算力需求大爆炸
作者: 李赟
算力是数字经济发展的重要底座。随着AI与数字经济的发展,算力规模不断扩大,需求持续攀升。
4月5日,OpenAI停止了ChatGPT Plus的销售,官网中给出的理由为“由于需求量过大,我们暂停升级服务”。ChatGPT Plus是OpenAI提供的一项订阅服务,使用价格为20美元/月。订阅ChatGPT Plus服务的会员可享受三个福利:在高峰时代可以访问ChatGPT、更快速的响应以及优先访问新功能。
AI进入“大模型”时代。OpenAI自发布GPT1.0模型之后,一直在持续迭代,陆续发布GPT2.0、GPT3.0和GPT3.5,近期发布GPT4.0是其持续投入AI大模型的必然阶段。相比前几个模型,GPT-4的参数量更大,模型迭代时间更长,也能够给出更准确的结果。新版本的发布是大模型循序渐进发展的必然成果,未来大模型将成为AI开发范式。
东方证券认为,此次ChatGPT Plus停售事件是因为需求量过大,计算资源供不应求。AI浪潮来袭,智能算力需求将快速提升,AI芯片、AI服务器以及云计算算力需求将持续提升。ChatGPT的训练需要上万片英伟达的GPU。同时,在推理端,微软已经在Azure的六十多个数据中心中部署了几十万张GPU,为ChatGPT的超高访问量提供支持。然而,还是似乎因为计算资源供不应求导致此次ChatGPT Plus停售。
AI浪潮来袭,通用大模型的训练、行业大模型的训练、基于通用大模型的行业应用以及推理皆需要大量智能算力提供支持。AI芯片、AI服务器以及云计算算力需求将持续提升。
事实上,算力作为数字经济的核心生产力,已成为国民经济发展的重要基础设施,中国智能算力规模正在高速增长。
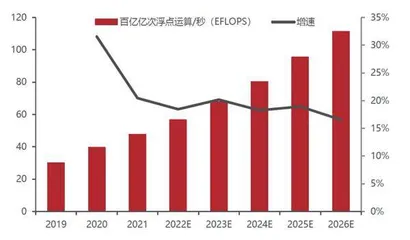
IDC预测,2022年中国智能算力规模将达到268.0 EFLOPS(每秒百亿亿次浮点运算),超过通用算力规模,预计到2026年智能算力规模将达到1271.4 EFLOPS。2021-2026年,预计中国智能算力规模年复合增长率达52.3%,同期通用算力规模年复合增长率为18.5%。华为更是预测,未来10年人工智能算力需求将会增长500倍以上!
未来算力网络一定会成为国家经济发展的一个新的基础设施,根据国家信息中心联合浪潮信息发布的《智能计算中心创新发展指南》显示,目前全国已有超过30个城市在建或筹建智算中心。近日,科技部也表态推动算力网建设,打造超算、智算的算力底座。日前,贵州省大数据发展管理局发布《关于印发面向全国的算力保障基地建设规划的通知》。从能力指标、质量指标、结构指标、通道指标、产业指标共5个维度提出未来三年的建设目标。5大指标均为爆发式扩张,其中机架规模从10.8万架提高到80万架,三年时间扩张达7倍;算力总规模从0.81 EFLOPS提高至10 EFLOPS,扩张超11倍。
同时,AI计算需要多元异构算力提供支持,将极大拉动GPGPU、AISC等AI芯片的需求。中国AI芯片市场规模有望快速增长,据艾瑞咨询预测2027年将达到2164亿元,国内相关企业坚持迭代升级,其产品性能日益提升,有望获得更多市场份额,实现国产替代。另外,随着大模型的成熟部署,对性能要求稍低的推理芯片的占比将日益提升,也有益于国产AI芯片占比提升。
“智能革命”的起点
回顾历史,人类社会目前经历了三次重大的产业变革:蒸汽时代、电气时代、信息时代,其分别对应了18世纪60年代末期英国人詹姆斯·瓦特制造的第一代具有实用价值的蒸汽机、美国在19世纪60年代实现了电力的广泛应用以及电灯被发明、1946年美国制造出人类第一台二进制计算机。每一次的产业革命都具有几个共通点,首先均有标志性的产品面世,其次持续时间较长以及对于世界发展影响深远。
如今,人类社会或已处在人工智能时代的临门一脚。2022年11月,ChatGPT的发布让世界看到了无限的可能性,这仅仅只是“智能革命”的起点,未来或将呈现出各行业各接纳人工智能,人工智能助推世界发展的景象。
自2022年11月底以来,美国初创公司OpenAI发布的人工智能对话聊天机器人软件(模型)ChatGPT迅速在社交媒体上走红,短短5天,注册用户数就超过100万,并在2个月内突破1亿,成为史上增长最快的消费类应用。
以ChatGPT为代表的AI大模型开启了新一轮生产力革新的科技浪潮,大模型展现出了理解人类语言的潜力,颠覆过去互联网发展中的许多业态,并对实体经济和产业发展产生深远的影响。也因此,GPT被微软创始人比尔·盖茨评价为自图形界面以来最重要的技术进步,被英伟达创始人黄仁勋称作是人工智能领域的iPhone时刻。
ChatGPT使得人与机器可以直接对话,机器能够理解人复杂的意图并能够做出恰当的反应,人与机器不再局限于简单的指令式交互,可以流利地与机器对话,进行复杂的交互。机器可以理解人复杂的意图,辅助人类干更多的工作,人类生产力将会大幅提高,个人AI时代即将到来。从历史经验来看,新一轮交互革命引发的浪潮高度与速度都会远超上一代,目前个人AI时代仍处于萌芽状态,未来给人类社会带来的改变不可估量。
同时,ChatGPT也引发了国内外大厂争相布局,海外方面微软、谷歌、亚马逊等大厂均采取投资或商用的方式与OpenAI保持紧密合作,国内方面腾讯、科大讯飞、京东等公司先后宣布与ChatGPT结合上线的业务线,百度、阿里巴巴、昆仑万维已发或筹备类ChatGPT产品。
国外方面,Meta于近日发布图像分割基础模型SAM(Segment Anything Model)。SAM模型能够在未经过同类数据训练的情况下,自动分割图像中的所有内容,自动根据提示词进行图像分割。
SAM的发布堪称图像识别行业的“GPT-3”时刻。国盛证券表示,图像识别与分割是当前许多智能化场景的基础。例如智能驾驶中就需要对摄像头呈现出的图像进行分割与识别,从而让车辆做出反应。医学影像诊断中需要对病变位置进行分割来进行判断。过去,图像分割往往只能通过对预先打包的数据进行训练,并针对海量的特定场景进行调优,效率和成本均不占优。此次Meta发布的SAM模型,能使得AI通过已有数据的训练,获得面对未知内容的自动识别能力。
国盛证券认为,可以把这个过程比作人类的视觉,人类所拥有看见新事物时自动处理并理解的能力。这将改变传统的图像识别训练模式,加快图像识别行业的发展。
图1:中国智能算力规模(EFLOPS)及预测
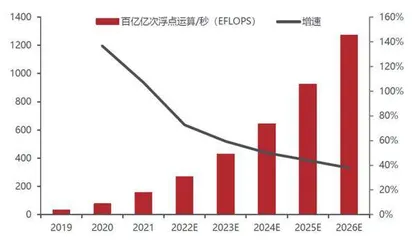
图2:中国通用算力规模(EFLOPS)预测
视觉大模型,算力要先行。相较于传统的图像识别解决方案,SAM更加偏向于LLM模型(大型语言模型)的模式,即通过海量的预先训练与扩大模型参数,来使得模型获得自主识别和学习能力,最终实现图像“AGI”。这类模式对于算力基础设施的需求程度远大于传统的小模型或者垂直模型,同时图像模型包含的数据量更大,训练过程中需要的计算能力,通信能力和存储能力相较于文字模型更多。因此,视觉大模型的前提是海量的算力基建,算力的重要性在LLM模式迈入图像领域时被再度提升。
国内方面,以百度为代表的科技公司主导国内AI基础生态是大势所趋。在这一生态下,一批基于大模型底座进行应用开发的公司将在文字、图像、音视频生成、数字人、3D生成等领域大显身手,“AI+”应用端有望呈现百花齐放。
4月10日,商汤科技发布“日日新”大模型体系,含自然语言生成、照片生成服务、感知模型预标注、模型研发。1800亿参数中文语言大模型应用平台“商量”支持超长文本知识理解,支持问答、理解与生成等中文语言能力。
而商汤科技下一代软件开发范式是AI for AI,代码=80% AI生成+20%人工。超10亿参数自研文生图生成模型“秒画”,支持二次元等多种生成风格。单卡A100支持,2秒生成1张512K分辨率的图片。用户可基于单卡A100自训练。基于平台发布的模型,可设置to B服务API(应用程序编程接口),结合商汤大算力对外提供服务。
数据、算力与算法是人工智能时代的三大基石,三者相互促进带动AI+应用快速落地,大语言模型在丰富的场景中带动AIGC类应用全面发展,开启了新一轮人工智能创新周期,将带动算力、服务器、通信等多领域的发展。
算力需求黄金时代
AI奇点的到来也将会成就算力领域的黄金时代。
算力是指计算机系统能够完成的计算任务量,通常用来描述计算机的处理能力。算力的单位通常采用FLOPS(Floating Point Operations Per Second)表示每秒钟能够完成的浮点运算或指令数。以英伟达在2020年发布的A100产品为例,根据英伟达官方介绍,A100的理论浮点运算性能可以达到19.5 TFLOPS,即每秒195万亿次浮点运算。
算力可分为通用算力、智能算力以及超算算力,对应着三种计算模式:基础计算、智能计算以及超级计算。不同的场景所需的算力种类不同,其对应的计算精度也不尽相同。
AI大模型是“大数据+大算力+强算法”结合的产物,凝聚了大数据内在精华的“隐式知识库”,希望逻辑结构能够自发地从模型的训练过程中涌现。AI大模型包含了“预训练”和“大模型”两层含义,即模型在大规模数据集上完成了预训练后形成特征和规则,无需或仅需要少量数据的微调,就能直接支撑各类应用。
人工智能实现方法之一为机器学习,而深度学习是用来实现机器学习的技术,通常可分为“训练”和“推理”两个阶段。训练阶段:需要基于大量的数据来调整和优化人工智能模型的参数,使模型的准确度达到预期,核心在于算力;推理阶段:训练结束后,建立的人工智能模型相可用于推理或预测待处理输入数据对应的输出(例如给定一张图片,识别该图片中的物体),这个过程为推理阶段,对单个任务的计算能力不及训练,但总计算量也相当可观。
比于传统AI算法,大模型在参数规模上得到大幅提升,参数一般达到千亿甚至万亿规模。例如OpenAI的GPT系列,最开始的GPT-1拥有1.17亿个参数,到GPT-3的参数已经到达1750亿个,而相应的能力也得到大幅提升。
GPT-3开启了大模型时代。GPT-3使用了大量的语料库进行预训练,使其能够理解语言的规则和模式,并生成与输入文本相关的自然语言文本,GPT-3的主要特点是它具有大规模的预训练模型,而同时大规模的训练模型与之对应的便是庞大的算力需求。
根据OpenAI团队成员2020年发表的论文《Language Models are Few-Shot Learners》,GPT-3模型拥有约1750亿个参数,这使得GPT-3拥有其他较少参考量模型来说更高的准确性。同时基于1750亿个参数的模型仅需少量的样本训练,就能够接近于BETR模型使用大量样本训练后的效果。