基于PCI级联模型的网购异常商品识别研究
作者: 张嘉洛 王扬华 罗舜崇 葛涛超 徐宇轩
摘要:随着电子商务的迅猛发展,准确识别异常商品对维护平台信誉和保护消费者权益至关重要。针对现有方法在处理高维数据和探测复杂异常模式方面的局限性,本文提出了一种基于PCA(主成分分析) 、COPOD(复合概率密度估计) 和IForest(孤立森林) 的PCI级联异常检测模型。该模型首先通过PCA对高维数据进行降维,使用COPOD进行初步异常检测以筛选潜在异常点,最后利用IForest精确识别最终异常点。实验结果表明,PCI模型的准确度达87.3%,召回率为77.8%,F1分数为0.823,显著优于传统方法。该研究表明,PCI级联模型能有效提高异常商品识别的准确性和可靠性,为电商平台的风险管理和运营优化提供了新技术方案。
关键词:主成分分析;复合概率密度估计;孤立森林;电子商务数据;异常检测
中图分类号:TP181 文献标识码:A
文章编号:1009-3044(2025)08-0037-05
开放科学(资源服务) 标识码(OSID)
0 引言
近年来,随着互联网技术的迅猛发展,电子商务平台已成为消费者购买商品的重要渠道。然而,中国消费者协会的网购调查发现,异常商品的存在不仅严重影响了消费者的购物体验,也给平台带来了经济损失[1]。异常商品形式多样,涵盖价格异常、销量异常、假冒伪劣和交易异常等。由于商品数据复杂且高维,这些异常商品难以辨别,亟需高效、准确的识别方法。
目前,国内外已有许多关于异常检测的研究成果。林正闻[2]提出基于统计学习的方法,利用历史数据构建模型来预测未来的趋势或模式,这种方法在一些特定的应用场景下能够提供较高的检测精度。但是,它在处理大规模数据时计算复杂度较高,而且如果实际的数据分布与模型假设的分布有较大差异,检测性能可能会显著下降。卢梦茹[3]提出基于局部密度的方法,通过计算数据点周围的局部密度来识别异常值,该方法对于处理具有不同密度区域的数据集非常有效。然而,在高维空间中,这种基于距离的方法容易遭受“维度灾难”的影响,即所有数据点之间的距离趋向于相等,从而降低检测的准确性。王楠[4]提出基于聚类的方法,能够自动发现数据中的自然分组,并据此识别出异常值。不过,这种方法对于特征之间复杂的相互作用考虑不足,可能遗漏一些重要的异常信息。董晴晴[5]提出LOF离群点挖掘方法,通过比较一个点与其邻域内其他点的局部密度来识别异常点,该方法在处理中等规模数据集时效果良好,但面对大规模数据集时效率较低。付文杰[6]提出基于决策树与局部密度结合的方法,虽能够有效地处理数值型和类别型特征,但对于文本等非结构化数据的支持有限,且在处理大规模数据集时的效率和可扩展性仍有待提高。
本文提出了一种基于PCA、COPOD和IForest的PCI级联异常检测模型。相比于其他机器学习模型,该模型更善于发掘异常之间的依赖关系和在多维度下的异常,具有逐步细化、减少误报、高灵活性、强适应性和良好可解释性的优势。实验结果表明,该模型能有效提高异常商品识别的准确性。
1 理论基础
1.1 主成分分析(PCA)
主成分分析(Principal Component Analysis, PCA) 是一种常用的降维技术,通过线性变换将原始高维数据投影到低维空间,同时保留数据的主要信息。在本研究中,PCA主要用于处理电商平台复杂的多维商品数据,具体流程如下:
步骤1:数据标准化,对原始数据进行标准化处理,使各特征具有相同的尺度。
步骤2:求协方差矩阵,计算标准化后的数据的协方差矩阵。
步骤3:计算特征值和特征向量,求解协方差矩阵的特征值和特征向量。
步骤4:通过观察累计方差解释比例曲线,使用拐点法确定主成分数量。选择特征值最大的前几个特征向量作为主成分,这些主成分代表了数据的主要方向。
步骤5:投影,将原始数据投影到主成分空间中。
1.2 复合概率密度估计(COPOD)
复合概率密度估计(Copula-based Outlier Detection, COPOD) 是一种利用Copula函数建模特征之间依赖关系的异常检测算法,通过计算数据点在Copula函数中的概率密度来识别异常点。本研究中,COPOD用于初步筛选在多个特征维度上表现出异常依赖关系的商品,具体流程如下。
步骤1:数据清洗,去除缺失值和异常值。
步骤2:数据标准化,对数值特征进行归一化处理,使各特征具有相同的尺度。
步骤3:计算边际分布,对每个特征变量[Xi]估计其边际分布[Fi(xi)]。
步骤4:使用边际分布将每个变量[Xi]变换到[0, 1]区间上的均匀分布[Ui]。即对于每个观测值[Xij],计算其在边际分布下的累积概率[uij=Fi(xij)]。
步骤5:构建高斯Copula函数[c(u1,j,u2,j,....,ud,j)],计算联合概率密度,使用Copula函数建模特征之间的依赖关系。
步骤6:计算异常分数,通过Copula函数计算每个数据点的异常分数。异常分数表示数据点在Copula函数中的概率密度。
步骤7:根据联合概率密度值的分布,设定一个阈值,该阈值用于区分正常点和潜在的异常点。
1.3 孤立森林(Isolation Forest)
孤立森林(Isolation Forest) 是一种基于决策树的异常检测算法,通过随机分割特征空间,异常点通常比正常点更容易被孤立。在本研究中,孤立森林主要用于识别出那些在多个特征维度上表现异常的商品,具体流程如下:
步骤1:构建孤立树,通过随机选择特征和特征值进行二分裂来构建孤立树。每棵树的目标是将数据点尽可能快地隔离。
步骤2:计算路径长度,对于每个样本,计算其在每棵孤立树中的路径长度,即从根节点到叶节点的边数。异常点通常比正常点更容易被隔离,因此路径长度较短。
步骤3:确定异常分数,用计算出的平均路径长度确定待测数据的异常分数。
步骤4:判定异常与否,最终的异常分数是所有孤立树的平均值,若异常分数大于或等于异常阈值,则判断为异常数据,否则判为正常数据。
2 建模分析与评价指标
2.1 PCI级联模型的构建
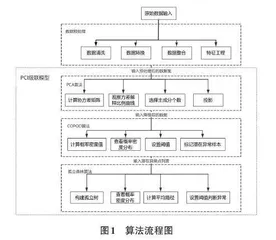
PCI级联模型融合了PCA、COPOD和IForest三种方法。首先,使用PCA对高维数据进行降维,以保留主要信息并降低计算复杂度。接着,利用COPOD对降维后的数据进行初步异常检测,筛选潜在异常点。最后,使用IForest进一步确认这些异常点,精确识别最终的异常商品。具体的算法流程如下:
步骤1:对数据集X进行预处理,初步筛选与异常检测相关的特征,进行编码,并对数据进行标准化和归一化处理。
步骤2:计算数据集的协方差矩阵,以捕捉各个特征之间的相关性。计算协方差矩阵的特征值和特征向量,通过观察累计方差解释比例曲线的拐点位置,选择前k个主成分,保留数据的主要信息。
步骤3:将原始数据投影到选定的主成分上,得到降维后的数据。
步骤4:对COPOD模型输入降维后的数据,计算每个样本的概率密度值。根据概率密度值的分布,设定阈值,将概率密度值低于阈值的样本标记为潜在的异常点。
步骤5:对潜在的异常点列表进行标准化处理。
步骤6:使用IForest进行精炼检测,随机选择特征和特征值,构建孤立树,通过递归分割将数据点隔离,直到每个数据点被单独隔离。对于每个样本,计算其在每棵孤立树中的路径长度,并根据路径长度设置阈值。将路径长度低于阈值的样本标记为最终的异常点。
2.2 关键参数选择
使用网格搜索(Grid Search) 遍历所有参数组合,如表1所示。对于COPOD模型,由于其用于初步筛选,估计异常点占比较高,因此设置较高的污染率参数。对于孤立森林(Isolation Forest) 算法中树的数量的确定,根据其提出者Liu等人[7]的建议,树的数量取值应在100和500之间。取值过小可能导致算法不稳定,而取值过大则会浪费计算机资源。因此,建议将树的数量设置在100到500之间,步长为50。
通过查看F1分数、AUC-ROC和交叉验证评估每个组合的性能,选择最佳的参数配置。最终,将最佳参数应用于模型,进行异常检测和评估,确保模型的准确性和鲁棒性。
2.3 评价指标
本研究采用以下评价指标对模型进行评估,以分析和对比模型的性能提升。
1) 混淆矩阵:混淆矩阵是评估分类模型性能的重要工具,特别是在二分类任务中。混淆矩阵通过展示模型的预测结果与实际结果之间的对比,帮助计算各种评价指标,如表2所示。
2) 精确度(Precision) :预测为正类(异常) 的样本中,真正正类(异常) 的比例,使用式(1) 进行计算。
[Precision=TPTP+FP] (1)
3) 召回率(Recall) :所有真实正类(异常) 中,被正确预测为正类(异常) 的比例,使用式(2) 进行计算。
[Recall=TPTP+FN] (2)
4) F1分数(F1 Score) :精确度和召回率的调和平均值,用于综合评估模型的性能,使用式(3) 进行计算:
[F1 Score=2×Precision×RecallPrecision+Recall] (3)
3 异常商品识别
3.1 数据预处理与特征工程
本研究以某电商平台2021年6月至9月“手机数码”类目下的1 486 873条商品数据为研究对象,商品数据共有21个字段(主要字段为:商品价格、商品销量) ,按照月份字段区分,店铺数据和商品数据之间通过USER_ID字段进行关联。
3.1.1 数据清洗
本研究选取了2021年6月至9月期间,一级类目为“手机数码”的交易记录作为实验数据。该数据集共包含1 486 873条记录。数据清洗过程如下:
1) 去重:针对不同月份的数据,对“商品名”和“商品ID”进行去重处理。
2) 删除空值:删除“商品名”为空的数据,删除“商品价格”为空的数据,删除“店铺ID”为空的数据,删除“店铺名称”为空的数据。
3) 填充空值:对“商品月销量”“商品月销售额”“收藏数”“评论数”这四个数值特征的空值进行填充。若该项商品在其他月份只有两个月份数据,则取平均值填充;若该项商品在其他月份有三个月份的数据,则取中位数进行填充;若无其他月份数据,则填充值为0。对“一级类目”“二级类目”“三级类目”“四级类目”“五级类目”这五个类别特征的空值进行填充,统一填充为“其他商品”。
3.1.2 数据编码及文本分析
对于一级、二级、三级、四级和五级类目类别数量不多的情况,采用标签编码方式。商品类别特征与目标变量高度相关,因此对商品ID进行目标编码。使用GloVe的glove.6B.zip进行词嵌入,维数选择为200维。
3.1.3 特征工程
本研究对数据集在选择用于算法模型检测的字段时,为了保留时序特征和重要特征,帮助识别动态变化,需要设计衍生字段,如表3所示。
3.2 数据探索性分析
通过各种统计和可视化方法,深入了解数据的结构、特征和潜在模式,从而为后续的建模和分析提供坚实的基础[8]。随机抽取40万条数据,以大致了解其数据分布情况。由于价格差异较大,直接观察难以发现规律,因此部分图示使用IQR方法暂时过滤商品价格和商品销量字段中的异常值,以确保后续分析的准确性,其他类别与月份数据采取类似方式进行。