基于知识融合的藏语安多方言数据增强方法
作者: 钱木吉 仁增多杰 拉毛吉
摘要:针对藏语安多方言数据稀缺的问题,文章提出一种基于知识融合的数据增强方法。该方法首先分析安多方言词汇特征,将其分为8种实体特征和5种非实体特征,并构建了藏语辞藻、敬语和反义词词典。然后,利用Tibetan-Llama2模型进行风格迁移,将藏语书面语转换为安多方言。最后,结合安多方言语法特征,对生成的方言文本进行多特征融合扩充。实验结果表明,该方法将源语料扩充了6.67倍,生成的数据兼具多样性和可读性,为藏语安多方言数据增强提供了一种有效的解决方案。
关键词:藏语;安多方言;数据增强;知识融合;风格迁移;低资源语言
中图分类号:TP18 文献标识码:A
文章编号:1009-3044(2025)07-0050-06
开放科学(资源服务) 标识码(OSID)
0 引言
低资源自然语言处理(NLP) 任务中,数据稀缺性是一项重大挑战。藏语作为一种低资源语言,其方言数据的匮乏尤为突出,制约了机器翻译、语音识别等技术的有效应用。数据增强技术为解决这一问题提供了有效途径。不同于图像处理中常用的旋转、裁剪等方法,文本数据增强需要考虑语言的语法结构和语义含义[1-7]。
藏语是我国重要的低资源语种之一,属于汉藏语系藏缅语族藏语支,主要分布在我国西藏自治区、云南、青海、四川、甘肃等五个省区。方言是全民共同语的地方变体,由语言的分化与融合,即语言变异和相互影响等因素形成。方言之间主要在语音、词汇和语法方面存在差异。根据20世纪50年代的藏语普查及随后的重点深入补充调查,我国境内的藏语被划分为卫藏方言、康巴方言和安多方言。然而,格桑居冕等[8-13]人从语言学的角度深入研究了藏语三大方言的语音、词汇与语法特征。因此,在进行藏语方言数据增强时,需要考虑不同方言之间的差异,以确保增强后的数据对藏语三大方言都具有代表性和覆盖性。
在藏语书面语数据增强领域中,赵小兵等[14]人采用数据增强方法扩充公开的SICK藏汉平行语料,扩充21万句对时,藏汉改写检测模型的皮尔森系数达到0.547 6,比基线系统的皮尔森系数提升了0.397 1。蔡子龙等[15]人提出低频词的同义词替换,在Transformer实验中BLEU值最高提升了0.61,在XLM-R实验中BLEU值最高提升了0.58。通过三种不同的回译方法构建藏汉伪平行语料库,三种不同的回译方法对于Transformer和XLM-R实验的性能提升效果不同。传统回译方法在提升BLEU值方面效果不明显,而交替训练的回译方法在Transformer实验中的BLEU值最高提升了1.57,在XLM-R实验中的BLEU值最高提升了1.44。迭代回译方法在Transformer实验中的BLEU值最高提升了1.38,在XLM-R实验中的BLEU值最高提升了1.17。汪超等[16]人提出一种面向神经机器翻译的最小翻译单元调换以得到新的平行句对的数据增强方法,在藏汉、汉英两种语言对上进行实验,BLEU值提高了4个点。张瑞等[17] 人使用词向量扩充情感词词典的方法,通过实验对比,在藏文新闻文本情感分析方面,SVM+词向量+词典方法训练模型得到了较好的效果,为后续藏文文本的数据增强奠定了基础。
尽管藏语文本数据增强取得了一定发展,但大多是针对藏语书面语文本进行数据增强,鲜少有研究者探讨对藏语方言文本进行数据增强。针对上述问题,本文提出一种基于知识融合的数据增强方法。该方法首先分析安多方言词汇特征,然后利用Tibetan-Llama2模型进行风格迁移,将藏语书面语转换为安多方言。最后,结合安多方言语法特征,对生成的方言文本进行多特征融合扩充,为藏语安多方言数据增强提供了一种有效的解决方案。
1 安多方言特点
安多方言分布在甘肃省甘南藏族自治州、天祝藏族自治州、青海省海南藏族自治州、海北藏族自治州、海西蒙古族藏族哈萨克族自治州、黄南藏族自治州、果洛藏族自治州和四川阿坝藏族羌族自治州。多数地区从事牧业生产,也有不少地区是农业区或半农半牧区。根据语言学家的研究,以下将探讨以夏河话为主的藏语安多方言变体的词汇和语法特点。
1.1 词汇特点
藏语方言文本与书面语文本的最明显区别体现在两者的用词层面。书面语文本中使用的词基本上都能在全藏区理解,具有很好的通用性。但方言文本中的词则没有那么强的通用性,甚至很多词在不同方言下出现完全看不懂的情况。
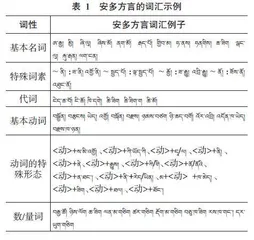
安多方言在名词、代词、形容词、动词、数词、量词、副词和助词等方面与书面语有许多区别。安多方言的名词除了基础名词外(如“ཨ་རྒྱ། མྱི། ཟོག ཞི་ལུ། ནག་མོ། གྱིབ་མ།”等) ,还有带有特殊词素“ནི”“སྤྱད་པོ”等的名词(如“ནི:ཟ་ནི། འགྱོ་ནི། སྤྱད་པོ།:ལྟ་སྤྱད་པོ། ཟ་སྤྱད་པོ། ཉན་སྤྱད་པོ།”等) ;代词的复数形式也有显著差异,如使用“ཆ་ག”或“ཆ་བོ”来表达复数;形容词方面,安多方言常见双重语尾的形容词,如“རིང་ང་བོ།”和“བཟང་ང་བོ།”。动词则有特殊的形态变化,例如表示否定、疑问、现在时或猜测等情况下的不同后缀(如“表示否定的谓语动词加‘ས་མི་འགྱོ’,表示疑问的谓语动词加‘རྒྱུས’,表示现在时的谓语动词加‘ཀི་ཡོད་ཀི’,表示猜测的谓语动词加‘ན་ཐང’”) ;在数词和量词方面,虽然与书面语相比没有太大的差别,但在特定物品的计数和度量方式上可能有所不同(如“ཉིས་ལོག ཆ་ཟིག ཐེངས་མ་གཅིག”) ;副词方面,安多方言的使用也与书面语有明显差异(如“དུ་ར།(དེ་ཙམ། ད་རུང་།(ད་དུང་། ད་ཆིས།(ད་ཅི་ལྟ་བུ།”) ;最后,助词在安多方言中的使用也有显著区别,特别是在疑问语气助词(如“ཆེ།(ཅིའི་ཕྱིར། ཡིན་ནས། རེད་ནས། ཨི་རེད། འགྱོ་རེ། འགྱོ་ཀོ།”等) 和命令语气的助词(如“ཤོག་ར། ལྟོས་ར། ཉོན་ཨ། ཤོད་ཨ”等) ,使用的形式和频率有所不同。安多方言的词汇特征具体见表1。
1.2 语法特点
藏语安多方言文本除了在用词方面与书面语有差别外,其语法上也有许多不同点。这些不同点主要体现在词语的复数形式、动词的时态变化、复合谓语的连接助词、语尾疑问助词、命令语气助词、语尾助词以及格助词的使用等方面。具体示例见表2。
2 藏语安多方言知识库构建
2.1 藏语安多方言词汇特征库构建
名词在语言中扮演着多种角色,涵盖人名、地名、时间名和组织结构名等多个类别。缺乏细分和准确替换可能导致与相应的形容词、动词和量词用法不匹配,进而影响语言的准确性和清晰度。例如,在句子“བཀྲ་ཤིས་གི་ཆུང་མ་བླངས།”(扎西娶了老婆) 中,若将人名“བཀྲ་ཤིས”替换为地名“པེ་ཅིང”,则生成的句子“པེ་ཅིང་གི་ཆུང་མ་བླངས།”(北京娶了老婆) 明显失去了原意。适当的名词细分和精准的用法不仅能确保语言表达的精确性,避免因语法不当而造成的歧义,还能更有效地捕捉藏语安多方言文本中的关键信息,并生成具有上下文连贯性的同义词性替换。
基于命名实体识别(NER) 技术的相关理论,本文将安多方言的词汇特点分为实体特征和非实体特征两大类。实体特征是指具体实体词在词性上所体现出来的特性,非实体特征是指非实体词在词性上所体现出来的特性,这些特性能够反映文本中词汇的使用模式和蕴含的语义信息。其中,实体特征包括交通、人名、人称代词、动物名、地名、时间名、民族名和组织结构等八种类别,这些类别对应于NER中的命名实体类型,有助于系统识别和分类文本中的重要信息;非实体特征则包括叹词、计数词、序数词、指示代词和疑问代词等五种类别,这些元素在语言表达中起到补充和修饰的作用。这样的分类为进一步的研究提供了基础,有助于深入理解安多方言的语言结构和使用规律,同时为应用于自然语言处理领域提供了理论支持。具体见表3与表4。
本文构建特征库时考虑了藏语的语法结构和用词规范等问题。例如,藏语的一条句子中动词大部分为其中心词,因此在数据增强时通过直接替换动词可能会导致动词用法不当的情况。例如,将“ང་ཟ་མ་ཟ་གི་ཡིན།”(我要吃饭。) 中的动词“ཟ”(吃) 替换为同义词“དགོད”(笑) ,结果为“ང་ཟ་མ་དགོད་གི་ཡིན།”(我要笑饭。) ,这显然不符合语法。量词在藏语中用法固定,替换量词也会导致量词混用。例如,将“རས་ཐ་ན་བཞི།”(四疋布) 中的量词“ཐ་ན”(疋) 替换为“ཐུན”(顿) ,结果为“རས་ཐུན་བཞི།”(四顿布) ,同样不符合规范。因此,构建特征库时需要特别注意这些动词和量词的问题。
2.2 词典构建
辞藻词典的数据主要来源于传统的藏文口诀和经典文献。这些口诀通常包含丰富的藻饰词汇,用于修饰和美化核心关键词。为了构建辞藻词典,需要收集并整理这些口诀,确保它们的准确性和代表性。
本文参考《辞藻学选编》(仁青措和康主才让,2012年民族出版) 对口诀进行收集和整理后,对每个口诀进行了细致分析,并提取出其核心关键词。关键词是口诀中表达的主要概念或对象,代表了口诀的核心思想。在关键词提取完成后,进一步识别与其相关的藻饰词。藻饰词通常是修饰性词汇、短语或句子,用以增强关键词的表达效果。接着,将这些藻饰词按照与关键词的关联程度进行分类和整理。最终,构建出结构化的表格数据。表格中,每一行对应一个关键词,第一列为关键词本身,后续列为与之相关的藻饰词。表格设计注重数据的准确性和清晰性,以便于查阅和使用。具体见表5。
敬语的数据也主要来源于传统的藏文口诀。本文参考《藏语敬语童谣》(旦杰,2010年西藏人民出版社) 对口诀进行收集和整理后,通过分析口诀中的敬语表达,识别出普通敬语和最高敬语等不同程度的敬语形式。将敬语按照其程度和用法进行分类和整理。
根据敬语的分类和用法,构建敬语词典的映射关系。这可以是一对多的映射关系(即一个关键词对应多个敬语形式) ,也可以是一对一的映射关系(即一个关键词对应一个特定的敬语形式) 。具体见图1和图2。
通过参考《藏语文反义词词典》(索朗确吉编著,2023年民族出版社) 、《藏汉对照拉萨口语词典》(于道泉,1983年民族出版社) 、《安多藏语口语词典》(耿显宗等,2007年甘肃民族出版社) 以及《藏语康方言词汇集(第一册) 》(邓戈,2020年西藏人民出版社) ,收集已有的反义词词典和口语词典,并对这些词典进行整理和合并,以确保词典的准确性和完整性。
将反义词对与口语词典进行对比,并将反义词调整为口语化的表达形式。这有助于提高反义词词典的实用性和适用性。具体见表6。
3 藏语安多方言数据增强方法
本文方言数据来源于藏语方言研究的书籍及刘颖等人①开发的藏语方言时空数据共享服务平台,最初统计出801条数据。经过筛选,丢弃了短于五个字和长于三十字的句子,以及没有特别明显的方言特征的句子。最终筛选出的安多方言数据有727条,主要内容为日常对话,构建的安多方言语料命名为TF_An。
此外,从藏文小说、新闻和微博评论中收集了1 299条书面语数据,并将其作为基础,构建书面语与安多方言的平行语料,命名为TS_m。借助分词词性标注工具[18]对最终句子进行分词及词性标注,并进行人工校对,以确保原始语料的准确性与可靠性。
在模型选择方面,本实验采用了Tibetan-Llama2作为迁移学习的基础模型。Tibetan-Llama2是基于Llama2模型架构构建的,经过较大规模数据的增量预训练和指令微调,具备对藏文的深入理解和处理能力。在藏文理解和生成任务中表现出了较高的效率和性能,并且在多个领域都有广泛的应用前景。
3.1 数据预处理模块
在处理原始文本数据时,面临数据来源广泛且多样、噪声信息混杂等挑战。为了确保数据质量和后续分析的准确性,本文进行了全面而细致的预处理工作。