融合FasterViT架构的基于YOLOv8s模型的生活垃圾检测算法研究
作者: 张欣
摘要:为提高生活垃圾分拣效率和降低人工成本,文章提出一种融合FasterViT 架构的改进YOLOv8s 生活垃圾目标检测算法FV-YOLOv8s。该模型在通用目标检测数据集MS COCO2017 以及自建生活垃圾数据集上均表现出较高的检测精度,在Precision、Recall、mAP50 和mAP50-95 等指标上优于基准YOLOv8s 模型。
关键词:FasterViT;YOLOv8s;垃圾检测;目标识别
中图分类号:TP753 文献标识码:A
文章编号:1009-3044(2025)06-0060-04 开放科学(资源服务)标识码(OSID):
0 引言
据统计全世界每年产生大约40亿吨垃圾,中国每年产生的垃圾总量约为2.5亿吨,每年以8%~10%的速度增长[1]。城市生活垃圾累积堆存量已达70亿吨,垃圾存放占地累积达75万余亩。当前我国垃圾处理方式包括焚烧、填埋、堆肥等,如果垃圾在处理之前没有进行合理的分类则会造成环境污染、空气污染、土壤恶化等问题,因此垃圾分类与检测是一项必不可少的工作。现在随着智能化城市的建设进程加快,很多城市已开始建设智能化垃圾分类检测系统,利用人工智能等技术实现垃圾的精准分类检测[2]。
目标检测方法根据使用技术不同可分为传统方法与基于深度学习技术的目标检测方法。在传统方法中,在特征提取阶段大多使用尺度不变特征变换、哈尔特征、方向梯度直方图等方法来提取图像特征,在特征分类阶段使用支持向量机、决策树等方法对提取到的特征进行细粒度分类。传统目标检测方法在目标检测精度上表现较差,一方面受限于特征提取描述子对目标提取的特征较浅。另一方面受限于方法的泛化性较差,难以在复杂场景下准确地检测多个目标。并且存在对小目标检测效果不佳、缺乏生活场景下的真实垃圾数据集等问题。
最近随着深度学习理论尤其是卷积神经网络(Convolutional Neural Network,CNN)[3]的快速发展与应用,当前基于深度学习的目标检测方法在生活垃圾检测任务上已有很多研究与应用。石露露等人[4]在2023年提出一种改进YOLOv5s[5]的明渠漂浮垃圾实时检测方法,使用数据增强方法扩充Flow-Img数据集得到10 000张图像,在YOLOv5模型的特征融合阶段提出一种多尺度加权特征融合方法来提高模型对小目标的特征表达能力。郭洲等人[6]在2023年提出一种融合注意力机制的轻量化YOLOv4模型用于可回收垃圾检测,同时该方法提出在Neck模块中应用CBAM注意力模型来突出目标区域的显著度,更好地学习目标区域的特征。徐宏伟等人[7]在2024年提出一种轻量化湖面漂浮物实时检测方法C-X-YOLOv7,该方法将角点注意力模块CA(Coordinate attention)引入到YO⁃LOv7算法的骨干特征提取网络的最后一层,提高模型准确性和泛化能力。
之前提出的基于深度学习技术的垃圾检测方法均采取提出较早的目标检测算法如Faster RCNN、YO⁃LOv3、YOLOv4、YOLOv5等,最近YOLOv8[8]算法的提出为实现高精度实时目标检测任务提供了新的解决方案。同时注意到当前生活场景下的垃圾目标检测方法较少,大多方法都构建的是通用垃圾和水上垃圾数据集。为了填补这个空缺,本文首先构建了一种生活垃圾目标检测数据集,并基于最新的YOLOv8算法提出一种改进的目标检测算法FV-YOLOv8。为了增强特征提取模型对输入图像的特征提取与信息表达,本文使用FasterViT模型替换原始的卷积块,FasterViT 结合卷积层的快速局部表征学习与Vision Transformer 结构的全局特征建模实现图像特征的高效提取。最后在目标边框损失上使用WIoU Loss来挖掘更多的正样本,缩减预测框与真实框之间的距离,并通过不同角度的实验来验证FV-YOLOv8的效果与可行性。
1 YOLOv8
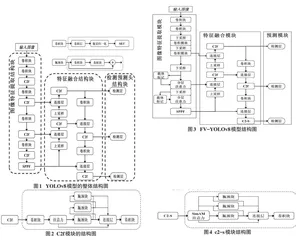
YOLOv8是YOLO(You Only Look Once)系列算法的第八代版本,它是基于YOLOv5和YOLOv7算法改进得到的,是新一代的基于CNN技术的单阶段高性能实时目标检测算法。与其他目标检测算法不同,YO⁃LO算法通过将目标检测任务转化为回归问题来提高图像的检测速度。在整体模型结构设计上,YOLOv8 可分为图像特征提取结构块、特征融合结构块以及检测预测头结构块,整体结构如图1所示。在图像特征提取结构块中,YOLOv8是由CBS和C2f这两个子模块组成,其中CBS模块由一个卷积层、一个批量归一化层以及一个SiLU激活函数组成;C2f模块由CBS、Bot⁃tleneck 以及concat 组件组成,其中Bottleneck 组件由两个卷积层以及一个残差连接块组成,这个结构是在YOLOv5中提出的,C2f模块的结构如图2所示。
2 FV-YOLOv8
虽然YOLOv8算法在目标检测精度与速度之间取得了一个极佳的平衡,整体结构精简高效,但全卷积的结构对图像的整体信息难以形成完整的表述,同时算法对小目标未做明显的优化。为了解决这两个问题,本文提出一种改进的YOLOv8算法FV-YOLOv8,并将其应用到生活垃圾目标检测任务中。本文使用FasterViT模型[9]来更优地提取图像特征,其有效结合CNN的快速局部表征学习与ViT的全局特征建模实现图像特征的高效提取;重新设计提出一种新颖的C2-S模块,使用无参注意力机制SimAM[10]增强感兴趣目标周围的上下文信息,抑制无效背景特征;在目标边框损失函数上,使用WIoU Loss更精确地计算预测框与真实框之间的位置偏差,使得模型对小尺寸目标的预测能够更精确。基于以上三点设计,本文提出的FV-YOLOv8算法能更好地提取图像特征、更突出地表征目标信息以及能更精确地预测小目标。FV-YO⁃LOv8的整体结构如图3所示。
2.1 FasterViT
FasterViT模块旨在更高效地处理高分辨率图像,通过有效结合CNN的快速局部表征学习与ViT的全局特征建模实现图像特征的高效提取,将具有二次复杂性的全局自注意力分解成计算成本更低的多层次注意力,能更充分地结合图像的全局信息与目标的局部特征,为后续的预测模块提供强有力的图像特征描述基础。
2.2 C2-S
注意力机制在CNN中扮演着越来越重要的角色,它能够帮助模型聚焦于图像的关键区域来提升性能。然而,现有的注意力机制通常需要引入额外的参数,增加模型复杂度和计算成本。SimAM是一种轻量级、无参数的卷积神经网络注意力机制,它通过计算特征图的局部自相似性来生成注意力权重。同时更重要的是其不需要引入任何额外的超参数与计算量,可即插即用模型任何位置。SimAM的核心思想是基于图像的局部自相似性。在图像中,相邻像素之间通常具有较强的相似性,而远距离像素之间的相似性则较弱。SimAM利用这一特性,通过计算特征图中每个像素与其相邻像素之间的相似性来生成注意力权重。
在特征融合模块,本文基于原始YOLOv8模型的C2f模块以及无参注意力SimAM提出一种全新的C2-S模块,输入特征图首先经过一个无参注意力机制Si⁃mAM来重点关注感兴趣目标区域特征,后续分为三个分支分别通过Bottleneck模块来融合图像的上下文特征,其中Bottleneck 模块是原始YOLOv8 使用的,C2-S模块的结构如图4所示。
2.3 WIoU Loss
在目标检测任务中,目标边框回归损失是必要且重要的,它能促使网络在训练阶段预测的结果输出与真实标签尽可能地接近,进而优化参数,在推理阶段能完成准确的目标位置预测。之前算法常使用IoULoss来衡量目标位置损失,但IoU Loss存在一些问题,如当两个预测框与真实目标框不重叠时则它们与真实目标的IoU均为零,此时IoU Loss的梯度为零且无法进行优化。此外注意到数据集中包含一些低质量的目标标注框,CIoU Loss使用的目标中心点距离、目标宽高纵横比之类的度量方法会加速损失对低质量标注目标的惩罚而影响模型的性能。而WIoU Loss会根据目标距离度量构建一种基于距离注意力的目标边框损失减免精度损失,WIoU Loss整体表达式如下:
本文在目标边框损失上使用WIoU Loss 替换掉YOLOv8使用的CIoU Loss,一方面降低计算量,另一方面WIoU Loss挖掘难样本,使模型在训练过程中能平稳地下降,关注到困难样本的优化,使得模型的检测准确率能进一步地提高。
3 实验与结果分析
3.1 数据集
本文实验的数据集包含目标检测基准数据集MSCOCO2017 版本以及自建的生活垃圾图像数据集。MS COCO2017数据集是微软在2017年发布的目标检测大型基准数据集,图像标注信息包含目标框、目标对象掩码、图像信息描述以及人体姿态关键点等。在目标检测任务上,MS COCO2017包含118 287张训练图片,验证集包含5 000张图片,测试集同样也包含5 000张图片。自建7类生活垃圾目标检测数据集包含电池(Battery)、砖瓦陶瓷(BrickAndTileCeramics)、不包含垃圾(No_Rubbish)、金属罐(Cans)、香烟(Ciga⁃rette)、食物垃圾(Food_waste)、塑料(Plastic)这7种目标,其中数据集的训练集和验证集分别包含7 319以及1 796张图像样本。部分生活垃圾数据集中的图片如图5所示。
3.2 实验设备与环境
YOLOv8与本文所提算法的开发语言都是Py⁃thon,使用开源的深度学习框架PyTorch来搭建模型与训练算法。本实验的硬件平台包含中央处理器为In⁃tel(R) Xeon(R) Platinum 8350C CPU @ 2.60GHz、图形处理器为单卡NVIDIA GeForce RTX 3090。本实验使用的Python版本为3.9,PyTorch框架版本为2.0.1,YO⁃LOv8的源码Ultralytics库版本为8.0.222,其他使用的一些重要库的信息如下:OpenCV 版本为4.6.0.66、NumPy版本为1.24.0、Matplotlib版本为3.6.2。
3.3 实验评价指标
当前用于目标检测任务的实验评价指标主要包括准确率(Precision)、召回率(Recall)、平均精度(Av⁃erage Precision,AP)、平均精度均值(mean Average Pre⁃cision,mAP)。Precision 和Recall 的计算方式分别如式(3)和式(4)所示。
3.4 实验结果分析
在MS COCO2017数据集上,本文复现得到的YO⁃LOv8s模型指标结果如下:模型在训练过程中,目标类别损失、边框损失以及DFL分别下降到0.893、0.964以及1.09。在验证集上,YOLOv8s模型的目标类别损失、边框损失以及DFL分别能下降到1.014、1.008以及1.105。在具体的精度结果指标上,YOLOv8s模型在Precision、Recall、mAP50 以及mAP50-95 这4 个指标上分别达到了67.6%、54.7%、59.9%以及43.9%。相较于其他同等参数量的单阶段方法,YOLOv8s模型在这4个指标上都有一定的提升。相较于其他的一些两阶段方法,YOLOv8s模型在训练时长、训练过程的稳定性以及推理时间上均表现出明显的优势。本文提出的FV-YOLOv8s在MS COCO上的训练过程和验证指标如图6 所示,在Precision、Recall、mAP50 以及mAP50-95 这4 个指标上分别达到了71.2%、57.2%、62.8%以及46.0%。相较于基准YOLOv8s模型分别提高了3.6%、2.5%、2.9%以及2.1%。