基于深度学习的海洋鱼类计数与测量技术研究
作者: 蓝淇婷 林基龙 邹立 林幸祥 林小龙 陈志辉
摘要:在水产养殖和生态监测等领域,鱼类计数和测量至关重要。然而,传统的人工计数方法效率低且复杂。为了克服这些问题,文章基于深度学习方法构建了鱼类计数与测量系统。首先,采用YOLOv5s算法搭建系统,并建立必要的实验环境。然后,从真实场景中采集了多组鱼类图像,构建了一个包含大量标注鱼类图像的数据集,用于模型的训练、验证及预测。最后进行实验和数据分析,结果显示,平均检测精度达到了95.18%,可实现鱼类的计数与测量。
关键词:深度学习;鱼类计数;鱼类测量
中图分类号:G424 文献标识码:A
文章编号:1009-3044(2025)07-0021-05
开放科学(资源服务) 标识码(OSID)
0 引言
鱼类资源在全球具有重要的经济和生态价值。然而,随着人口的增长和渔业活动的扩大,对鱼类资源的监测和管理变得愈发紧迫,同时准确了解鱼类数量和体表特征对于实现可持续的渔业管理和生态保护至关重要。传统的鱼类计数与测量方法,如简单的目视计数和物理测量,虽然能在一定程度上提供所需信息,但常伴随耗时和高成本,这限制了其应用范围。这些方法不仅效率低下,而且难以应对大规模、高频率的数据采集需求。目前,深度学习技术在目标检测、模式识别、目标分割等领域展现出了强大的性能,其能够从大规模的图像数据中学习鱼类的特征表示和空间分布模式,从而实现自动化的识别、计数和测量。如2017年Li[1]等人提出的基于R-CNN的检测计数方法,计算速度快、成本低、体积小,能够快速准确地处理海量数据,为科学研究和渔业管理提供更多有价值的信息。
本文设计了一种基于深度学习的鱼类计数与测量方法,实现高效、准确的鱼类资源监测。该系统有望为渔业管理、生态保护和生态学研究等领域提供有力支持。
1 相关研究
利用视频图像进行鱼类计数的研究,其历史可追溯至1995年Newbury[2]等人的开创性工作。在该研究中,Newbury等首次运用人工神经网络中的反向传播网络结构进行鱼类计数,并成功实现了准确率超过90%的精确计数,该研究为鱼类计数的后续研究提供了重要参考。
目标检测算法通常可以划分为两大类:传统机器学习方法和深度学习方法。在传统机器学习方法中,目标检测模型通常经历三个主要阶段,包括区域选择、特征提取和目标分类。然而,这些传统方法在性能和速度方面通常表现不佳。相比之下,基于深度学习的目标检测算法可以分为以下三类:首先是基于区域的方法,例如R-CNN (Region-based Convolutional Neural Networks)[3]和Fast R-CNN[4]。其次是基于回归的方法,如YOLO[5]和SSD[6],这些方法通过回归预测目标的位置和类别。最后是基于搜索的方法,其中包括基于视觉注意的AttentionNet[7]以及基于强化学习的技术[8]等。
近年来,深度学习技术在计算机视觉领域取得了突出进展。例如,Ahsan Jalal[9]等人采用了一种创新的方法,将光流和高斯混合模型与YOLO深度神经网络相结合,以解决YOLO在某些情境下的精度不足问题,利用光流和高斯混合模型来处理感兴趣区(ROI),从而提高了目标检测的准确性。另一方面,Sung[10]等人运用YOLO进行了鱼类检测和分类任务。他们在大规模的数据集上对YOLO进行了训练,并在测试集上获得了卓越的93%鱼类分类准确性。类似地,Xu和Matzner等人[11]也采用YOLO来检测不同数据集中的鱼类实例,并在mean average precision方面取得了53.92%的表现。尽管上述研究成功应用YOLO,但未考虑水下样本的不均衡性及小目标问题。此外,它们的网络结构缺乏像两阶段框架那样的感兴趣区域(ROI)提取和多尺度特征信息融合结构,在真实水下物体检测方面精度不高。为解决该问题,Labao等人[12]提出了一种基于R-CNN的多级对象检测网络,采用了两个区域提议网络(RPN) 和多个CNN组的顺序连接,通过联合训练来提高性能。类似地,Li等人改进了Faster R-CNN结构,提出了适用于水下鱼类目标检测的轻量级R-CNN,其检测率达到了89.95%。Salman等人[13]提出了一种基于R-CNN网络的自动鱼类检测和定位方法。然而,这些基于R-CNN网络的方法需要事先提取多个候选区域对应的图像,这会占用大量磁盘空间。此外,它们的主干网络输出特征信息的尺寸有限,对于多尺度目标或小目标的检测精度较低。同时还涌现出一系列新的目标检测算法,如NAS-FPN、EfficientDet以及YOLOF等[14]。
在目标计数上,Hong[15]等人提出了一个改进的掩码区域卷积神经网络(Mask R-CNN) 模型,根据水下生物的聚集程度分为低密度、中密度和高密度三种,利用所改进的掩码区域卷积神经网络(Mask R-CNN) 模型得到高准确率的计数。而Yu[16]等人提出了一种基于多模块注意力机制(MAN) 的深度学习网络模型来实现养殖鱼类的计数,能够在密集计数过程中更准确地识别图像的关键信息。这些新算法为目标检测领域带来了创新,丰富了检测方法的选择和应用,为解决鱼类数量估计与身体特征测量的难题提供了新的机遇。
2 YOLOv5模型框架
2.1 YOLOv5神经网络架构
YOLOv5是一种端到端的单阶段检测模型,该模型采用单一卷积神经网络对整个图像进行分割,同时预测边界框和每个网格的类别,从而在快速检测图像的同时保持高准确性。基于模型的深度和宽度递减,可以分为五种参数量不同的模型,分别是YOLOv5n、YOLOv5s、YOLOv5m、YOLOv5l和YOLOv5x。这些模型的结构基本相同,唯一不同的是depth_multiple参数和width_multiple参数。为了在实时性和准确性中保持良好平衡,本研究选择了YOLOv5s模型进行鱼类检测。
2.2 YOLOv5s算法
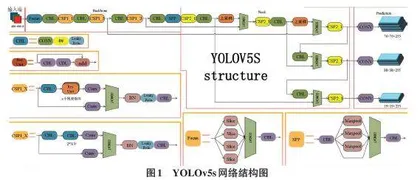
YOLOv5s的网络架构主要由4个组件组成,包括输入端(Input) 、骨干网络(Backbone) 、颈部网络(Neck) 和输出端(Head) 。如图1所示,这些组件构成了网络结构。
2.2.1 Input
在Input部分,基于Mosaic对鱼类数据集进行了数据增广。Mosaic数据增广将原本的2张图像拼接成4张图像,并进行随机的缩放、裁剪和排列操作。该方法的主要目的是提升模型对不同尺度目标检测的能力。传统的Mosaic数据增广仅使用两张图像进行拼接,而新的YOLOv5采用4张图像进行拼接,从而增加了数据的多样性。这种方法有助于模型更好地处理小、中、大目标的数据,提高了目标检测的鲁棒性和性能。其主要步骤如图2所示。
2.2.2 Backbone
在YOLOv5s中,Backbone(骨干网络) 引入了称为Focus模块和CSP模块的结构。Focus模块用于在进入骨干网络(Backbone) 前处理图像信息。具体操作包括将输入图像进行切片操作,将图像中的每隔一个像素的值提取出来,类似于邻近下采样的操作。这样,一张输入图像被切割成了4张图像,这4张图像相互补充,各自内容相似且没有信息丢失。切片操作可以将输入图像的宽度(W) 和高度(H) 信息转化为通道维度,同时扩充输入通道的数量。原本的RGB三通道图像被变换成了包含12个通道的图像。之后经过一次卷积操作,这些新图像最终被转化成了不损失信息的二倍下采样特征图。
在YOLOv5s中,原始的640×640×3的图像输入通过Focus结构经过切片操作,首先变成了320×320×12的特征图,然后经过一次卷积操作,最终得到了320×320×32的特征图。这种Focus模块的设计有助于将图像的空间信息和通道信息有效地融合,提高了网络的性能和表示能力。Focus切片操作如图3所示。
在YOLOv5中,已经设计了2种CSP(Cross-Stage Partial) 结构。在YOLOv5s中,CSP1_X结构被应用于骨干网络(Backbone) ,而CSP2_X结构被应用于颈部网络(Neck) 。在CSP1_X结构中,卷积核大小为3×3,步长为2,经过5次卷积运算。该设计的主要目的是解决由于增加网络深度而引发的梯度消失问题,同时也有助于减轻模型的计算和内存负担。
当输入图像尺寸为1 080×1 080×3时,经过CSP1_X结构的处理后,最终输出的特征图的尺寸为38×38。引入这些CSP结构的目标是提升网络性能和特征表示能力,同时降低深度网络的计算成本。CSP结构的示意图如图4所示。
2.2.3 Neck
在YOLOv5的Neck部分,主要采用了PANet(Path Aggregation Network) 结构。PANet是在Feature Pyramid Network(FPN) 的基础上进行了改进,用于提取网络内的特征层次结构。在FPN中,顶部信息流需要通过骨干网络逐层地向下传递,由于层数相对较多,这导致计算量较大。PANet通过引入一个自底向上(Bottom-up) 的路径来改进这一情况。
它首先进行自顶向下(Top-down) 的特征融合,然后再进行自底向上(Bottom-up) 的特征融合。这种方法有助于传递底层位置信息到深层,从而增强了多个尺度上的目标定位能力。如图5所示的结构中,FPN层负责自顶向下传递强语义特征,而PAN塔则负责自底向上传递定位特征。这种结构的引入有助于提高模型在多个尺度上的性能,同时更好地结合语义信息和位置信息。
图5(a) 部分为特征金字塔网络FPN(Feature Pyramid Network) 。这是一个在卷积神经网络中广泛使用的结构,旨在通过融合不同尺度的特征信息,增强网络对多尺度目标的检测能力。FPN Backbone提供了丰富的特征表示,这些特征可以在后续的处理步骤中进一步利用。
图中的(b)部分为下采样路径增强(Bottom-up path augmentation) ,指的是在类似特征金字塔网络(FPN) 的结构中,下采样路径增强用于融合不同尺度的特征信息。这有助于网络捕获不同大小的目标,从而提高检测性能。
图中的(c)部分为自适应特征池化(Adaptive feature pooling) ,指的是在图像分类任务中,通常需要将特征图池化为一个固定大小的向量,以便可以将其输入到全连接层或分类器中。
图中的(d)部分为框分支(Box branch) ,指的是在目标检测任务中,框分支通常负责预测目标的位置(即边界框) 。它可能会输出一系列坐标值,这些坐标值定义了图像中潜在目标的位置和大小。
图中的(e)部分为完全融合,指的是将多个路径或分支的输出结合起来,形成一个更强大、更多样化的特征表示,这有助于提高模型的准确性和鲁棒性。
2.2.4 Head
YOLOv5的Head部分包含了损失函数(Bounding box) 和非极大值抑制(NMS) 。损失函数采用了GIoU算法,相对于传统的IoU算法,该指标进行了改进和扩展,有效地提升了目标检测性能,如式(1)。
[GIoU=IoU-Ac-UAc] (1)
式中,[Ac]为最小闭包区,[U]为预测框和真实框的并集。类似于IoU,GIoU也是一种距离度量。IoU的取值范围在[0,1]之间,而GIoU的取值范围在[-1,1]之间。与IoU不同的是,GIoU不仅考虑了两个区域的重叠部分,还关注了它们之间的非重叠区域,因此可以更全面地反映它们的重叠程度。GIoU在重叠完全相等时取最大值1,在两者完全不重叠且无限远时取最小值-1,因此它被认为是一种很有价值的距离度量指标。