基于文本挖掘的陕西省旅游线路推荐探究
作者: 李诗怡 李淑玲摘 要:旅游业作为我国经济收入的支柱产业,在火热发展的现状之下,仍存在较多问题,主要包括地域发展不均衡,旅游资源利用不合理;旅游产品结构单一,旅游业复苏缺乏动力等。本文以陕西省为例,运用隐含狄利克雷分布(Latent Dirichlet Allocation,LDA)模型和K均值(K-Means)聚类算法对陕西3A级及以上的景区进行分析,结合景区的特色与景区间的距离,基于时间成本和景区自身因素为陕西省旅游的游客推荐最优线路。
关键词:文本挖掘;旅游线路推荐;陕西省
中图分类号:F592.7 文献标识码:A
引言
随着旅游业的繁荣和生活水平的提升,人们在追求物质生活的同时,将出行旅游、陶冶情操等精神生活的满足视为生活中不可或缺的一部分。根据文化和旅游部发布的国内旅游数据情况调查结果,2022年上半年国内出游总人数达14.55亿人次。陕西省作为我国中西部地区的旅游大省,不仅拥有独一无二的自然美景,还有深厚的历史文化底蕴,但也存在影响旅游行业发展的因素,如景区分布广,城市的知名度不高等。针对旅游景区分布广、地区旅游不均衡的问题,本文对陕西省3A级及以上景区数据进行分析,充分整合旅游资源,利用文本挖掘算法进行分析与研究,并结合景区间的距离和景区的特色推荐旅游线路,以帮助游客选择合适的旅游线路,从而在一定程度上推动陕西省各城市的旅游业协调发展,为陕西省旅游业发展作出贡献。
一、数据来源
本文研究的数据源于去哪儿旅行网站和百度百科网站,爬取数据时间截止到2022年11月去哪儿旅行网站记录的3A级及以上景区的数据,其中数据说明如表1所示。
二、模型构建与分析
对景区数据进行文本挖掘,有利于游客快速找到合适的旅游路线。下面将使用LDA模型对经过预处理的文本数据进行主题词提取,然后使用K-Means聚类将相似的景区整合。首先,为了提取景区的主题词,需要确定最优模型主题数,通过困惑度曲线图选出合适的主题数;其次,经过LDA模型主题提取出各个主题并展示;再次,根据主题对景区数据结合景区之间的距离进行聚类分析;最后,展示每个主题下的聚类结果,并对其进行描述和分析[1]。
(一)LDA主题建模
1.确定最优模型主题数
由于LDA模型在建模之前需要确定最优的主题个数,本文在确定主题数时选择主题困惑度方法,该方法经常被用于确定主题个数。

本文研究的主题从2到9变换时,困惑度慢慢降到比较低的水平,当主题数增加到9及之后时,困惑度变化不大;当主题数为3、4、9时,困惑度有转折点,困惑度太高则主题数少,会影响聚类效果,困惑度太低又会容易出现过拟合现象,因此既要保证主题数合理又要保证困惑度适中,结合困惑度越低模型效果越好的原则,选择主题数为4。
2.各主题对应关键词
经过LDA主题模型关键词提取后前10个关键词结果如表2所示。
由表2可知,主题一的关键词有秦岭、黄河、瀑布、森林等,它们都属于自然景观;主题二的关键词有博物馆、文物、遗址、黄帝陵等,它们都属于历史文化;主题三的关键词有旧址、延安、红军、毛泽东等,它们都属于革命景区;主题四的关键词有休闲、体验、博览园、参观,它们都属于娱乐生活。
(二)K-Means聚类结果
聚类的主要指标是进行分词处理后的文本数据,基于LDA模型提取的关键词,将包含关键词的共同特征景区进行整合,即各主题所包含的景区与各景区的经纬度信息。

该公式中,a代表向量到同一簇内其他点不相似程度的平均值,b代表向量到其他簇的平均不相似程度的最小值,s代表向量轮廓系数。
根据主题模型整合后的各主题所包含的景区与各景区的经纬度数据进行聚类,并输出每个类簇中心。根据轮廓系数值选取的主题聚类模型结果如表3所示。
如表3所示,主题一聚类结果分为3个类簇中心,即3条线路。以类簇一的经纬度为中心,距离该中心近的景区有16个,包括中坝大峡谷、丹江漂流、九龙山景区、吴山、壶口瀑布等景区;以类簇二的经纬度为中心,距离该中心近的景区有3个,包括天书峡景区、太平国家森林公园、黑河国家森林公园;以类簇三的经纬度为中心,距离该中心近的景区有34个,包括五龙洞国家森林公园、佛坪熊猫谷、关山草原、南宫山、南沙湖景区等景区。主题二聚类结果分为两个类簇中心,即两条线路。以类簇一的经纬度为中心,距离该中心近的景区有28个,包括乾陵、华清宫、华阳古镇、咸阳博物馆、唐昭陵、大明宫国家遗址公园等景区;以类簇二的经纬度为中心,距离该中心近的景区有3个,包括大唐芙蓉园、蔡伦墓、阿房宫遗址。
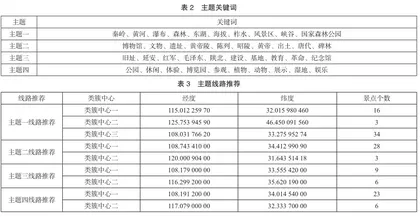
主题三聚类结果分为两个类簇中心,即两条线路。以类簇一的经纬度为中心,距离该中心近的景区有9个,包括中共中央西北局旧址、凤凰山麓革命旧址、延安革命纪念馆、扶眉战役纪念馆、杨家岭革命旧址等景区;以类簇二的经纬度为中心,距离该中心近的景区有6个,包括八路军驻西安办事处、渭华起义纪念馆、长乐塬抗战工业遗址、旬阳县红军纪念馆等景区。
本文为全文原貌 未安装PDF浏览器用户请先下载安装
原版页码:文本挖掘,旅游线路推荐,陕西原版全文
主题四聚类结果分为两个类簇中心,即两条线路。以类簇一的经纬度为中心,距离该中心近的景区有23个,包括秦岭峡谷漂流、秦岭野生动物园、翠华山、茯茶小镇等景区;以类簇二的经纬度为中心,距离该中心近的景区有6个,包括法门寺、姜嫄水乡、杨凌农业示范区等景区。
(三)陕西旅游线路推荐
游客在考虑时间成本时会选择最短线路,因此笔者将结合LDA主题提取各景区结果与每个主题下景区距离的聚类结果,将所有景区分为4种类型。从景区特色方面来入手为游客推荐,表3中主题一所包含的关键词和景区为风景名胜线路,主题二所包含的关键词和景区可以归类为历史古迹线路,主题三所包含的关键词和景区可以归类为红色之旅线路,主题四所包含的关键词和景区可归类为休闲时光线路。下面以红色之旅主题为例介绍推荐线路,游客可以根据旅行需求挑选适合自己的特色线路。
红色之旅根据聚类结果分为两条线路,该两条线路皆是相对于类簇中心而言最近距离的线路,此路线的景区以红色革命为主,纪念馆、革命旧址都记录了革命历程。沿着该线路能够感受党的光辉历程,走进革命圣地,缅怀革命先烈,了解先辈的丰功伟绩,跟随党的脚步,不忘初心。
基于类簇中心一经纬度聚类的结果,主题三第一条推荐线路为枣庄革命旧址-杨家岭革命旧址-延安革命纪念馆-凤凰山麓革命旧址-中共中央西北局旧址;基于类簇中心二经纬度聚类的结果,主题三第二条推荐线路为长乐塬抗战工业遗址-茂陵博物馆-八路军驻西安办事处-猿人遗址-渭华起义纪念馆-旬阳县红军纪念馆。这两条推荐线路都距离中心点较近,且各景区之间的距离也较近,可供游客按需选择。
三、结论与建议
本文通过对陕西省旅游景区的文本挖掘研究,针对线路推荐问题,站在游客的角度上考虑时间成本,结合景区的特色与景区间的距离,采用LDA主题模型对陕西省的景区数据进行整合,将样本数据分为自然景观、历史古迹、红色之旅、休闲时光4类。然后结合景区整合结果与距离聚类,根据类簇中心选出最优线路,最后根据聚类的结果为游客推荐合适的线路[2]。
针对研究中发现的问题,笔者将从两方面提出建议,一方面是景区角度:首先,建议景区加强管理,提高景区服务人员的职业素养[3];其次,由于陕西省的特色景区仅集中在某些城市,景区差异不大,建议陕西省多开发特色景区,满足游客的个性化需求[4];再次,景区要完善公共设施,增加出游交通设备;最后,对于地域发展不均衡、旅游资源利用不合理这类问题,建议结合多个城市让游客体验不同的景区风格。另一方面是游客角度:首先,游客要明确旅游目的地,节省选择地点占用的时间;其次,游客要根据选好的目的地,有针对性地浏览旅游攻略,了解目的地景区特色,从而拥有更好的旅行感受[5]。
参考文献
[1] 胡芳燚.基于用户兴趣和主题模型的混合推荐算法的研究与实现[D].北京:北京邮电大学,2018:4-8.
[2] 黄月,张昕.基于主题词和LDA模型的知识结构识别研究[J].现代情报,2022(3):48-56.
[3] 赵恩泰.融合评论文本情感特征的旅游产品推荐[D].大连:大连外国语大学,2022:12-16.
[4] 孟小丁,刘茄琳,骆鹏睿.旅游线路推荐与优化的研究进展[J].洛阳师范学院学报,2021(11):41-44.
[5] 李旭,李景文,俞娜.基于用户需求的旅游路线推荐方法[J].计算机工程与设计,2021(5):1339-1345.
本文为全文原貌 未安装PDF浏览器用户请先下载安装
原版页码:文本挖掘,旅游线路推荐,陕西原版全文