网络协议栈优化与数据传输效率提升研究
作者: 王启宇
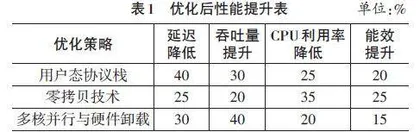
摘要:传统网络协议栈的分层设计虽具通用性,但在复杂网络环境下存在延迟高、吞吐量低、能效不足等问题。文章围绕用户态协议栈、零拷贝技术、多核并行处理和硬件卸载等优化策略,系统分析了网络协议栈的优化路径,并提出了适用于不同网络场景的解决方案。结合实验验证,结果表明,这些优化措施可将传输延迟降低约40%,吞吐率提升约35%,资源利用效率提高约25%,为工业生产和信息化场景提供了可靠的理论依据与实践路径。
关键词:网络协议栈优化;用户态协议栈;零拷贝;多核并行;硬件卸载
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2025)08-0080-03
开放科学(资源服务) 标识码(OSID)
0 引言
随着网络流量的增长和复杂度的提升,传统网络协议栈在传输效率和资源利用方面面临瓶颈。尽管分层设计具有通用性,但频繁的上下文切换、数据拷贝冗余和硬件资源利用不足的问题使其难以满足高性能网络需求,尤其在高带宽、低延迟场景中表现出延迟高、吞吐量低和能效不足的缺陷。
为解决上述问题,用户态协议栈、零拷贝技术、多核并行处理和硬件卸载等优化策略应运而生。这些技术通过减少处理开销、优化传输路径和提升硬件资源利用效率,为网络性能的提升提供了有效解决方案。本文基于对传统协议栈局限性的分析,探讨多种优化策略的应用路径,结合实验数据验证其在延迟、吞吐量和资源效率等关键性能指标上的提升效果,明确各策略的适用场景,为构建高效的数据传输体系提供理论支持和实践指导。
1 网络协议栈的现状与瓶颈分析
1.1 网络协议栈的层次结构
传统TCP/IP协议栈通过分层设计,将复杂的网络通信任务划分为多个相对独立的功能模块,具体分为应用层、传输层、网络层、链路层和物理层。应用层负责为用户提供交互功能与数据服务,常用协议包括HTTP、FTP等;传输层的核心功能是保障数据的可靠传输,常见协议有TCP和UDP,分别用于面向连接的传输和无连接的快速传输;网络层通过IP协议实现数据包的路由选择与转发,负责网络范围内的地址解析;链路层承担数据帧的封装、错误检测与纠正任务;物理层则直接负责与硬件媒介的交互,包括信号传输和物理连接[1]。这种分层设计在提供灵活性、模块化管理和标准化协议接口方面具有显著优势。然而,各层之间的处理需要多次上下文切换和冗余数据拷贝,导致性能损耗。为了量化这种性能影响,数据传输效率模型为:
[Ttotal=Tprocessing+Ttransminssion+Tqueuing] (1)
式中:[Tprocessing]表示协议各层的数据处理时间,受封装与解封装过程影响;[Ttransminssion]表示网络中的数据传输时间,依赖链路带宽与延迟;[Tqueuing]为数据在发送与接收队列中的排队时间。
1.2 现有瓶颈
1) 处理延迟问题。传统网络协议栈的分层结构在模块化管理和灵活性方面具有优势,但各层间的独立处理流程需要多次上下文切换和数据拷贝。这些操作显著增加了处理开销,导致CPU负载过高,成为影响协议栈响应速度的主要瓶颈。在高流量场景中,协议栈的整体处理效率下降,难以满足实时性要求[2]。
2) 吞吐量限制问题。传统协议栈通常采用单线程模式处理数据流,难以充分利用多核处理器的计算能力和硬件加速技术(如RDMA和智能网卡) 。这种局限性在高带宽网络中尤为明显,数据处理能力难以匹配硬件性能,形成吞吐量瓶颈,限制了网络资源的充分利用[3]。
3) 能效问题。协议栈运行过程中频繁调用内核资源,在高负载情况下导致CPU占用率显著上升,同时对硬件资源的优化支持不足,使得能耗居高不下。这种低能效表现不仅与现代绿色网络建设的需求相背离,也进一步限制了传统协议栈的应用范围和适应性。
2 网络协议栈优化策略
2.1 用户态协议栈优化
用户态协议栈的核心优化策略是通过绕过内核操作,将网络数据包的处理直接移至用户空间,以避免频繁的上下文切换和系统调用开销。传统协议栈需要在内核态和用户态之间多次切换,造成显著的性能损耗,尤其在高并发场景中更为明显。用户态协议栈通过直接操作网络设备和专用的用户态驱动,将处理路径从内核态迁移至用户态,从而减少系统调用和内存拷贝次数,显著提升数据传输效率。用户态协议栈的处理性能可以建模为:
[Tueserprocesing=LN⋅f+α] (2)
式中:[L]为数据包长度;[N]为并行核心数量;[f]为单核处理能力;[α]为协议处理的固定开销。通过增大并行核心数[N]和优化单核处理能力[f],用户态协议栈有效降低了协议处理时间 [Tueserprocesing]。相关研究表明,基于DPDK(Data Plane Development Kit) 实现的用户态协议栈在高带宽网络环境中可将延迟降低约40%,吞吐量提升30%以上[4]。此外,轻量化用户态协议(如VPP) 在高并发和低延迟场景中广泛应用,为工业和科研领域提供了高效的解决方案。
2.2 零拷贝技术
零拷贝技术的优化策略以减少数据拷贝操作为核心,从根本上降低了CPU和内存的资源消耗。传统协议栈需要在内核态和用户态之间多次数据拷贝,这种冗余操作在处理大规模数据传输时成为性能瓶颈。零拷贝通过直接内存映射(mmap) 和数据地址引用,实现了数据从磁盘到网络设备的高效传输,而无需经过用户态。传输过程中系统资源的消耗公式为:
[Rtotal=β⋅DB+γ⋅MT] (3)
其中:[D]为传输的数据量;[B]为网络带宽;[β]为带宽利用率;[M]为内存映射次数;[T]为传输时间;[γ]为单次内存映射的固定资源开销。零拷贝技术通过减少[M]和优化[β],显著降低了总资源消耗 [Rtotal]。该策略广泛应用于大数据量传输场景,如视频流媒体和文件分发等,通过简化数据流转路径,使网络处理更加高效。未来实验将重点探讨其在不同传输数据量和网络配置中的适用性。
2.3 多核并行与硬件卸载
多核并行和硬件卸载优化策略结合了多核处理能力与硬件加速的优势,通过分布式处理和任务卸载,有效提高协议栈性能。多核并行通过负载均衡算法将数据包分发至多个核心,最大化利用多核处理器的并行能力;硬件卸载则依赖于智能网卡(如RDMA) 和加速设备(如FPGA、ASIC) ,将加密、校验等计算密集型任务转移至专用硬件模块执行。多核并行和硬件卸载的吞吐能力公式为:
[T=i=1n(k⋅Pcore)+δ⋅Phardware] (4)
其中:[n]为处理核心数量;[Pcore]为单核的处理能力;[k]为负载均衡效率;[Phardware]为硬件模块的处理能力;[δ]为硬件卸载对系统性能的贡献比例。优化策略主要集中在提升核心负载均衡效率[k]和增强硬件模块性能 [Phardware]。此外,通过调整多核分配和优化硬件处理路径,能够实现更高的吞吐量和更低的延迟。
2.4 协议定制化与轻量化
协议定制化与轻量化优化策略以场景化适配为核心,通过简化协议结构和精确匹配传输需求,提升协议的效率和资源利用率[5]。定制化协议通常针对特定应用场景(如流媒体或物联网) 优化传输路径,去除不必要的功能模块,减少传输延迟。轻量化协议则通过降低协议复杂度和资源消耗,在资源受限场景中提供可靠通信。协议性能的优化公式为:
[Eprotocol=η⋅TthroughputTlatency⋅Ccesource] (5)
式中:[Tthroughput]为协议的吞吐量;[Tlatency]为传输延迟;[Ccesource]为资源消耗;[η]为协议与场景适配的系数。通过提升[η]和[Tthroughput],同时降低[Tlatency]和[Ccesource],协议效率得到全面提升。
3 数据传输效率提升方法
3.1 快速重传与拥塞控制优化
拥塞控制是影响网络数据传输效率的核心因素。传统TCP协议的拥塞控制机制(如Reno或CUBIC) 通过监测丢包或延迟来调整窗口大小,但在高带宽低延迟的网络中,这些机制难以充分发挥传输潜力。改进算法BBR(Bottleneck Bandwidth and Round-trip Propagation Time) 通过实时测量网络瓶颈带宽和往返时延(RTT) ,基于带宽估计和速率调整优化传输效率。与传统算法不同,BBR依赖于速率控制而非丢包判断,从而减少了网络资源浪费,提高了带宽利用率。
快速重传机制作为拥塞控制的补充,通过提前确认丢包并立即重传减少传输中断。结合快速重传和BBR算法的优化方案,可实现更高的带宽利用率和更低的传输延迟,特别适用于视频流媒体、分布式存储等需要稳定高效传输的场景。例如,在高性能计算网络中,BBR结合Selective Acknowledgment(SACK) 可显著提升TCP的传输效率。
3.2 数据路径优化
数据路径优化的目标是减少传输链路中的中间环节,降低协议开销并提升整体效率。传统协议栈由于多次封装和解封装增加了延迟,而复杂的路径设计则导致不必要的网络跳数。优化路径的核心方法包括:1) 通过引入直连技术或调整拓扑结构,减少中间节点的数量;2) 采用批处理技术,将多个数据包合并为单个批次以减少传输启动开销;3) 结合基于缓存的路径优化策略,避免重复传输和路径冗余。
具体实现中,批处理优化可通过GRO(Generic Receive Offload) 技术减少内核态的包处理次数,而路径调整结合网络拓扑分析算法(如最短路径优先算法,Shortest Path First) 可显著降低链路延迟和资源消耗。这些方法已在内容分发网络(CDN) 和高效文件传输场景中广泛应用。
3.3 智能流量调度
智能流量调度通过结合机器学习技术,对网络流量进行实时预测和动态优化分配,以提升网络的适应性和效率。与传统依赖静态规则的流量调度不同,智能调度利用深度学习模型(如LSTM和Transformer) 预测流量波动趋势,结合网络状态实现资源分配的动态调整。流量调度的优化过程最小化损失函数为:
[L(θ)=i=1n(yi-f(xi,θ))2] (6)
式中:[yi]为真实流量需求;[f(xi,θ)]为模型输出流量预测值;[θ]为模型参数;[n]为训练样本数量。通过优化损失函数[L(θ)],模型可动态调整流量分配,提升调度准确性。
4 实验与性能评估
4.1 实验环境与指标设计
1) 实验平台。为了验证网络协议栈优化策略的有效性,本研究设计了一个高性能实验平台。硬件配置包括:多核高性能处理器(Intel Xeon Platinum 8260,24核48线程,主频2.4GHz) ;高速网卡(Intel XL710,支持40Gbps带宽) ;支持RDMA(远程直接内存访问) 的智能网卡(Mellanox ConnectX-6) ;128GB DDR4内存,以及2TB NVMe SSD用于数据存储。软件环境选择了基于Linux的优化内核(Kernel 5.15) ,并结合DPDK(Data Plane Development Kit) 作为用户态协议栈的实现框架。
2) 数据流量模拟。本研究采用专业的流量生成工具模拟多种数据流模式,模拟的流量涵盖以下方面:第一,不同大小的数据包,从小型的64字节控制包到典型的1 500字节大型数据包,充分反映协议栈对不同传输规模的适应能力;第二,不同流量速率,从低负载环境下的轻量级通信到高负载情况下的大规模数据流量传输,测试优化策略在带宽占用率不同情况下的稳定性和效率;第三,流量分布的多样性,包括均匀分布的流量模式和突发性分布场景,评估优化策略在处理流量波动时的灵活性与响应能力。