度。
3.4.2 Precision和Recall
查准率(Precision)也叫精确率;查全率(Recall)也叫召回率。对于二分类问题,可将样例根据其真实类别与学习器预测类别的组合划分为真正例TP(True Positive)、假正例FP(False Positive)、真反例TN(True Negative)、假反例FN(False Negative)四种情形,令TP、FP、TN、FN分别表示其对应的样例数,则TP+FP+TN+FN=样例总数。查准率(精确率)(Precision)
[Precision=TP+FPTP] (1)
查全率(召回率)(recall)
[Recall=TP+FNTP] (2)
3.4.3 F1 score
Precision和Recall是一对矛盾的度量,一般来说,Precision高时,Recall值往往偏低;而Precision值低时,Recall值往往偏高。当分类置信度高时,Precision偏高;分类置信度低时,Recall偏高。为了能够综合考虑这两个指标,F-measure被提出(Precision和Recall的加权调和平均),即:
[F1=2×P×RP+R] (3)
F1的核心思想在于,在尽可能提高Precision和Recall的同时,也希望两者之间的差异尽可能小。
3.4.4 平均精度(AP)和平均精度均值(mAP)
对于IOU选取不同的阈值,可以绘制出P-R曲线,反映模型在选取不同阈值时,其精确度和召回率的趋势走向。在YOLO中,根据检测器的预测得分结果,对所有检测样本进行降序排序,逐一作为正例的预测阈值,计算出对应的Recall和Precision两个值作为横、纵坐标就得到P-R曲线。AP 是计算某一类 P-R 曲线下的面积, mAP是对所有类别的 AP取平均值。和F1一样,AP和mAP更好地反映整体应能,也是常用的性能评价指标之一。
[AP=01P(r)dr] (4)