分布式计算在大数据分析中的应用与挑战研究
作者: 隗泽凯 李白玉
摘要:该研究探讨分布式计算在大数据分析中的应用。通过构建分布式计算集群,采用Hadoop和Spark框架对大规模数据进行处理,提出基于Spark的并行挖掘算法,并通过实验验证其正确性和可靠性。结果表明,该算法在扩展性与容错性上表现良好,为数据挖掘和机器学习提供了新机遇。
关键词:分布式计算;大数据分析;Hadoop平台;并行挖掘算法;容错性
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2025)08-0074-03
开放科学(资源服务) 标识码(OSID)
0 引言
在数字化转型时代,数据的爆炸式增长给各行业带来了前所未有的机遇与挑战。大数据的概念不仅限于传统的结构化数据,更多的非结构化和半结构化数据也纷纷涌现。这些数据的特征包括体量大、速度快、种类多和真实性高等,使得传统的数据处理和分析方法面临巨大挑战。分布式计算指的是将计算任务分散到多个计算节点上进行并行处理[1]。因此,深入研究分布式计算的机制与方法,探索其在大数据分析中的应用,显得极为必要。
1 分布式计算分析
在大数据分析方面,许多公司和机构已经开始使用分布式计算工具,如Apache Hadoop平台和Apache Spark计算引擎等,这些工具不仅支持在大规模数据集上进行复杂的数据处理任务[2]。在这个背景下,本节将对Hadoop生态系统和Spark计算引擎进行详细介绍。
1.1 Apache Hadoop平台
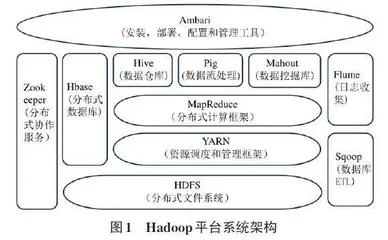
系统作为一种高效的分布式系统计算平台,被广泛应用于解决大规模数据存储和复杂分析计算问题[3]。其核心组成部分涵盖Hadoop分布式文件系统(Hadoop Distributed File System,HDFS) 、MapReduce编程模型以及分布式资源管理框架(Yet Another Resource Negotiator,YARN) [4]。其系统架构如图1所示。
大数据分析采用传统的主从架构(master/slave) ,如图2所示,其中包括一个主节点(NameNode) 和多个从节点(DataNode) 。这种设计旨在实现高可靠性和可伸缩性,特别适用于大规模数据的存储和处理。NameNode的主要任务包括维护文件系统的目录树、跟踪文件的块分布情况、处理客户端的文件系统操作请求以及管理数据块的复制和故障恢复 [5]。DataNode负责存储实际的数据块,管理它们所在节点上的存储设备,并根据主节点的指示执行数据的读取和写入操作。每个数据节点负责存储和维护数据块的多个副本,以提高容错性和数据可靠性。
1.2 Spark计算引擎
Spark是一个专为处理大数据而设计的通用并行计算架构,共包含Spark Core、Spark SQL、Spark Streaming、Spark MLlib以及Spark GraphX等多个模块。每个模块都针对不同领域的数据处理和分析需求。Spark Core作为核心模块,主要实现分布式任务调度、内存管理和错误修复等重要功能。Spark的核心组件如图3所示。
Spark通过使用弹性分布式数据集(Resilient Distributed Datasets,RDD) 、广播变量以及累加器这三种数据结构来实现高并发和高吞吐的数据处理操作。RDD作为Spark的核心数据处理模型,具有将数据分区并存储在集群不同节点的能力,并且这些数据一经创建即不可更改。Spark对RDD的操作主要包括转换和行动两类,这些操作可以通过SparkCore提供的转换算子和行动算子实现。转换操作是根据数据处理逻辑,将旧RDD转换为新RDD,同时构建出清晰的血缘关系。这一特性在RDD的容错和恢复机制中发挥着重要作用。值得一提的是,RDD的转换操作具有延迟执行的特点,即只有在执行到RDD行动算子时,才会触发实际的计算过程。
2 基于Spark的大数据分布式计算并行挖掘算法
针对数据库的大数据分析挖掘算法所存在的MapReduce分布式计算模型较差等问题,提出基于Spark的并行挖掘(SFUPM-SP) 算法。该算法通过构建逻辑搜索树结构,高效地遍历所有项集,避免重复或遗漏计算项集,以便实施剪枝策略。
2.1 逻辑搜索树
一般来说,在挖掘过程中,传统的单机算法多依赖于列表和投影等数据结构来遍历项集。然而,这些传统的数据结构在某些情况下展现出其固有的局限性,具体如下。
1) 内存限制:传统列表和投影结构因需要将数据完整加载至内存,可能导致内存溢出,影响系统性能列表和投影结构。
2) 性能效率限制:列表在进行频繁的元素插入或删除操作时,效率可能会受到影响,这主要是由于需要调整内部元素的顺序以维护数据结构的一致性,导致操作的时间复杂度增加。
3) 分布式处理的限制:在大规模数据处理中,分布式系统变得至关重要。分布式系统可以将数据集分割成小块并在多个计算节点上并行处理。。
2.2 并行算法SFUPM-SP设计
SFUPM-SP算法是一种利用Spark框架实现的分布式运行算法。在算法初始阶段,原始数据集被划分为数据块并存储在HDFS中。随后,通过Spark Core提供的应用程序编程接口(Application Programming Interface,API) 将这些数据块转化为初始RDD。然后,算法利用转换和行动两种算子对数据进行处理,同时执行RDD的转换操作,以满足特定的计算需求。
1) 输入部分:SFUPM-SP算法要求输入一个存储于分布式文件系统HDFS中的公开事务数据库[Dp]以及一个与之相对应的利润表。
2) 预处理阶段:在该阶段,首先使用SparkContext对象所提供的textFile方法从HDFS路径中读取数据集,并进行分区存储,创建初始HDFS-RDD。接下来,通过Spark提供的flatMap算子对每一行进行操作,提取出每个项的名称、事务效用和效用,构建一个包含三元组的ListBuffer。随后,利用reduceByKey算子对具有相同键的元素进行归约,通过累加操作得到相同键的总和、数量和总数。然后,使用map算子将归约后的结果映射为一个新的RDD,包含项集、频率和事务加权效用三项。
3) 挖掘阶段:在本阶段,算法要计算每个项集的效用、频率、子树效用和局部效用,并将结果输出到HDFS中。这个阶段涵盖两个剪枝策略的使用。整个过程是迭代进行的,直到不再生成候选集,迭代才会终止。在每次迭代中,从迭代文件中提取项集并使用数组进行判断,将符合条件的项集放入潜在的天际线频繁-效用模式池中。最终,从池中生成频繁-效用模式。
3 实验和算法评估
本节将通过对比实验来验证和分析所提出的SFUPM-SP算法的计算性能,并将其与SFUI-UF算法以及SFUP-MR算法进行对比。SFUI-UF算法是目前最先进的挖掘天际线频繁-效用模式的单机算法,它利用效用列表等结构对天际线模式进行挖掘,并从频率、TWU和效用本身三个角度对效用进行过滤。SFUP-MR算法是基于MapReduce框架的天际线频繁-效用模式并行挖掘算法。
3.1 实验环境和数据集
SFUPM-SP算法是采用Scala语言开发的,而SFUP-MR算法和SFUI-UF算法则都是使用Java语言编写的。本实验构建一个由5台主机组成的集群系统,这些机器通过局域网交换机实现互联。在集群中,一台主机作为主节点,负责监控和调配集群的运作;其余四台主机则作为工作节点,协同合作以处理分布式并行计算任务。为了更好地模拟真实的应用环境,实验选择在SparkonYARN中使用yarn-cluster模式进行Spark程序的部署。这种部署模式允许Spark与YARN资源管理器进行集成,以确保集群高效协同工作。本实验共选取真实数据集和合成数据集两种类型的数据集。数据集的主要特征如表1所示。
3.2 实验结果分析
如图4所示,横坐标选取四个值(30M、80M、130M、180M) 作为中等规模数据集的大小。实验结果表明,在大部分数据集上,单机算法的运行时间仍然短于两个并行算法。然而,在Mushroom数据集的规模为180M时,单机算法出现“内存溢出”的现象。这主要是因为海量数据导致程序试图分配的内存超过系统的可用物理内存限制。处理如此大规模的数据集,特别是在资源有限的单机环境中,可能会使系统无法有效地管理和存储所有的数据,最终导致内存溢出。
4 结论
本研究通过系统的理论分析和实证研究,揭示分布式计算在大数据分析中的重要作用及应用前景。通过探索不仅为大数据分析领域的研究和实践提供新思路和方法,也为分布式计算技术在实际应用中的推广和应用提供有益的参考和借鉴。
参考文献:
[1] 周佳佳,文英,杨光辉,等.基于分布式计算总线的计费系统实践[J].电信工程技术与标准化,2024,37(8):74-78.
[2] 秦静,高月玖.智能边缘计算与无线通信融合的关键技术与应用[J].数字通信世界,2024(7):104-106.
[3] 史超,蔡源浩,陈超,等.基于MPI、MapReduce和OpenMP混合编程的高分三号数据分布式并行转换算法[J].科技资讯,2024,22(13):17-20.
[4] 盛建军.一种基于分布式计算的网络空间拓扑描绘方法[J].桂林航天工业学院学报,2024,29(3):433-438,445.
[5] 袁泽文,周国成,周胜洁,等.分布式存储与计算方法在水利地理空间大数据中的应用[J].测绘与空间地理信息,2024,47(7):10-13.
【通联编辑:梁书】