基于大语言模型的图谱自动化构建系统
作者: 杨乾芳 封惠姣 黄少年 陈柬同 陈永康 戴诺倩
关键词:大语言模型;知识图谱;自动化构建
中图分类号:G250 文献标识码:A
文章编号:1009-3044(2025)03-0006-03 开放科学(资源服务) 标识码(OSID) :
0引言
随着社会的发展和信息技术的进步,人类社会面临的各种突发事件愈发频繁和复杂。群体性突发公共事件作为一种特殊的突发事件[1],其事件演化路径错综复杂,具有不确定性和多路性。突发事件通常以新闻文本和摘要等非结构化形式存在,读者在从文本中提取信息时,由于篇幅限制及多义字词的影响,难以准确连贯地把握事件中的实体与关系演化。而对于事件及其关系演化,采用知识图谱能够更直观地表示各实体之间的逻辑关系。
传统实现自动化实体关系抽取[2]的模型多采用深度学习的方式进行实体识别、关系提取和知识融合。Socher等[3]运用RNN分析标记好的文本句子的句法结构,挖掘句法特征。Shen等[4]提出基于注意力机制的CNN模型,分别利用词嵌入、词性标注嵌入和位置嵌入信息,能够充分提取文本的潜在语义特征。Google提出的BERT模型[5]采用双向Transformer编码器来捕捉文本的上下文信息。然而,上述方法均需要大量文本语义标注样本,消耗大量人力和算力,且提取效果与标注质量和模型训练的各种参数密切相关。
近年来,大语言模型在NLP任务中展现了极大的潜力。冯志伟等[6]指出,大语言模型展现出掌握世界知识和理解自然语言的强大能力。田萍芳等[7]通过大语言模型实现了更精准的实体及关系识别,并将其应用于司法命名实体识别。通过为大语言模型提供少量的微调样本,可简化抽取模型中样本标注及训练的过程,从而有效解决非结构化文本中实体泛化和实体关系正确推理的问题,这是图谱构建中的难点与重点。
基于大语言模型(LLM)的图谱自动化构建系统充分利用其推理特性,实现了图谱自动化构建的目标。系统采用多轮Prompt提示工程,并结合少量模型微调,提供抽取背景,充分提取海量非结构化文本中的语义信息,同时融合特征进行实体关系匹配,从而提高图谱构建过程中实体及关系抽取的准确率。系统以Django为主要开发框架,实现了集请求预处理、服务响应、数据清洗、前后端数据传输于一体的图谱构建流程。通过异步抽取机制,进一步提高了图谱数据抽取的效率。该系统实现了基于大语言模型的图谱自动化构建过程,为图谱构建系统的实现提供了一种可行的新方案。
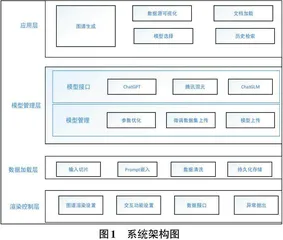
1系统架构设计
基于大语言模型的图谱自动化构建系统,依据图谱构建流程进行了系统架构的设计。针对数据层面,需要实现非结构化文本到结构化文本的简化映射及持久化存储;针对业务逻辑层面,需要实现多种大语言模型API的兼容管理及相关功能的交互;针对可视化层面,需要实现数据的实时动态传输及动态可视化的交互界面。
依据功能需求,系统划分为应用层、数据加载层、模型管理层和渲染控制层。其中,模型管理层是系统的核心模块,通过对模型的管理,用户可以灵活地进行图谱的自动化构建。其系统架构如图1所示。
1.1模型管理层
模型管理层负责实现大语言模型的对接,并联合数据加载层为应用层提供服务。其主要包括通用API模块与模型微调模块。通用API模块提供基础大语言模型API接口,用户无须关注细节处理,只需完成不同模型的接入及部分参数调整,即可实现图谱数据的获取。模型微调模块提供接口支持用户自主部署模型,用户可上传特定数据集,对上传的大模型进行微调[8],以达到最佳的关系与实体抽取效果。在执行图谱自动化抽取任务时,采用异步流程,实现多个构建任务的并发处理,从而提高构建效率,并对图谱构建任务进行进一步的封装与优化。最终,任务执行结果将被组合并返回给数据加载层。
1.2数据加载层
数据加载层主要面向实时图谱抽取过程中的数据任务,包含数据清洗、数据切片[9]、Prompt嵌入和第三方扩展模块。数据清洗模块负责对系统输入的提示词转换及模型输出数据的规范化处理,如剔除冗余数据等。数据切片模块实现对用户输入的非结构化长文本的切分与标记,便于后续模型更精确地提取语义中的实体及关系。Prompt嵌入模块支持在多轮Prompt中调整图谱抽取策略,实现图谱数据的渐进式抽取。第三方扩展模块负责数据的持久化存储,并通过扩展数据接口的方式支持批量图谱抽取任务。数据加载层旨在对大语言模型抽取的图谱原始数据进行有效的接入、转换、清洗和持久化存储。通过数据加载层,系统能够对数据流通进行进一步处理与封装,为后续服务请求及数据资源管理提供可靠的数据基础。
1.3应用层应用层
基于其他层的功能实现与用户交互,是系统的应用管理模块。该层提供模型选择、文件加载、可视化数据及图谱生成服务。用户通过鉴权认证后,可手动添加模型参数(如Key模型授权令牌、Tempera⁃ture生成结构参数等)进行调整。在执行图谱抽取任务时,用户可手动输入原始文本数据,或通过文件加载的方式导入Word、TXT、PDF等格式文件,从而实现原始数据的输入。系统随后按照流程处理数据并生成可视化结果,供用户查看与分析。
1.4渲染控制层
渲染控制层负责管理和控制图谱渲染过程中的各种参数配置,以确保最终渲染结果符合预期的质量和性能。该层基于Echarts和Bootstrap实现图谱及原始图表数据的可视化呈现,并通过Ajax实现与后端的实时交互,保证系统的动态性和实时性。用户可通过交互式界面调整图谱的可视化效果,例如节点大小、关系图路径样式、交互按钮的呈现等。通过参数配置,渲染控制层实现了系统的动态界面及功能交互,并支持对关系实体图谱的高质量可视化呈现。
2系统流程实现
2.1请求服务的设计
2.1.1图谱数据请求API设计
接口设计是构建高效、稳定和安全的Web服务的关键环节。基于Django框架,利用通用API完成本系统的基础服务,通过API的形式简化图谱构建流程,从而实现图谱数据的实时获取。其请求参数如表1所示。
2.1.2微调模型API设计
微调API旨在构建更加专业化、领域化的知识图谱。管理员可自主上传大语言模型权重文件及数据集,选择模型参数,对模型进行微调训练。通过自主模型训练,可以更好地适应特定领域的图谱任务,满足用户的个性化需求。其API参数如表2所示。
2.2图谱数据清洗
数据清洗是图谱构建过程中的重要环节,主要目的是消除所获取图谱数据中的错误、冗余和不完整部分,从而提高图谱的质量和准确性。
2.2.1错误类型定义
根据图谱渲染框架与实体单一原则,我们将错误划分为数据异常类(如空值、null)、实体误差类(如经抽取后实体不一致)和匹配误差类等错误。在抽取过程中,我们依据错误类型进行一系列逻辑判断,并采用相应的策略对数据进行进一步优化,从而提高数据处理的准确性,最终提升图谱数据抽取的准确性。
2.2.2数据处理
在图谱构建流程中,图谱数据多以实体关系元组的形式存在,其定义如下所示:
式中:ID为唯一数据标识,S为源实体,T为目标实体,R为两者实体间的关系。依据数据处理流程,首先需对数据进行去重处理,删除重复记录,保证实体的单一性。同时对数据进行格式化处理,确保所有数据遵循相同的格式标准,便于后期渲染及存储。对于缺失值部分,采用回溯抽取的方法,重新抽取所缺失的实体或关系,并对数据中的非法字符进行剔除。
2.3图谱渲染
图谱渲染基于Echarts框架实现。Echarts是一款基于JavaScript的数据可视化图表库,能够提供直观、生动、可交互且可个性化定制的数据可视化图表。通过其数据项及配置项的灵活配置,可满足图谱数据的可视化需求。在进行图谱渲染时,我们对关系实体数据进行进一步清洗,将其作为数据项用于图谱渲染。
3抽取模式设计
3.1提示词设计
大语言模型具有强大的推理能力,其理想结果通常与用户输入的提示词密切相关。本文针对关系和实体设计了提示词,旨在实现实体关系的精准抽取,其提示词设计如表3所示。
3.2多轮提示词实体关系匹配
多轮提示词用于指导模型生成初始响应,并影响后续交互内容的连贯性。这类提示词通常需要包含足够的上下文信息,以便模型能够理解对话的整体脉络,并生成连贯的响应。当发起任务请求时,系统将原始文本作为输入,通过多轮提示词抽取,最终获取多组实体关系。其匹配模式流程如图2所示。
在图2中,语料数据通过实体和关系提取,生成实体和关系数据流,并将该数据流作为下一轮实体关系匹配融合的输入。根据数据流所携带的序列标识,完成实体关系特征的匹配。最终,通过进一步处理,得到实体关系(RE)元组。
3.3异步并发抽取
asyncio是Python标准库中的一个模块,用于支持异步编程和并发执行。它提供了丰富的API,包括异步函数、异步I/O操作、异步任务调度等。本系统采用即时请求服务的方式来实现对图谱数据的抽取及检索,其任务具有实时性。然而,在多轮提示词输入推理过程中,使用同步大语言模型API往往需要耗费大量时间成本。
通过asyncio异步方式,可以实现多个实体关系抽取任务的并发执行。同时,采用序列化的方式,将数据切片与背景原文进行匹配,增强抽取语段的上下文语义,保证切片段文本的语义连续性,从而提高图谱抽取过程中实体及关系的准确性。通过序列化的方式匹配当前被抽取语句的上下文语义,能够进一步确保图谱数据的上下文语义连续性。
4结束语
知识图谱自动化构建系统旨在利用大语言模型的推理能力,充分挖掘非结构化文本中的实体关系数据,实现图谱的自动化构建流程。通过多级Prompt工程,明确任务指令,增强抽取结果的准确性。同时,系统将数据以可视化形式呈现,为用户提供简洁的交互界面。
与传统图谱实现技术不同,本系统采用生成式模式构建图谱,用户可以通过多轮交互实现图谱的生成与构建。在图谱内容生成方面,系统具有高度的弹性。
目前,大语言模型仍然被视为黑箱,其推理逻辑尚未完全明确。但未来,随着对大语言模型研究的深入,它必将在图谱构建领域发挥更重要的作用。大语言模型技术的发展将推动更加智能化、自动化的图谱构建方法的出现,这不仅为知识图谱的普及和应用奠定了坚实基础,也将进一步推动人工智能技术在各个领域的广泛应用。