融合DDQN与示教学习的高超声速飞行器智能姿态控制方法研究
作者: 刘静文 蔡光斌 凡永华 樊红东 吴彤 尚逸鸣
摘 要: 为提高高超声速飞行器姿态控制问题的求解速度和精度, 提出了一种结合示教学习的高超声速飞行器智能姿态控制方法。 首先, 建立了高超声速飞行器的控制模型, 选取姿态角动作作为控制输出。 其次, 设计了一种结合DDQN(Double Deep Q-Network)和示教学习的算法, 将智能体的训练分为预训练和正式训练两个阶段。 在预训练阶段, 智能体从演示数据中抽取小批量数据, 应用四种损失函数进行神经网络更新。 在正式训练阶段, 从飞行器自身训练生成的数据和演示数据中进行采样, 并通过优先经验回放控制每个小批次中两种类型数据的比例, 在与环境的交互中学习, 使飞行器能够根据飞行环境变化自适应地调节姿态。 仿真结果表明, 基于演示数据的强化学习方法能够跟踪控制指令, 实现高超声速飞行器的姿态控制, 并且能够提高神经网络训练初期的表现, 具有更高的平均奖励。
关键词: 高超声速飞行器; 姿态控制; 强化学习; 示教学习; DDQN
中图分类号: TJ765; V249
文献标识码: A
文章编号: 1673-5048(2024)06-0050-07
DOI: 10.12132/ISSN.1673-5048.2024.0130
0 引 言
高超声速飞行器一般是指飞行马赫数大于5, 在临近空间内实现大范围、 远距离快速机动的飞行器, 具有飞行速度快、 飞行航程远、 飞行空域大、 机动突防能力强等诸多优势[1-3]。 高超声速飞行器将大幅拓展战场空间、 提升突防与打击能力, 已成为大国空天军事竞争的又一战略制高点, 具有重大军事意义[4]。 由于高超声速飞行器本身具有强耦合、 强非线性、 强不确定性的特点, 同时飞行环境中存在各种外界干扰, 飞行高度和马赫数跨度范围大、 飞行环境复杂、 气动特性变化剧烈、 飞行约束条件多, 对高超声速飞行器的姿态控制系统提出了较高的要求。 为了满足强稳定、 高精度的控制要求, 飞行控制方法的设计需要具备快速性、 精确性与鲁棒性, 如何设计满足控制要求的高超声速飞行器姿态控制方法是研究的热点。
目前已有许多方法被应用于高超声速飞行器姿态控制领域, 如增益调度控制[5]、 反步控制[6]、 滑模控制[7]、 鲁棒控制[8]等。 针对高超声速飞行器的三维航迹控制问题, 杨庶等[9]采用线性变参数输出反馈控制和极点配置理论, 设计了高超声速飞行器一体化式控制律, 对飞行器纵向和横向运动进行综合控制; 针对非仿射高超声速飞行器的姿态控制问题, 路遥等[10]提出一种基于反步法的非线性控制方法, 设计扩张状态观测器, 基于动态逆的方法设计了升降襟副翼的控制律; Sagliano等[11]提出基于反馈线性化的高阶滑模控制, 在消除抖振的同时, 提升了控制器的抗干扰能力; Ren等[12]针对面向控制模型的非最小相位特性和系统不确定性, 将高超声速飞行器的鲁棒跟踪问题分解为一个较为简单的带干扰的线性非最小相位系统的鲁棒跟踪问题和一个无干扰的非线性系统的稳定问题, 设计了一种基于非线性补偿的高超声速飞行器鲁棒跟踪控制器。
传统的高超声速飞行器控制方法为了达到良好的效果, 需要根据系统状态设计相应的控制器参数。 由于高超声速飞行器精确模型获取困难, 飞行环境复杂, 飞行控制器的参数设计非常繁琐。 此外, 参数设计往往依赖于工程师的经验和能力。 因此, 迫切需要一种不依赖工程师能力和经验的控制参数设计方法。 近年来, 强化学习算法在飞行器控制领域优势逐渐突显。 强化学习算法可以在系统状态和控制器参数之间建立直接联系, 通过将大量数据离线训练出的控制策略加载到飞行器上在线运用, 能够实现更好的控制效果。 基于武器智能化的发展趋势, 王冠等[13]提出一种基于事件触发的确定学习控制方案, 将飞行器动力学模型划分为速度子系统和高度子系统, 基于离线学习获取的动态知识设计了在线触发控制器; 魏毅寅等[14]利用深度神经网络对飞行器关键特征进行辨识, 实现了控制增益的精准调度, 提升了在模型不确定性情况下飞行器的自适应能力; Zhao等[15]提出一种基于观测器的强化学习控制方法, 构造高超声速飞行器复合观测器, 综合观测器提供的信息, 设计了一种强化学习控制器来解决最优姿态跟踪控制问题; Wang等[16]设计了双行为者批评网络及其自适应权值更新规律, 对未知的、 不匹配的和匹配的外部扰动进行补偿, 解决了具有扰动的高超声速飞行器的输出约束非仿射姿态控制问题。
强化学习算法已经在飞行器控制领域取得了广泛的应用, 但经典强化学习仍存在一定的局限性, 如在高维空间中表现不佳、 样本效率低、 训练不稳定等[17]。 DQfD(Deep Q-learning from Demonstrations)作为一种结合示教学习和自我生成数据的算法, 在训练初期利用专家演示数据, 随后结合自我探索数据, 成功地克服了许多传统算法的不足, 提高了模型训练的初期表现和训练效率[18]。 目前基于演示数据的强化学习算法已应用到了无人机控制领域, etin等[19]提出一种带有对抗网络架构的DQfD算法, 加快了无人机反制系统的训练速度; 孙丹等[20]设计了示教知识辅助的无人机控制算法, 相较于其他强化学习算法在控制效果和收敛性方面都有着明显的优势。 在当前人工智能不断发展的背景下, 为进一步强化高超声速武器相较于传统武器的效能优势, 将智能化技术应用于高超声速武器装备已经成为新的发展趋势。
针对高超声速飞行器姿态智能控制算法训练前期训练效率低的问题, 本文结合DDQN算法和示教学习, 设计了一种DDQNfD(Double Deep Q-Network from Demonstrations)高超声速飞行器姿态控制方法, 利用示教学习的优势提升高超声速飞行器算法前期的控制策略求解效率。 将智能体的训练分为预训练和正式训练两个阶段, 训练智能体基于飞行器模型和演示数据, 采用神经网络来近似逼近奖励函数的方式, 通过获得最大奖励值的方法学习姿态控制策略, 实现对俯仰角的自适应调节, 降低了系统的不确定性对控制效果的影响和控制器设计对模型的依赖程度。
1 高超声速飞行器姿态控制模型
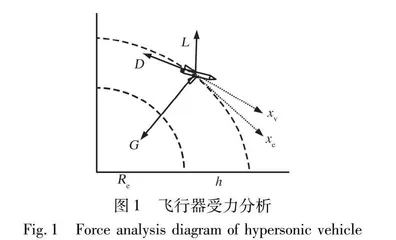
将地球看作一个质量均匀的圆球, 忽略地球扁率和地球自转的影响, 基于上述假设, 对高超声速飞行器的受力分析如图1所示。
高超声速飞行器俯仰力学模型描述为
x·=vcosψReRe+h
h·=vsinψ
v·=-Dm-gsinψ
ψ·=Lmv+cosvRe+h-gv
ω·z=MzIz=f(α, ωz, Mz)+bδe
φ·=ωz
α=φ-ψ (1)
式中: v为飞行器速度; ψ为弹道倾角; α为攻角; φ为俯仰角; ωz为俯仰角速度; x为飞行距离; h为飞行高度; m为飞行器质量; b为常数系数; Mz为俯仰力矩; Iz为俯仰转动惯量; Re为地球半径; g为重力加速度。
升降舵舵机的动力学方程表示为
Ge(s)=δeδeu(s)=9 608s2+176.45s+9 608(2)
式中: δe为舵偏角; δeu为升降舵机的驱动电压。
俯仰力矩表达式为
Mz=mzq-SLc
mz=mz0+2mzδe+mzzωzLc2v (3)
式中: S为面积; q-=0.5ρV2为动压; Lc为纵向参考长度; mz, mzδe, mzz为迎角、 马赫数、 舵机的函数。 D为阻力, L为升力, 其计算表达式如下:
L=q-SCLD=q-SCD (4)
式中: CL, CD分别为飞行器升力系数和阻力系数。
2 控制算法设计
本文的控制目标是采用智能控制的方法, 通过对飞行器升降舵机驱动电压的自适应调整, 实现对目标俯仰角的跟踪。 控制器设计基于示教学习与强化学习结合的方法, 训练智能体根据飞行器自身训练生成的数据和演示数据中进行神经网络参数更新, 并通过优先经验回放自动调节两种数据的比例, 通过环境交互进行俯仰角控制策略的学习, 让飞行器能够自适应地调节姿态, 实现对姿态控制指令的快速响应。
2.1 DDQN算法
强化学习是机器学习的分支, 智能体通过与环境的不断交互、 感知, 学习从状态到动作的映射关系, 根据反馈的环境信息获得奖励值, 不断更新神经网络参数。 强化学习的训练过程如图2所示。
飞行器姿态控制策略训练过程中, 智能体在环境中感知到当前的状态St, 然后在动作空间中选取执行的升降舵机驱动电压调节动作at, 通过控制飞行器与环境进行交互, 获取执行动作的奖励值rt+1, 通过与环境进行的交互所选取的动作所获得的奖励值来评价自主学习的行为, 并通过不断地调整自身的动作策略, 使飞行器在姿态调整的任意时间段内都能执行获得奖励最大的升降舵机电压调节动作。 训练过程就是一个与环境不断交互学习的过程, 目标是学习到适应环境的最优升降舵机电压自主调节策略。
DDQN算法是一种基于价值函数的深度强化学习算法, 通过与环境不断交互, 学习并训练出最优动作价值函数Q(st, at), 表示为
Q(st, at)=E(Rt+γ·Q(St+1, At+1))(5)
式中: E为期望; γ为折扣因子。 求解最优动作值函数是根据状态St+1, 选择动作At+1满足Q最大化,即
Q(St+1, At+1)=E[Rt+γ·maxaQ(St+1, a)](6)
对式(6)进行蒙特卡洛近似可表示为
E[Rt+γ·maxaQ(St+1, a)]≈rt+γ·maxaQ(St+1, a) (7)
式中: rt表示当前时刻获得的奖励; γ·maxaQ(St+1, a)为时序差分(Temporal Difference, TD)目标。 TD目标包括当前真实的奖励值和模型预测的奖励值, 通过不断更新, 使得Q接近TD目标。 迭代过程为
Q(st, at)←Q(st, at)+l[r+γ·
maxaQ(St+1, at+1)-Q(st, at)] (8)
式中: Q(st, at)表示t时刻, 状态St下对应动作at的价值; l为学习率; r为奖励。 利用DNN神经网络拟合一个函数代替Q值表对价值函数进行更新。 利用神经网络逼近函数时, 价值函数的更新采用梯度下降法更新神经网络中的参数θ:
θt+1=θt+l[r+γ·maxat+1Q(st+1, at+1, θt)-
Q(st, at, θt)]Q(st, at, θt)(9)
式中: r+γ·maxat+1Q(st+1, at+1, θt)-Q(st, at, θt)为TD目标; Q(st, at, θt)为当前状态的价值函数梯度。 算法的目标值表示为
YDoubleDQNt=Rt+1+γQ(St+1,argmaxa′Q(St+1, a′; θt), θ-)(10)
2.2 DDQNfD姿态控制算法设计