DeepSeek新浪潮
作者: 刘以秦 吴俊宇 顾翎羽 周源
2025年春节的前一周,节日气氛正浓,来自中国杭州的一家初创公司开始让华尔街投资人寝食难安。
杭州量化私募机构幻方旗下的大模型公司DeepSeek(深度求索)发布的一款开源AI模型,在多项测试中表现优于OpenAI的产品,且研发成本不到600万美元。更让华尔街投资人震惊的是,DeepSeek1月20日发布R1模型,上线六天后同时登顶苹果App Store和谷歌Play Store全球下载榜首,上线18天内,累计下载量已突破1600万次。随后在2月1日突破3000万大关,成为史上最快达成这一里程碑的应用。
华尔街的担忧在于,目前投入数十亿美元用于构建大型AI模型的做法可能会打水漂,更廉价的替代方案将让华尔街人工智能的泡沫破裂。泡沫破裂带来的资本市场危机短期内是否会再次上演?
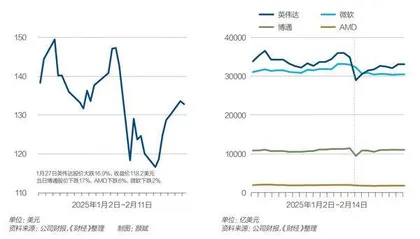
到了春节前一天,这种担忧气氛开始达到顶峰。1月27日晚间,美股科技巨头股价集体下跌:英伟达股价下跌约17%,市值蒸发近6000亿美元,创下美国股市历史上最大单日市值跌幅纪录。博通公司股价下跌17%,AMD下跌6%,微软下跌2%。美股指数当日下跌:纳斯达克综合指数跌3.07%,标普500指数跌1.46%。人工智能领域的衍生品,如电力供应商也受到重创。美国联合能源公司股价下跌21%,Vistra的股价下跌29%。
1月27日之后英伟达股价在震荡中回升。老虎国际数据显示,2月13日英伟达股价为135.29美元,较前一交易日上涨3.16%。但这可能不是一次简单的技术性调整,目前没有明确的整体持续回调趋势。
相对于美股投资者,全球AI产业界的视角心态更加复杂微妙。短暂慌乱和研判之后,中美主流厂商先后拿出了表态和新的动作。
最开始,慌乱情绪蔓延。有大模型公司陷入恐慌情绪,有人反思为何这样的创新没有发生在自己的公司里,有人为新方向出现而兴奋,准备“大干一场”。
图1:英伟达、微软、博通、AMD1月27日股价均下跌
很快,新的布局开始了。曾经占据开源模型主导地位的Meta,在过去几个月要求技术团队加班加点,复刻DeepSeek路径。全球大模型领域最知名的公司OpenAI也调整了模型发布策略,不再“挤牙膏”。
各大科技厂商(包括亚马逊AWS、微软Azure、谷歌云、阿里云、华为云、腾讯云、百度智能云等)在模型商店中迅速上线了开源版的DeepSeek-V3/R1这两款模型。因为企业客户对DeepSeek-V3/R1的需求旺盛,此举可以为科技云厂商带来算力收入。
1月29日,阿里云发布了开源的通义千问Qwen 2.5-Max MoE(混合专家模型),它使用了和DeepSeek-R1类似的技术路线。谷歌2月5日上线自研大模型Gemini 2.0,推出和DeepSeek-R1功能类似的思维链功能。OpenAI CEO(首席执行官)萨姆·奥尔特曼2月13日宣布,GPT-4.5/5将很快发布,ChatGPT将搭载GPT-5,并可无限制免费对话。百度一度是“闭源模型+模型收费”的拥趸,坚持不做开源模型,但2月14日百度宣布了一系列动作——文心一言4月1日起免费,未来数月推出文心大模型4.5系列,6月30日开源文心大模型。
整体来说,它们选择两条腿走路——
一方面是拥抱DeepSeek,另一方面是跟进技术方案类似的自研产品。
DeepSeek的开源如同鲶鱼,改变了科技大厂们的既定动作。过去,科技厂商对大模型是否要开源存在大量争论.如今,国内科技大厂如阿里、腾讯、百度已经全部选择加入开源阵营。这意味着曾经试图靠模型收费的商业模式不再成立。
一级投资市场的反应更快,春节假期还没结束,不少投资人已经开始四处寻找门路,但“连DeepSeek核心团队的面都见不到”。更多投资人意识到这家公司可能不开放融资后,快速调整策略,大量机构组团去杭州约见其他的科技公司,一些在2024年认为AI创业公司估值太高、风险太高的投资人重新燃起热情,“害怕错过”的情绪再次蔓延。
不同行为、不同态度的背后是复杂的资本、技术、人才和市场等因素交织作用。《财经》综合采访调研结果显示,DeepSeek带给中美产业界的巨大转变有两点。
其一,人们此前普遍认为,大模型的关键突破都在美国,其他国家都是在反向工程。DeepSeek打破了这一刻板共识,成为近20年来第一个拿出革命性方案的中国创业公司。人工智能时代目前仍处于发展初期,DeepSeek激发全行业找到一张阶段性新地图,发展AI技术的另一个解法——并非一味地追求算力膨胀。这意味着在美国对中国实施算力封锁的当下,中美AI企业重新站到了一个新的竞争维度上,一个乐观的判断是,双方差距将快速拉近。
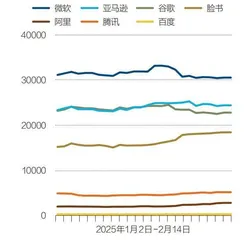
图2:全球重点科技公司2025年的市值变化情况
其二,此前全球的AI竞争的焦点在于训练,产业界普遍认为推理很重要,但这个过程会很漫长,不是现在。DeepSeek把时间节点提前了。当产业界将竞争焦点集中到推理,除了算力成本革命性下降,对整个AI行业还有更加深刻的影响——硬软件协同会进一步加强,基于大模型技术的千行百业应用将大发展,而不是仅仅对话模型了。马上,人们不仅能看到整个行业从芯片、服务器、算力中心到终端、能源的产业剧烈变化,还能看到基于大模型技术的各种应用出现百花齐放的局面。
狂潮出现
DeepSeek没有根本改变大模型的经济规律,只是持续成本降低曲线上一个可预期的成功。这次的不同之处在于,这是一个中国创业公司
最早注意到DeepSeek并将这家公司推到台前的是硅谷科技圈。
2024年6月,据当地媒体报道,多位美国AI领域专家都表示对中国的AI大模型印象深刻,其中包括DeepSeek-V2模型,报道称,这款模型在一系列标准的行业评估中击败了OpenAI的GPT-4 Turbo、谷歌的Gemini 1.5 Pro和Anthropic的Claude 3 Opus。当时就已经有不少美国行业人士认为,中国的生成式AI起步虽然较晚,但差距比很多人想象的要小。
2024年12月底,刚刚过完圣诞节的硅谷科技圈就开始了对DeepSeek的全面研究。
2024年12月28日,DeepSeek V3模型发布后的第三天,OpenAI创始人萨姆·奥尔特曼在社交媒体评论称,DeepSeek能够以低价算力提供这样的服务令人惊讶。OpenAI将暂停一些新的发布,拥有一个新竞争对手令他感到兴奋。
1月31日,他在Reddit论坛回复网友问题时提到,DeepSeek的出现改变了过去几年OpenAI遥遥领先的情况。
2月7日,OpenAI宣布公开最新模型o3-mini系列模型的思维链(并非完整版),即让用户看到模型是如何推理思考的,而此前,出于竞争考虑,OpenAI没有完全公开o3-mini及其前身(o1和o1-mini)的推理步骤,仅向用户提供推理摘要。
DeepSeek对美国资本市场带来了冲击,甚至引发了美国政策制定者、硅谷科技巨头及创业公司的关注。
美国总统特朗普1月27日在迈阿密发表讲话时称,DeepSeek模型高效且经济,其出现是一种积极的发展,也给美国相关产业敲响了警钟。美国需要集中精力赢得竞争。
微软首席执行官萨提亚·纳德拉1月27日在瑞士达沃斯世界经济论坛表示,应当非常、非常认真地对待来自中国的这些技术进展。
Anthropic是亚马逊投资的一家AI创业公司,它是OpenAI的直接竞争对手。Anthropic CEO达里奥·阿莫代伊(Dario Amodei)1月撰文称,一个公正的说法是,DeepSeek生产出了一款性能接近美国七个至十个月前模型的模型。它的成本大幅降低,但远未达到人们所说的比例。DeepSeek-V3并非一项独特的突破,也没有根本改变大模型的经济规律。它只是持续成本降低曲线上一个可预期的成功。但这次不同之处在于,第一个降低预期成本的是中国公司。这在以前从未发生过,并且具有地缘政治意义。
一位曾在硅谷和欧洲从事多年科技投资的人士向《财经》评价,DeepSeek之所以能在美国科技圈引发地震,主要有三方面因素:一是DeepSeek本身的技术进步,用低成本实现高性能,且不断有新的优化版本出现;二是开源,过去中国在世界科技领域的信任度是被美国所限制的,但开源是透明的,透明就意味着信任,且开源意味着大家都能用,越多人用,就越多人相信这个模型的实力;第三,DeepSeek的出现,颠覆了美国科技公司对AI领域的预设,他们开始反思并调整动作。“我们曾一度认为AI是一座大山,大家努力往上顶爬,现在或许应该思考,AI可能是大海,有很多方向可以探索。”
DeepSeek带来的影响不止在美国科技圈,前述投资人提到,近期所有的相关会议里,DeepSeek都变成了最重要的议题。欧洲和印度的一些创业者和投资人,过去认为大模型是只有中国和美国能做的事,他们不太敢投入,现在大家都好像有了底气,也都在尝试进入这一领域。
在中国,此前大模型行业主要有两类玩家,一是科技大厂们,包括字节跳动、百度、阿里巴巴、腾讯、华为等,它们大多拥有相对完整的AI生态,战略上重视大模型,人才储备和资金实力强大。二是AI创业公司,最具代表性的是“六小虎”——智谱AI、百川智能、月之暗面、Minimax、阶跃星尘、零一万物,它们都拿到了巨额融资,各有发展侧重。
图3:DeepSeek V3/R1的AI技术创新

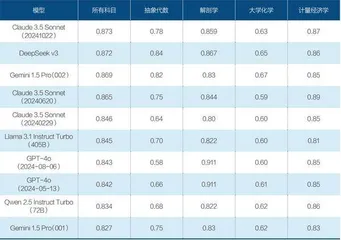
图4:斯坦福大学基础模型研究中心全球大模型综合性能排名